Программная
архитектура Itanium (IA-64)
В большинстве архитектур суперскалярных процессоров планированием потока команд занимается как компилятор, так и процессор. В архитектуре Itanium, которая относится к классу VLIW/EPIC, планированием потока команд занимается только компилятор. В дополнение к задачам, выполняемым компиляторами для суперскалярных процессоров, компилятор для Itanium составляет связки независимых команд для параллельного исполнения и выполняет распределение ресурсов процессора (регистров, исполнительных устройств). Процессор в свою очередь обеспечивает достаточно большой набор ресурсов (кэш-памяти, регистров, исполнительных устройств, различных таблиц и буферов) для эффективного исполнения потока команд. Компилятор полностью контролирует процесс исполнения программы, включая использование всех архитектурных особенностей процессора, нацеленных на увеличение производительности.
Архитектура Itanium основывается на следующих принципах:
- Явный параллелизм на уровне команд (ILP):
- Компилятор объединяет команды процессора в пары связок по три команды, которые могут быть выполнены параллельно.
- Процессор обеспечивает большое число ресурсов для реализации ILP.
- Способы увеличения ILP:
- Явная спекуляция по данным и управлению (уменьшает задержки по памяти).
- Предикатное исполнение команд (устраняет ветвления).
- Аппаратная поддержка программной конвейеризации циклов (вращение регистров, специальные счетчики циклов, предикатные регистры).
- Предсказание ветвлений.
- Специальные векторные инструкции.
- Специальные способы увеличения производительности:
- Специальная поддержка модульности программ (регистровый стек, вращающиеся регистры).
- Высокопроизводительная вещественная арифметика.
Доступ в память осуществляется с помощью явных инструкций чтения и записи.
По сравнению с процессором, компилятор имеет больше возможностей распознать заложенный в программе параллелизм, т.к. может анализировать всю программу в совокупности. Особые задачи компилятора для архитектуры Itanium:
- Формировать связки команд для параллельного исполнения.
- Вставлять команды предвыборки данных в кэши различных уровней.
- Вставлять команды спекулятивной загрузки данных и вычислений.
- Выполнять программную конвейеризацию циклов.
- Устранять ветвления с помощью предикатных регистров.
- Выполнять векторизацию вычислений.
- Планировать использование регистрового стека.
- Вставлять подсказки процессору о будущих ветвлениях.
- Вставлять подсказки процессору о наилучшем способе предсказания ветвления и о способе предвыборки кода за ветвлением.
Регистры архитектуры Itanium
|
Название |
Мнемоника |
Размер |
Количество |
|
Целочисленные регистры (регистры общего назначения) |
GR |
64 бита |
128 |
|
Вещественные регистры |
FR |
82 бита |
128 |
|
Предикатные регистры |
PR |
1 бит |
64 |
|
Регистры ветвлений |
BR |
64 бита |
8 |
|
Прикладные регистры |
AR |
64 бита |
128 |
|
Указатель команды |
IP |
64 бита |
1 |
- Целочисленные регистры
Используются для хранения логических, скалярных и векторных целочисленных данных.
r0:r31 - статические регистры
r0 - всегда равен 0,
r1 (gp) - глобальный указатель данных,
r2:r3 - регистры временного хранения,
r4:r7 - должны сохраняться при вызове подпрограмм,
r8:r11 - возвращаемые значения подпрограммы,
r12 (sp) - указатель вершины стека,
r13 - указатель потока,
r14:r31 - регистры временного хранения,
r32:r127 - регистровый стек (вращающиеся регистры).
Каждый регистр снабжен битом NaT (Not a Thing), который определяет правильность данных в регистре. Бит NaT используется механизмом спекуляции.
- Вещественные регистры
Используются для хранения вещественных данных. Каждый регистр хранит одно 82-битное вещественное число или два 32-битных вещественных числа.
f0:f31 - статические регистры
f0 - всегда равен +0.0,
f1 - всегда равен +1.0,
f2:f5 - должны сохраняться при вызове подпрограмм,
f6:f7 - регистры временного хранения,
f8:f15 - регистры для передачи параметров и возврата результатов подпрограмм,
f16:f31 - должны сохраняться при вызове подпрограмм,
f32:f127 - вращающиеся регистры.
Каждый регистр может иметь значение NaTVal (Not a Thing Value), которое определяет неправильность данных в регистре. Значение NaTVal используется механизмом спекуляции.
- Предикатные регистры
Используются для хранения результатов операций сравнения.
p0:p15 - статические регистры
p0 - всегда равен 1,
p1:p5 - должны сохраняться при вызове подпрограмм,
p6:p15 - регистры временного хранения,
p16:p63 - вращающиеся регистры.
- Регистры ветвлений
Используются для хранения адресов перехода и возврата из подпрограмм.
b0 - адрес возврата из подпрограммы (call register),
b1:b5 - должны сохраняться при вызове подпрограмм,
b6:b7 - регистры временного хранения.
- Указатель инструкции (IP -
Instruction Pointer)
Содержит адрес текущей исполняемой связки инструкций.
- Прикладные регистры
Используются как регистры данных и управления для различных специальных целей. Некоторые из них:
itc - счетчик тактов (Interval Time Counter),
lc - счетчик цикла (Loop Counter),
ec - счетчик эпилога (Epilog Counter).
Вызов подпрограмм
Вызов подпрограмм и возврат из подпрограммы в архитектуре Itanium выполняется с помощью специальных команд передачи управления: br.call и br.ret. Адрес возврата при вызове подпрограммы помещается не в стек, как в традиционных архитектурах, а в один из регистров ветвлений, указанный в параметре команды. Этот регистр должен быть также указан в команде возврата из подпрограммы. По соглашению для этих целей используется регистр b0. Если подпрограмма выполняет вызов других подпрограмм, она должна сохранить свой адрес возврата из b0, например, в другом регистре.
Передача параметров в подпрограммы в архитектуре Itanium поддерживается аппаратно с помощью регистров, которые работают по принципу стека. Каждой подпрограмме выделяется регистровый кадр, содержащий ее локальные данные. Параметры для передачи располагаются в последних регистрах кадра, которые затем становятся первыми регистрами кадра вызываемой подпрограммы. Очередной кадр для подпрограммы в стеке регистров выделяется специальной командой alloc, в параметрах которой указаны количество входных, локальных и выходных регистров. Команда alloc должна быть первой командой подпрограммы. Формат команды:
alloc r1 = ar.pfs,ins,locals,outs,rots
Здесь ins - число регистров - входных аргументов (не больше 8), locals - число локальных регистров подпрограммы, outs - число регистров - выходных аргументов для передачи в вызываемые подпрограммы (не больше 8), rots - число вращающихся регистров (должно быть кратно 8 и не превосходить ins+locals+outs). Общее число регистров подпрограммы ins+locals+outs не должно превосходить 96.
Специальный блок RSE (Register Stack Engine) обеспечивает автоматическое сохранение стека регистров в память и восстановление из памяти. Для пользователя это выглядит как бесконечный стек регистров.
Если число аргументов подпрограммы превышает 8, то остальные располагаются на обычном стеке в памяти. Если объем локальных данных подпрограммы превышает число имеющихся регистров, то локальные данные также располагаются на стеке в памяти.
|
|
127 |
|
|
|
|
Процедура Б |
|
|
|
. . . |
|
|
|
выход (outs) |
|
96 регистров в стеке |
|
Процедура Б |
|
Процедура А |
|
локальные данные (locals) |
|
|
|
Перекрытие |
|
выход (outs) |
: r32 |
вход (ins) |
|
|
|
Процедура А |
|
локальные данные (locals) |
|
|
|
|
|
|
: r32 |
вход (ins) |
|
|
|
|
32 |
. . . |
|
|
|
|
|
|
31 0 |
32 глобальных регистра |
r31 r0 |
глобальные данные |
r31 r0 |
глобальные данные |
Вращение регистров
Первые несколько регистров подпрограммы, начиная с r32 для целочисленных, f32 для вещественных и p16 для предикатных, могут быть обозначены как вращающиеся. При выполнении специальных команд ветвления виртуальные номера вращающихся регистров циклически сдвигаются вправо на один. Так, регистр r32 получает имя r33, r33 становится r34 и т.д. Последний вращающийся регистр становится регистром r32. Аналогичным образом ведут себя вращающиеся вещественные и предикатные регистры. Размер окна вращения целочисленных регистров задается командой alloc и всегда кратен 8. Размер окна вращения вещественных регистров всегда равен 96. Размер окна вращения предикатных регистров всегда равен 48.
Команды архитектуры Itanium
Команды архитектуры Itanium объединяются в связки по три независимые инструкции, которые затем исполняются параллельно. Каждая связка занимает 16 байт:
- 3 * 41 бит - команды,
- 5 бит - шаблон.
Шаблон указывает, команды какого типа присутствуют в связке. Эта информация помогает быстро декодировать и распределить команды по исполнительным устройствам. В архитектуре Itanium определены допустимые шаблоны связок. Типы команд в связке:
M - операции с памятью / присваивание,
I - сложные целочисленные / векторные операции,
A - простые целочисленные / логические / векторные операции,
F - вещественные операции (обычные / векторные),
B - команды ветвлений.
Классы пользовательских инструкций:
- Логические операции,
- Арифметические операции,
- Операции сравнения,
- Операции сдвига,
- Векторные целочисленные операции,
- Команды передачи управления (ветвлений),
- Команды ветвлений для организации циклов,
- Вещественные операции,
- Векторные вещественные операции,
- Операции с памятью,
- Операции присваивания,
- Команды управления кэшированием.
Формат команды
(qp) ops[.comp1] [.comp2] r1 = r2, r3
qp - предикатный регистр (по умолчанию p0),
ops - имя команды,
comp1, comp2 - опции, указывающие вариант исполнения данной команды,
Управление кэшированием
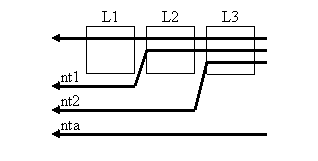
Копии данных, запрашиваемых из оперативной памяти, обычно помещаются в кэш-память. Чтобы уменьшить время ожидания данных, существует команда lfetch, которая осуществляет предварительную выборку данных в кэш-память без записи в регистр. В результате данные при последующем чтении становятся доступны за некоторое известное число тактов.
Бывают ситуации, когда нежелательно помещать копии загружаемых данных в кэш-память, вытесняя оттуда какие-то другие, возможно нужные, данные. Примером может быть однократная обработка массива, который в ближайшем будущем больше не понадобится. Для обозначения предпочтительного пути данных используются специальные суффиксы команд чтения, записи и предвыборки.
|
|
Суффикс |
Команды загрузки |
Команды записи |
Команды предвыборки |
|
Использовать все кэши |
|
ld |
st |
lfetch |
|
Использовать кэши L2 и L3 |
.nt1 |
ld.nt1 |
- |
lfetch.nt1 |
|
Использовать кэш L3 |
.nt2 |
- |
- |
lfetch.nt2 |
|
Не использовать кэши |
.nta |
ld.nta |
st.nta |
lfetch.nta |

Спекуляция по управлению (control speculation)
Предварительная загрузка (и использование) данных до того, как стало ясно, что они понадобятся, устраняет простой из-за ожидания данных.
|
В традиционной архитектуре |
IA-64: Загрузка данных до ветвления |
IA-64: Использование данных до ветвления |
|
instr1 instr2 . . . br LABEL . . . LABEL: ld r1 = : use : = r1 |
ld.s r1 = : instr1 instr2 . . . br LABEL . . . LABEL: chk.s r1 use : = r1 |
ld.s r1 = : instr1 use : = r1 instr2 . . . br LABEL . . . LABEL: chk.s use |
|
|
|
Код
восстановления: ld r1 = : use : = r1 br |
Команда chk.s нужна для обработки прерываний, которые возможно случились во время выполнения спекулятивных операций и были отложены.
Спекуляция по данным (data speculation)
Предварительная загрузка данных до проверки наличия конфликтов с операциями записи устраняет простой из-за ожидания данных.
|
В традиционной архитектуре |
IA-64: Загрузка данных до проверки |
IA-64: Использование данных до проверки |
|
instr1 instr2 .
. . st [?] -
B
a r r i e r - ld r1 = : use
: = r1 |
ld.a r1 = : instr1 instr2 .
. . st [?] chk.a r1 use : = r1 |
ld.a r1 = : instr1 use : = r1 instr2 . . . st
[?] chk.a r1 . . . |
|
|
|
Код
восстановления: ld r1
= : use
: = r1 br |
В процессоре существует специальный буфер ALAT (Advanced Load Address Table), который хранит записи о предварительно загружаемых данных (между командами ld.a и chk.a). При записи элемента данных в память проверяется наличие пересекающегося с ним элемента в буфере ALAT. Если такая запись присутствует, она будет помечена, как неправильная. И тогда при выполнении операции chk.a данные будут еще раз запрошены из памяти. Буфер ALAT имеет размер в 32 записи. Поэтому более 32 одновременных спекулятивных по данным загрузок использовать неэффективно.
Предикатное исполнение инструкций
Для каждой инструкции в программе указан предикатный регистр, значение которого определяет, будет ли вы данная инструкция выполнена. Предикатное исполнение позволяет оптимизировать или устранять ветвления, а также организовывыть программную конвейеризацию циклов.
Организация ветвлений
Для хранения адресов ветвлений используются специальные регистры ветвлений. Процессор может исполнять одновременно несколько ветвлений в одной связке. Переход выполнится по первой команде ветвления в связке с истинным предикатом. С помощью предикатного исполнения удается избежать операций ветвлений в коде, заменяя зависимости по управлению зависимостями по данным.
|
Обычный код |
IA-64: Предикатно исполняемый код |
|
cmp a,b jump EQ y=3 jump END: EQ: y=4 END: |
cmp.eq.p1,p2=a,b (p1) y=4 (p2) y=3 |
Специальные команды ветвлений
Архитектура Itanium предоставляет
набор команд передачи управления, используемые для различных случаев организации
кода.
|
Пример команды |
Описание |
|
br dest |
Безусловный переход на метку dest. |
|
(p) br.cond dest |
Условный переход на метку dest в зависимости от значения предикатного регистра. |
|
(p) br.call b0=func |
Вызов подпрограммы func, сохранение адреса возврата в регистре b0. |
|
(p) br.ret b0 |
Возврат из подпрограммы с передачей управления по адресу в регистре b0. |
|
br.cloop dest |
Команда проверяет значение регистра ar.lc, и если оно больше нуля, то уменьшает его на 1 и переходит на метку dest, иначе переход не выполняется. Используется в циклах со счетчиком. |
|
br.ctop dest |
Если значение регистра ar.lc больше нуля, то оно уменьшается на 1 и происходит переходит на метку dest, иначе если значение регистра ar.ec больше нуля, то оно уменьшается на 1 и переход также происходит, иначе переход не выполняется. При выполнении перехода происходит сдвиг имен вращающихся регистров на 1. Используется в программно-конвейеризованных циклах со счетчиком. |
|
br.cexit
dest |
Аналогично br.ctop, но переход происходит в обратном случае (если ar.lc и ar.ec равны нулю). Используется в программно-конвейеризованных циклах со счетчиком. |
|
(p) br.wtop dest |
Если значение предиката p истинно, то происходит переходит на метку dest, иначе если значение регистра ar.ec больше нуля, то оно уменьшается на 1 и переход также происходит, иначе переход не выполняется. При выполнении перехода происходит сдвиг имен вращающихся регистров на 1. Используется в программно-конвейеризованных циклах типа while. |
|
(p) br.wexit dest |
Аналогично br.wtop, но переход происходит в обратном случае (если p ложно и ar.ec равен нулю). Используется в программно-конвейеризованных циклах типа while. |
Дополнительные суффиксы команд перехода позволяют контролировать предсказание условных переходов:
|
.sptk |
Статически предсказывать, что выполнится. |
|
.spnt |
Статически предсказывать, что не выполнится. |
|
.dptk |
Предсказывать динамически. Первый раз предсказать, что выполнится. |
|
.dpnt |
Предсказывать динамически. Первый раз предсказать, что не выполнится. |
Существуют суффиксы, указывающие способ предвыборки команд по предсказанному направлению перехода:
|
.few |
Предвыбирать несколько команд. |
|
.many |
Предвыбирать много команд. |
Программная конвейеризация
При программной конвейеризации выполнение цикла организуется в виде конвейера, так что отдельные операции на каждой итерации цикла работают независимо, т.к. соответствуют разным итерациям исходного цикла. Программная конвейеризация обычно требует добавления в код специального пролога и эпилога для разгона и завершения конвейера, а также дополнительных команд переприсваивания регистров в теле цикла, чтобы освободить их для исполнения этой же стадии для следующей итерации. В процессорах архитектуры Itanium программная конвейеризация цикла не требует дополнительного кода, т.к. поддерживается аппаратно с помощью:
- специальных команд ветвления,
- специальных счетчиков цикла (LC - Loop Count) и эпилога (EC - Epilogue Count),
- вращения регистров,
- предикатных регистров.
|
С код |
Превдо-ассемблерный код |
|
int n=5, i; for (i=0;i<n;i++) y[i]=x[i]+1; |
mov pr.rot = 0 // Очистка всех вращающихся предикатных регистров cmp.eq p16,p0
= r0,r0 // p16 = 1 mov ar.lc = 4 // LC = n - 1 mov ar.ec = 3 // EC = число команд в цикле loop: (p16) ld1 r32 =
[r12],1 // 1: load x (p17) add r34 =
1,r33 // 2: y=x+1 (p18) st1 [r13] =
r35,1 // 3: store y br.ctop.sptk.few
loop |
При выполнении команды перехода в конце тела цикла счетчик цикла (ar.lc) уменьшается на единицу, а значения всех вращающихся регистров сдвигаются вправо на один регистр. Когда счетчик цикла достигает нуля, начинает уменьшаться счетчик эпилога (ar.ec), а вращающиеся предикатные регистры, начиная с p16, начинают заполняться нулями. При достижении счетчиком эпилога нуля происходит выход из цикла.