Организация
ЭВМ и систем
Лабораторная
работа ©4
Использование SIMD-расширений архитектуры x86
Цель: научиться использовать в программах на языке Си SIMD-расширения архитектуры x86.
SIMD-расширения архитектуры x86
SIMD-расширения (Single Instruction Multiple Data) были введены в архитектуру x86 с целью повышения скорости обработки
потоковых данных. Основная идея заключается в одновременной обработке
нескольких элементов данных за одну инструкцию.
Расширение MMX (Multimedia
Extension)
Первой SIMD-расширение в свой x86-процессор ввела фирма Intel - это расширение MMX. Оно стало использоваться в процессорах Pentium MMX (расширение архитектуры Pentium или P5) и Pentium II (расширение архитектуры Pentium Pro или P6). Расширение MMX работает с 64-битными регистрами MM0-MM7, физически расположенными на регистрах сопроцессора, и включает 57
новых инструкций для работы с ними. 64-битные регистры логически могут
представляться как одно 64-битное, два 32-битных, четыре 16-битных или восемь
8-битных упакованных целых.
Еще одна особенность технологии MMX - это арифметика с насыщением. При этом
переполнение не является циклическим, как обычно, а фиксируется минимальное или
максимальное значение. Например, для 8-битного беззнакового
целого x:
обычная
арифметика: x=254; x+=3; // результат x=1
арифметика
с насыщением: x=254; x+=3; // результат
x=255
Расширение 3DNow!
Технология 3DNow! была введена фирмой AMD в процессорах K6-2. Это была первая технология, выполняющая
потоковую обработку вещественных данных. Расширение работает с регистрами
64-битными MMX, которые
представляются как два 32-битных вещественных числа с одинарной точностью.
Система команд расширена 21 новой инструкцией, среди которых есть команда
выборки данных в кэш L1. В
процессорах Athlon и Duron набор инструкций 3DNow! был несколько дополнен новыми инструкциями
для работы с вещественными числами, а также инструкциями MMX и управления кэшированием.
Расширение SSE
(Streaming SIMD
Extension)
С процессором Intel Pentium III впервые появилось расширение SSE. Это расширение работает с независимым
блоком из восьми 128-битных регистров XMM0-XMM7. Каждый регистр XMM представляет собой четыре упакованных
32-битных вещественных числа с одинарной точностью. Команды блока XMM позволяют выполнять как векторные (над всеми
четырьмя значениями регистра), так и скалярные операции (только над одним самым
младшим значением). Кроме инструкций с блоком XMM в расширение SSE входят и дополнительные целочисленные
инструкции с регистрами MMX,
а также инструкции управления кэшированием.
Расширение SSE2
В процессоре Intel Pentium 4 набор инструкций получил очередное
расширение - SSE2. Оно позволяет
работать с 128-битными регистрами XMM как с парой упакованных 64-битных вещественных чисел двойной точности, а
также с упакованными целыми числами: 16 байт, 8 слов, 4 двойных слова или 2
учетверенных (64-битных) слова. Введены новые инструкции вещественной
арифметики двойной точности, инструкции целочисленной арифметики, 128-разрядные
для регистров XMM и
64-разрядные для регистров MMX. Ряд старых инструкций MMX распространили и на XMM (в 128-битном варианте). Кроме того, расширена поддержка управления
кэшированием и порядком исполнения операций с памятью.
Расширения SSE3, SSSE3, SSE4, ...
В последующих процессорах Intel и AMD происходит дальнейшее расширение системы
команд на регистрах MMX и XMM. Добавлены новые команды для ускорения
обработки видео, текстовых данных. Особенно следует отметить появившуюся возможность
горизонтальной работы с регистрами (выполнение операций с элементами одного
вектора).
Расширение AVX (Advanced Vector Extensions)
В процессорах архитектуры Sandy Bridge от Intel и процессорах архитектуры Bulldozer от AMD векторные расширения сделали следующий
большой шаг в развитии. Новые векторные регистры YMM0-YMM15 теперь имеют размер 256 бит. Регистры XMM будут использовать младшую часть новых регистров. Среди особенностей
нового векторного расширения есть поддержка трехоперандных
операций вида (c = a OP b), а также менее строгие требования к
выравниванию векторных данных в памяти.
Использование SIMD-расширений при написании
программ
Использование векторных расширений может дать
значительный прирост производительности, поэтому стремление их использовать
является вполне оправданным. Существует несколько способов, позволяющих реализовать
возможности имеющихся SIMD-расширений
в программах языках высокого уровня:
1)
Воспользоваться
знаниями компилятора.
Оптимизирующий
компилятор, умеющий генерировать код для данного SIMD- расширения - это наиболее простой и
эффективный путь к достижению высокой производительности. Основным недостатком
этого подхода является то, что компилятор может не распознать возможность
эффективного применения векторных операций для увеличения производительности.
2)
Использовать
вставки на ассемблере.
При этом подходе мы
полностью контролируем эффективность программы, исключая возможность
компилятора помочь нам при создании эффективного кода. Недостатки этого подхода
очевидны:
-
необходимо
знать основы программирования на языке ассемблера,
-
ухудшается
переносимость программ.
3)
Использовать
специальные встроенные функции (intrinsics), отображаемые в соответствующие команды SIMD-расширений. Конечно, эти команды должны
поддерживаться компилятором. Преимуществами данного подхода, по сравнению с
остальными, являются:
-
возможность
использовать SIMD-инструкции там, где
это необходимо (а не надеяться на компилятор),
-
возможность
выполнять векторизацию программы не спускаясь до уровня ассемблера,
-
возможность
использования знаний компилятора при генерации кода (например, при отображении
переменных на регистры и выбора порядка следования команд).
Библиотеки подпрограмм
Для некоторых предметных областей существуют эффективно реализованные библиотеки операций, оптимизированные под различные вычислительные системы. Наиболее ярким примером таких библиотек можно назвать BLAS и Lapack, которые содержат процедуры, реализующие многие операции линейной алгебры (работа с векторами, матрицами).
Существуют
реализации этих библиотеки под многие архитектуры, что обеспечивает
переносимость программ, написанных с их использованием. Каждая реализация
стремится учесть все особенности целевой архитектуры для достижения высокой
производительности, в частности, векторные операции, кэш-память.
Задание
Обращение матрицы A размером N*N можно выполнить с помощью разложения в ряд:
![]()
где ![]() ,
, 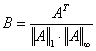 ,
,
![]() ,
, ![]() ,
,
I - единичная матрица (на диагонали - единицы, остальные - нули).
1) Написать три варианта программы вычисления обратной матрицы:
- без использования специальных расширений (обычный вариант),
- с использованием встроенных векторных функций расширения SSE.
- с использованием библиотеки BLAS.
Каждый вариант программы:
- оптимизировать по скорости, насколько это возможно,
- проверить на правильность на небольшом тесте.
Использовать тип данных float.
Размер N предполагать кратным четырем.
2) Сравнить время работы четырех вариантов программы для N=1024, число шагов 10:
- обычный без векторизации компилятором,
- обычный с векторизацией компилятором (нужно указать тип процессора),
- с ручной векторизацией,
- c использованием BLAS.
Определить:
- среднее время одной итерации цикла (умножение + сложение матриц),
- время вычислений вне цикла (общее время минус время в цикле).
Замер времени выполнить несколько раз, в качестве результата взять минимальное время. Для измерения времени использовать функцию times (измерения времени работы процесса).
По результатам измерений сделать вывод.