йУФПТЙЮЕУЛЙ, РТПЗТБННЙТПЧБОЙЕ ДМС ОЕУЛПМШЛЙИ
НБЫЙО ВЩМП ФТХДПЕНЛЙН, УМПЦОЩН Й РПМОЩН ПЫЙВПЛ.
рТПЗТБННЙУФ ДПМЦЕО ЪОБФШ НОПЦЕУФЧП ДЕФБМЕК П УЕФЙ, Б
ЙОПЗДБ, ФБЛЦЕ ПВ БРРБТБФОПН ПВЕУРЕЮЕОЙЙ. чБН ОХЦОП ВЩМП ТБЪВЙТБФШУС У ТБЪМЙЮОЩНЙ
“УМПСНЙ” УЕФЕЧЩИ РТПФПЛПМПЧ, Й, ЛТПНЕ ФПЗП, УХЭЕУФЧПЧБМП НОПЦЕУФЧП
ЖХОЛГЙК Ч УЕФЕЧЩИ ВЙВМЙПФЕЛБИ ДМС УПЕДЙОЕОЙС, ТБУРБЛПЧЛЙ, ХРБЛПЧЛЙ ВМПЛПЧ
ЙОЖПТНБГЙЙ; РЕТЕДБЮЙ ЬФЙИ ВМПЛПЧ ФХДБ Й ПВТБФОП; Й РПДФЧЕТЦДЕОЙС УЧСЪЙ. ьФП
ВЩМБ ФСЦЕМБС ЪБДБЮБ.
пДОБЛП, ПУОПЧОБС ЙДЕС ТБУРТЕДЕМЕООПЗП РТПЗТБННЙТПЧБОЙС
ОЕ ФБЛ УМПЦОБ, Й МЕЗЛП ТЕЪАНЙТХЕФУС Ч ВЙВМЙПФЕЛБИ Java. чЩ ИПФЙФЕ:
дМС ЛБЦДПЗП РХОЛФБ ВХДЕФ ДБОП ОЕВПМШЫПЕ ЧЧЕДЕОЙЕ Ч ЬФПК
ЗМБЧЕ. пВТБФЙФЕ ЧОЙНБОЙЕ, ЮФП ЛБЦДБС ФЕНБ ДПЧПМШОП ПВЯЕНОБС Й УБНБ РП УЕВЕ
НПЦЕФ ЪБОЙНБФШ ПФДЕМШОХА ЛОЙЗХ, ФБЛ ЮФП ЬФБ ЗМБЧБ РТЕДОБЪОБЮЕОБ ДМС ПЪОБЛПНМЕОЙС
У ЬФЙНЙ ТБЪДЕМБНЙ. ьФП, ЛПОЕЮОП, ОЕ УДЕМБЕФ чБУ ЬЛУРЕТФБНЙ РП ДБООЩН ЧПРТПУБН
(ИПФС, чЩ НПЦЕФЕ ДПЧПМШОП ДБМЕЛП РТПКФЙ У РПНПЭША ЙОЖПТНБГЙЙ РТЕДУФБЧМЕООПК
ЪДЕУШ РП УЕФЕЧПНХ РТПЗТБННЙТПЧБОЙА, УЕТЧМЕФБН Й JSPs).
пДОЙН ЙЪ ВПМШЫЙИ ДПУФЙЦЕОЙК Java СЧМСЕФУС ВЕЪВПМЕЪОЕООПЕ
ПВЭЕОЙЕ Ч УЕФЙ. рТПЕЛФЙТПЧЭЙЛЙ УЕФЕЧПК ВЙВМЙПФЕЛЙ Java УДЕМБМЙ ЕЕ РПИПЦЕК
ОБ ЮФЕОЙЕ Й ЪБРЙУШ ЖБКМПЧ, ЪБ ЙУЛМАЮЕОЙЕН ФПЗП, ЮФП ЬФПФ “ЖБКМ”
ОБИПДЙФУС ОБ ХДБМЕООПК НБЫЙОЕ Й ХДБМЕООБС НБЫЙОБ НПЦЕФ Ч ФПЮОПУФЙ ПРТЕДЕМЙФШ,
ЮФП ОХЦОП УДЕМБФШ У ЙОЖПТНБГЙЕК, ЛПФПТХА чЩ РПУЩМБЕФЕ МЙВП ФТЕВХЕФЕ. оБУЛПМШЛП
ЧПЪНПЦОП, ЧОХФТЕООЙЕ ДЕФБМЙ УЕФЕЧПЗП ПВЭЕОЙС БВУФТБЗЙТПЧБОЩ Й ПВТБВБФЩЧБАФУС
ЧОХФТЙ JVM Й МПЛБМШОПК НБЫЙОЩ, ОБ ЛПФПТПК ХУФБОПЧМЕОБ УТЕДБ Java. нПДЕМШ РТПЗТБННЙТПЧБОЙС
ФБЛБС ЦЕ, ЛБЛ чЩ ЙУРПМШЪХЕФЕ Ч ЖБКМЕ; Ч ДЕКУФЧЙФЕМШОПУФЙ, чЩ РТПУФП ПЛХФЩЧБЕФЕ
УЕФЕЧПЕ УПЕДЙОЕОЙЕ (“УПЛЕФ”) РПФПЛПЧЩН ПВЯЕЛФПН, Й чЩ ДЕКУФЧХЕФЕ
ЙУРПМШЪХС ФЕ ЦЕ ЧЩЪПЧЩ НЕФПДПЧ, ЮФП Й У ДТХЗЙНЙ РПФПЛПЧЩНЙ ПВЯЕЛФБНЙ. л ФПНХ
ЦЕ, ЧУФТПЕООБС Ч Java НОПЦЕУФЧЕООПУФШ РТПГЕУУПЧ ПЮЕОШ ХДПВОБ РТЙ ПВЭЕОЙЙ Ч
УЕФЙ: ХУФБОПЧЛБ ОЕУЛПМШЛЙИ УПЕДЙОЕОЙК УТБЪХ.
лПОЕЮОП, ЮФПВЩ ХВЕДЙФШУС, ЮФП УПЕДЙОЕОЙЕ ХУФБОПЧМЕОП
У ЛПОЛТЕФОПК НБЫЙОПК Ч УЕФЙ, ДПМЦЕО ВЩФШ УРПУПВ ХОЙЛБМШОПК ЙДЕОФЙЖЙЛБГЙЙ
НБЫЙОЩ Ч УЕФЙ. тБОШЫЕ, РТЙ ТБВПФЕ Ч УЕФЙ ВЩМП ДПУФБФПЮОП РТЕДПУФБЧЙФШ ХОЙЛБМШОЩЕ
ЙНЕОБ ДМС НБЫЙО ЧОХФТЙ МПЛБМШОПК УЕФЙ. оП, Java ТБВПФБЕФ Ч Internet, ЛПФПТЩК
ФТЕВХЕФ ХОЙЛБМШОПК ЙДЕОФЙЖЙЛБГЙЙ НБЫЙОЩ У МАВПК ДТХЗПК ЧП ЧУЕК УЕФЙ РП
ЧУЕНХ НЙТХ. ьФП ДПУФЙЗБЕФУС У РПНПЭША IP
(Internet Protocol) БДТЕУБГЙЙ, ЛПФПТБС НПЦЕФ ЙНЕФШ ДЧЕ ЖПТНЩ:
ч ПВПЙИ УМХЮБСИ, IP БДТЕУ РТЕДУФБЧМСЕФУС ЛБЛ 32 ВЙФОПЕ
ЪОБЮЕОЙЕ[72]
(ЛБЦДПЕ ЮЙУМП ЙЪ 4-И ОЕ НПЦЕФ РТЕЧЩЫБФШ 255), Й чЩ НПЦЕФЕ РПМХЮЙФШ УРЕГЙБМШОЩК
ПВЯЕЛФ Java ДМС РТЕДУФБЧМЕОЙС ЬФПЗП ОПНЕТБ ЙЪ ЖПТНЩ, РТЕДУФБЧМЕООПК ЧЩЫЕ У
РПНПЭША НЕФПДБ static InetAddress.getByName( ) Ч РБЛЕФЕ
java.net. тЕЪХМШФБФ ЬФП ПВЯЕЛФ ФЙРБ InetAddress, ЛПФПТЩК чЩ
НПЦЕФЕ ЙУРПМШЪПЧБФШ ДМС УПЪДБОЙС “УПЛЕФБ”, ЛБЛ чЩ РПЪДОЕЕ ХЧЙДЙФЕ.
рТПУФПК РТЙНЕТ ЙУРПМШЪПЧБОЙС InetAddress.getByName( ),
РПЛБЪЩЧБЕФ ЮФП РТПЙУИПДЙФ, ЛПЗДБ Х чБУ ЕУФШ РТПЧБКДЕТ ЙОФЕТОЕФ РП ЛПННХФЙТХЕНЩН
УПЕДЙОЕОЙСН (ISP). лБЦДЩК ТБЪ, ЛПЗДБ чЩ ДПЪЧБОЙЧБЕФЕУШ, чБН РТЙУЧБЙЧБЕФУС
ЧТЕНЕООЩК IP. оП, РПЛБ чЩ УПЕДЙОЕОЩ, чБЫ IP БДТЕУ ОЙЮЕН ОЕ ПФМЙЮБЕФУС ПФ МАВПЗП
ДТХЗПЗП IP БДТЕУБ Ч ЙОФЕТОЕФ. еУМЙ ЛФП-ФП РПДЛМАЮЙФУС Л чБЫЕК НБЫЙОЕ, ЙУРПМШЪХС
чБЫ IP БДТЕУ, ПО УНПЦЕФ РПДЛМАЮЙФШУС ФБЛЦЕ Л Web ЙМЙ FTP УЕТЧЕТХ, ЛПФПТЩК
ЪБРХЭЕО ОБ чБЫЕК НБЫЙОЕ. лПОЕЮОП, УОБЮБМБ ОЕПВИПДЙНП ХЪОБФШ чБЫ IP БДТЕУ,
Б Ф.Л. РТЙ ЛБЦДПН УПЕДЙОЕОЙЙ РТЙУЧБЙЧБЕФУС ОПЧЩК БДТЕУ, ЛБЛ чЩ УНПЦЕФЕ ЕЗП
ХЪОБФШ?
уМЕДХАЭБС РТПЗТБННБ ЙУРПМШЪХЕФ InetAddress.getByName( )
ДМС ПРТЕДЕМЕОЙС чБЫЕЗП IP БДТЕУБ. юФПВЩ ЙУРПМШЪПЧБФШ ЕЗП, чЩ ДПМЦОЩ ЪОБФШ
ЙНС УЧПЕЗП ЛПНРШАФЕТБ. ч Windows 95/98, ЪБКДЙФЕ Ч “Settings”,
“Control Panel”, “Network”, Б ЪБФЕН ЧЩВЕТЙФЕ УФТБОЙЮЛХ
“Identification”. “Computer name” ЬФП ЙНС, ЛПФПТПЕ
ОЕПВИПДЙНП ЪБДБФШ Ч ЛПНБОДОПК УФТПЛЕ.
//: c15:WhoAmI.java
// пРТЕДЕМСЕФ чБЫ УЕФЕЧПК БДТЕУ
// ЛПЗДБ чЩ РПДЛМАЮЕОЩ Л Internet.
import java.net.*;
public class WhoAmI {
public static void main(String[] args)
throws Exception {
if(args.length != 1) {
System.err.println(
"Usage: WhoAmI MachineName");
System.exit(1);
}
InetAddress a =
InetAddress.getByName(args[0]);
System.out.println(a);
}
} ///:~
ч ЬФПН УМХЮБЕ, НБЫЙОБ ОБЪЩЧБЕФУС “peppy”.
йФБЛ, ЛПЗДБ С УПЕДЙОСАУШ У НПЙН РТПЧБКДЕТПН, С ЪБРХУЛБА РТПЗТБННХ:
java WhoAmI peppy
с РПМХЮБА Ч ПФЧЕФ УППВЭЕОЙЕ РПДПВОПЕ ЬФПНХ (ЛПОЕЮОП
БДТЕУ ЛБЦДЩК ТБЪ ОПЧЩК):
peppy/199.190.87.75
еУМЙ С УППВЭХ ЬФПФ БДТЕУ НПЕНХ ДТХЗХ, Й Х НЕОС ВХДЕФ
Web УЕТЧЕТ, ЪБРХЫЕООЩК ОБ ЛПНРШАФЕТЕ, ПОЙ НПЗХФ УПЕДЙОЙФШУС У ОЙН, ЪБКДС ОБ
URL http://199.190.87.75 (ФПМШЛП РПЛБ С ПУФБАУШ Ч ЬФПН УЕБОУЕ УЧСЪЙ).
ьФП ЙОПЗДБ НПЦЕФ ВЩФШ ХДПВОЩН УРПУПВПН РТЕДПУФБЧМЕОЙС ЙОЖПТНБГЙЙ ЛПНХ-ФП ДТХЗПНХ,
МЙВП ФЕУФЙТПЧБОЙС ЛПОЖЙЗХТБГЙЙ Web УБКФБ РЕТЕД ФЕН ЛБЛ ПРХВМЙЛПЧБФШ ЕЗП ОБ
“ТЕБМШОПН” УЕТЧЕТЕ.
пУОПЧОБС ЪБДБЮБ УЕФЙ - РТЕДПУФБЧМЕОЙЕ ДЧХН НБЫЙОБН ЧПЪНПЦОПУФЙ
УПЕДЙОЙФШУС Й ПВЭБФШУС ДТХЗ У ДТХЗПН. лБЛ ФПМШЛП ДЧЕ НБЫЙОЩ ОБЫМЙ ДТХЗ ДТХЗБ,
ПОЙ НПЗХФ ПФМЙЮОПЕ ЙНЕФШ ДЧХИУФПТПООЕЕ ПВЭЕОЙЕ. оП ЛБЛ ПОЙ ОБИПДСФ ДТХЗ ДТХЗБ?
ьФП ЛБЛ РПФЕТСФШУС Ч РБТЛЕ ТБЪЧМЕЮЕОЙК: ПДОБ НБЫЙОБ ДПМЦОБ ПУФБЧБФШУС ОБ НЕУФЕ
Й УМХЫБФШ, РПЛБ ДТХЗБС НБЫЙОБ ОЕ УЛБЦЕФ, “ьК! зДЕ ФЩ?”
нБЫЙОБ, ЛПФПТБС “ПУФБЕФУС ОБ ПДОПН НЕУФЕ”
ОБЪЩЧБЕФУС УЕТЧЕТПН,
Б ФПФ, ЛПФПТЩК ЙЭЕФ, ОБЪЩЧБЕФУС ЛМЙЕОФПН.
ьФП ТБЪМЙЮЙЕ ЧБЦОП ФПМШЛП ЛПЗДБ ЛМЙЕОФ РЩФБЕФУС РПДЛМАЮЙФШУС Л УЕТЧЕТХ. лБЛ
ФПМШЛП ПОЙ УПЕДЙОСФУС, РТПЙУИПДЙФ РТПГЕУУ ДЧХИУФПТПООЕЗП ПВЭЕОЙС Й ОЕ ЧБЦОП,
ЮФП ПДЙО СЧМСЕФУС УЕТЧЕТПН, Б ДТХЗПК - ЛМЙЕОФПН.
йФБЛ, ТБВПФБ УЕТЧЕТБ - УМХЫБФШ УПЕДЙОЕОЙЕ, Й ЬФП ЧЩРПМОСЕФУС
У РПНПЭША УРЕГЙБМШОПЗП УЕТЧЕТОПЗП ПВЯЕЛФБ, ЛПФПТЩК чЩ УПЪДБЕФЕ. тБВПФБ ЛМЙЕОФБ
- РПРЩФБФШУС УПЪДБФШ УПЕДЙОЕОЙЕ У УЕТЧЕТПН, ЮФП ЧЩРПМОСЕФУС У РПНПЭША УРЕГЙБМШОПЗП
ЛМЙЕОФУЛПЗП ПВЯЕЛФБ. лБЛ ФПМШЛП УПЕДЙОЕОЙЕ ХУФБОПЧМЕОП, чЩ ХЧЙДЙФЕ, ЮФП Х
ЛМЙЕОФБ Й УЕТЧЕТБ УПЕДЙОЕОЙЕ НБЗЙЮЕУЛЙ РТЕЧТБЭБЕФУС Ч РПФПЛПЧЩК ПВЯЕЛФ ЧЧПДБ/ЧЩЧПДБ,
Й У ЬФПЗП НПНЕОФБ чЩ НПЦЕФЕ ТБУУНБФТЙЧБФШ УПЕДЙОЕОЙЕ ЛБЛ ЖБКМ, ЛПФПТЩК чЩ
НПЦЕФЕ ЮЙФБФШ, Й Ч ЛПФПТЩК чЩ НПЦЕФЕ ЪБРЙУЩЧБФШ. ф.П., РПУМЕ ХУФБОПЧМЕОЙС
УПЕДЙОЕОЙС чЩ ВХДЕФЕ ЙУРПМШЪПЧБФШ ХЦЕ ЪОБЛПНЩЕ чБН ЛПНБОДЩ ЧЧПДБ/ЧЩЧПДБ ЙЪ
зМБЧЩ 11. ьФП ПДОП ЙЪ ПФМЙЮОЩИ ТБУЫЙТЕОЙК УЕФЕЧПК ВЙВМЙПФЕЛЙ Java.
рП НОПЗЙН РТЙЮЙОБН, чБН НПЦЕФ ОЕ ВЩФШ ДПУФХРОБ ЛМЙЕОФУЛБС
НБЫЙОБ, УЕТЧЕТОБС НБЫЙОБ, Й ЧППВЭЕ УЕФШ ДМС ФЕУФЙТПЧБОЙС чБЫЕК РТПЗТБННЩ.
чЩ НПЦЕФЕ ЧЩРПМОЙФШ ХРТБЦОЕОЙС Ч ЛМБУУОПК ЛПНОБФЕ, МЙВП, чЩ НПЦЕФЕ ОБРЙУБФШ
РТПЗТБННХ, ЛПФПТБС ОЕДПУФБФПЮОП ХУФПКЮЙЧБ ДМС ТБВПФЩ Ч УЕФЙ. уПЪДБФЕМЙ ЙОФЕТОЕФ
РТПФПЛПМБ ВЩМЙ ПУЧЕДПНМЕОЩ П ФБЛЙИ РТПВМЕНБИ, Й ПОЙ УПЪДБМЙ УРЕГЙБМШОЩК БДТЕУ,
ОБЪЩЧБЕНЩК localhost,
“МПЛБМШОБС РЕФМС”,
ЛПФПТЩК СЧМСЕФУС IP БДТЕУПН ДМС ФЕУФЙТПЧБОЙС ВЕЪ ОБМЙЮЙС УЕФЙ. пВЩЮОЩК УРПУПВ
РПМХЮЕОЙС ЬФПЗП БДТЕУБ Ч Java ЬФП:
InetAddress addr = InetAddress.getByName(null);
еУМЙ чЩ УФБЧЙФЕ РБТБНЕФТ null Ч НЕФПД getByName( ),
ФП, РП ХНПМЮБОЙА ЙУРПМШЪХЕФУС localhost. InetAddress ЬФП ФП,
ЮФП чЩ ЙУРПМШЪХЕФЕ ДМС УУЩМЛЙ ОБ ЛПОЛТЕФОХА НБЫЙОХ, Й чЩ ДПМЦОЩ РТЕДПУФБЧМСФШ
ЬФП, РЕТЕД ФЕН ЛБЛ РТПДПМЦЙФШ ДБМШОЕКЫЙЕ ДЕКУФЧЙС. чЩ ОЕ НПЦЕФЕ НБОЙРХМЙТПЧБФШ
УПДЕТЦБОЙЕН InetAddress (ОП чЩ НПЦЕФЕ ТБУРЕЮБФБФШ ЕЗП, ЛБЛ чЩ ХЧЙДЙФЕ
Ч УМЕДХАЭЕН РТЙНЕТЕ). еДЙОУФЧЕООЩК УРПУПВ УПЪДБФШ InetAddress - ЬФП
ЙУРПМШЪПЧБФШ ПДЙО ЙЪ РЕТЕЗТХЦЕООЩИ УФБФЙЮЕУЛЙИ НЕФПДПЧ getByName( )
(ЛПФПТЩК чЩ ПВЩЮОП ЙУРПМШЪХЕФЕ), getAllByName( ), МЙВП getLocalHost( ).
чЩ НПЦЕФЕ УПЪДБФШ БДТЕУ МПЛБМШОПК РЕФМЙ, ХУФБОПЧЛПК
УФТПЛПЧПЗП РБТБНЕФТБ localhost:
InetAddress.getByName("localhost");
(РТЙУЧБЙЧБОЙЕ “localhost” ЛПОЖЙЗХТЙТХЕФУС
Ч ФБВМЙГЕ “hosts” ОБ чБЫЕК НБЫЙОЕ), МЙВП У РПНПЭША ЮЕФЩТЕИФПЮЕЮОПК
ЖПТНЩ ДМС ЙНЕОПЧБОЙС ЪБТЕЪЕТЧЙТПЧБООПЗП IP БДТЕУБ ДМС РЕФМЙ:
InetAddress.getByName("127.0.0.1");
IP БДТЕУБ ОЕДПУФБФПЮОП ДМС ЙОДЙЛБГЙЙ ХОЙЛБМШОПЗП УЕТЧЕТБ,
Ф.Л. НОПЗП УЕТЧЕТПЧ НПЦЕФ УХЭЕУФЧПЧБФШ ОБ ПДОПК НБЫЙОЕ. лБЦДБС НБЫЙОБ Ч IP
ФБЛЦЕ УПДЕТЦЙФ РПТФЩ, Й ЛПЗДБ чЩ ХУФБОБЧМЙЧБЕФЕ ЛМЙЕОФБ ЙМЙ УЕТЧЕТБ
чЩ ДПМЦОЩ ЧЩВТБФШ РПТФ, РП
ЛПФПТПНХ УЕТЧЕТ Й ЛМЙЕОФ ДПЗПЧПТЙМЙУШ УПЕДЙОЙФШУС; ЕУМЙ чЩ ЧУФТЕЮБЕФЕ ЛПЗП-ФП,
IP БДТЕУ ЬФП ПЛТЕУФОПУФШ Й РПТФ ЬФП ВБТ.
рПТФ ЬФП ОЕ ЖЙЪЙЮЕУЛПЕ ТБУРПМПЦЕОЙЕ Ч НБЫЙОЕ, Б РТПЗТБННОБС
БВУФТБЛГЙС (ВПМШЫЕК ЮБУФША ДМС ВХИЗБМФЕТУЛПЗП ОБЪОБЮЕОЙС). лМЙЕОФУЛБС РТПЗТБННБ
ЪОБЕФ, ЛБЛ УПЕДЙОЙФШУС У НБЫЙОПК РП IP БДТЕУХ, ОП ЛБЛ УПЕДЙОЙФШУС У ОХЦОПК
УМХЦВПК (РПФЕОГЙБМШОП ПДОПК ЙЪ НОПЗЙИ ОБ ЬФПК НБЫЙОЕ)? чПФ ЗДЕ ОПНЕТБ РПТФПЧ
СЧМСАФУС ЧФПТЩН ХТПЧОЕН БДТЕУБГЙЙ. йДЕС Ч ФПН, ЮФП чЩ ЪБРТБЫЙЧБЕФЕ ЛПОЛТЕФОЩК
РПТФ, ЬФЙН ЪБРТБЫЙЧБС УМХЦВХ, БУУПГЙЙТПЧБООХА У ЬФЙН РПТФПН. чТЕНС ДОС ЬФП
РТПУФПК РТЙНЕТ УМХЦВЩ. пВЩЮОП, ЛБЦДБС УМХЦВБ БУУПГЙЙТХЕФУС У ХОЙЛБМШОЩН ОПНЕТПН
РПТФБ ОБ ЪБДБООПК УЕТЧЕТОПК НБЫЙОЕ. оЕПВИПДЙНП ЪОБФШ ЪБТБОЕЕ, ОБ ЛБЛПН РПТФХ
ЪБРХЭЕОБ ОЕПВИПДЙНБС УМХЦВБ.
уЙУФЕНОЩЕ УМХЦВЩ ТЕЪЕТЧЙТХАФ ОПНЕТБ РПТФПЧ У 1 РП 1024,
ФБЛ ЮФП чЩ ОЕ ДПМЦОЩ ЙУРПМШЪПЧБФШ ОЙ ПДЙО ЙЪ РПТФПЧ, ЛПФПТЩК чЩ ЪОБЕФЕ, ЮФП
ПО ЙУРПМШЪХЕФУС. рЕТЧЩК ЧЩВПТ РПТФБ ДМС РТЙНЕТПЧ Ч ЬФПК ЛОЙЗЕ ЬФП РПТФ ОПНЕТ
8080 (Ч РБНСФШ РПЮФЕООПЗП Й ДТЕЧОЕЗП 8-ВЙФОПЗП ЮЙРБ Intel 8080 ОБ НПЕН РЕТЧПН
ЛПНРШАФЕТЕ, У ПРЕТБГЙПООПК УЙУФЕНПК CP/M).
уПЛЕФ ЬФП РТПЗТБННОБС БВУФТБЛГЙС, ЙУРПМШЪХЕНБС
ДМС РТЕДУФБЧМЕОЙС “ФЕТНЙОБМПЧ” УПЕДЙОЕОЙК НЕЦДХ ДЧХНС НБЫЙОБНЙ.
дМС ДБООПЗП УПЕДЙОЕОЙС, УХЭЕУФЧХЕФ УПЛЕФ ОБ ЛБЦДПК НБЫЙОЕ, Й чЩ НПЦЕФЕ РТЕДУФБЧЙФШ
ЗЙРПФЕФЙЮЕУЛЙК “ЛБВЕМШ” УПЕДЙОСАЭЙК ДЧЕ НБЫЙОЩ, ЛБЦДЩК ЛПОЕГ ЛПФПТПЗП
ЧУФБЧМЕО Ч УПЛЕФ. лПОЕЮОП, ЛБЛПЕ БРРБТБФОПЕ ПВЕУРЕЮЕОЙЕ Й ЛБВЕМШ НЕЦДХ ОЙНЙ
ОЕЙЪЧЕУФОП. пУОПЧОПК УНЩУМ БВУФТБЛГЙЙ Ч ФПН, ЮФП ОБН ОЕ ОХЦОП ЪОБФШ ВПМШЫЕ,
ЮЕН ОЕПВИПДЙНП.
ч Java, чЩ УПЪДБЕФЕ УПЛЕФ ДМС ХУФБОПЧМЕОЙС УПЕДЙОЕОЙС
У ДТХЗПК НБЫЙОПК, ЪБФЕН чЩ РПМХЮБЕФЕ InputStream Й OutputStream
(МЙВП У РПНПЭША УППФЧЕФУФЧХАЭЙИ РТЕПВТБЪПЧБФЕМЕК, Reader Й Writer)
ЙЪ УПЛЕФБ, ЛПФПТЩК УППФЧЕФУФЧХАЭЙН ПВТБЪПН РТЕДУФБЧМСЕФ УПЕДЙОЕОЙЕ, ЛБЛ
РПФПЛПЧЩК ПВЯЕЛФ ЧЧПДБ ЧЩЧПДБ. еУФШ ДЧБ ЛМБУУБ УПЛЕФПЧ, ПУОПЧБООЩИ ОБ РПФПЛБИ:
ServerSocket - ЙУРПМШЪХЕФУС УЕТЧЕТПН, ЮФПВЩ “УМХЫБФШ” ЧИПДСЭЙЕ
УПЕДЙОЕОЙС Й Socket - ЙУРПМШЪХЕФУС ЛМЙЕОФПН ДМС ЙОЙГЙЙТПЧБОЙС УПЕДЙОЕОЙС.
лБЛ ФПМШЛП ЛМЙЕОФ УПЪДБЕФ УПЕДЙОЕОЙЕ РП УПЛЕФХ, ServerSocket ЧПЪЧТБЭБЕФ
(У РПНПЭША НЕФПДБ accept( ) )
УППФЧЕФУФЧХАЭЙК ПВЯЕЛФ Socket РП ЛПФПТПНХ ВХДЕФ РТПЙУИПДЙФШ УЧСЪШ ОБ
УФПТПОЕ УЕТЧЕТБ. оБЮЙОБС У ЬФПЗП НПНЕОФБ, Х чБУ РПСЧМСЕФУС УПЕДЙОЕОЙЕ Socket
Л Socket, Й чЩ УЮЙФБЕФЕ ЬФЙ УПЕДЙОЕОЙС ПДЙОБЛПЧЩНЙ, РПФПНХ ЮФП ПОЙ
ДЕКУФЧЙФЕМШОП ПДЙОБЛПЧЩЕ. ч ТЕЪХМШФБФЕ, чЩ ЙУРПМШЪХЕФЕ НЕФПДЩ getInputStream( )
Й getOutputStream( )
ДМС УПЪДБОЙС УППФЧЕФУФЧХАЭЙИ ПВЯЕЛФПЧ InputStream Й OutputStream
ЙЪ ЛБЦДПЗП Socket. пОЙ ДПМЦОЩ ВЩФШ ПВЕТОХФЩ ЧОХФТЙ ВХЖЕТПЧ Й ЖПТНБФЙТХАЭЙИ
ЛМБУУПЧ, ЛБЛ Й МАВПК ДТХЗПК РПФПЛПЧЩК ПВЯЕЛФ, ПРЙУБООЩК Ч зМБЧЕ 11.
ServerSocket НПЦЕФ РПЛБЪБФШУС ЕЭЕ ПДОЙН РТЙНЕТПН
ЪБРХФБООПК УИЕНЩ ЙНЕО Ч ВЙВМЙПФЕЛБИ Java. чЩ НПЦЕФЕ РПДХНБФШ, ЮФП ServerSocket
МХЮЫЕ ОБЪЧБФШ “ServerConnector” МЙВП ЛБЛ-ОЙВХДШ ЙОБЮЕ ВЕЪ УМПЧБ
“Socket” Ч ОЕН. чЩ ФБЛЦЕ НПЦЕФЕ РПДХНБФШ, ЮФП ServerSocket
Й Socket ДПМЦОЩ ВЩФШ ПВБ ХОБУМЕДПЧБОЩ ПФ ПДОПЗП ЙЪ ВБЪПЧЩИ ЛМБУУПЧ.
ч УБНПН ДЕМЕ, ПВБ ЛМБУУБ УПДЕТЦБФ ОЕУЛПМШЛП НЕФПДПЧ УПЧНЕУФОП, ОП ЬФПЗП ОЕДПУФБФПЮОП,
ЮФПВЩ ДБФШ ЙН ПВЭЙК ВБЪПЧЩИ ЛМБУУ. чЪБНЕО, ТБВПФБ ServerSocket ПЦЙДБФШ,
РПЛБ ОЕ РПДУПЕДЙОЙФУС ДТХЗБС НБЫЙОБ, Й ЪБФЕН ЧПЪЧТБФЙФШ РПДМЙООЩК Socket.
чПФ РПЮЕНХ ServerSocket ЛБЦЕФУС ОЕНОПЗП ОЕРТБЧЙМШОП ОБЪЧБООЩН, Ф.Л.
ЕЗП ТБВПФБ Ч ДЕКУФЧЙФЕМШОПУФЙ ОЕ ВЩФ УПЛЕФПН, Б РТПУФП УПЪДБЧБФШ ПВЯЕЛФ Socket,
ЛПЗДБ ЛФП-ФП ДТХЗПК Л ОЕНХ РПДЛМАЮБЕФУС.
пДОБЛП ServerSocket УПЪДБЕФ ЖЙЪЙЮЕУЛЙК “УЕТЧЕТ”
МЙВП УМХЫБАЭЙК УПЛЕФ ОБ УЕТЧЕТОПК НБЫЙОЕ. ьФПФ УПЛЕФ УМХЫБЕФ ЧИПДСЭЙЕ УПЕДЙОЕОЙС
Й ЪБФЕН ЧПЪЧТБЭБЕФ “ХУФБОПЧМЕООЩК” УПЛЕФ (У ПРТЕДЕМЕООЩНЙ МПЛБМШОЩНЙ
Й ХДБМЕООЩНЙ ЛПОЕЮОЩНЙ ФПЮЛБНЙ) РПУТЕДУФЧПН НЕФПДБ accept( ).
ч ЪБНЕЫБФЕМШУФЧП РТЙЧПДЙФ ФП, ЮФП ПВБ ЬФЙИ УПЛЕФБ (УМХЫБАЭЙК Й ХУФБОПЧМЕООЩК)
БУУПГЙЙТПЧБОЩ У ФЕН ЦЕ УБНЩН УЕТЧЕТОЩН УПЛЕФПН. уМХЫБАЭЙК УПЛЕФ НПЦЕФ ДПРХУФЙФШ
ФПМШЛП ЪБРТПУЩ ОБ ОПЧПЕ УПЕДЙОЕОЙЕ ОП ОЕ РБЛЕФЩ ДБООЩИ. йФБЛ, РПЛБ ServerSocket
ОЕ ЙНЕЕФ УНЩУМБ РТПЗТБННОПЗП, ЪБФП ЙНЕЕФ УНЩУМ “ЖЙЪЙЮЕУЛЙК”.
лПЗДБ чЩ УПЪДБЕФЕ ServerSocket, чЩ ЪБДБЕФЕ ДМС
ОЕЗП ФПМШЛП ОПНЕТ РПТФБ. чБН ОЕ ОХЦОП ЪБДБЧБФШ IP БДТЕУ, Ф.Л. ПО ХЦЕ УХЭЕУФЧХЕФ
ОБ НБЫЙОЕ. пДОБЛП ЛПЗДБ чЩ УПЪДБЕФЕ Socket, чЩ ДПМЦОЩ ЪБДБФШ Й IP БДТЕУ
Й ОПНЕТ РПТФБ НБЫЙОЩ, У ЛПФПТПК чЩ ИПФЙФЕ УПЕДЙОЙФШУС. (фЕН ОЕ НЕОЕЕ, Socket
ЛПФПТЩК ЧПЪЧТБЭБЕФУС НЕФПДПН ServerSocket.accept( ) ХЦЕ УПДЕТЦЙФ
ЧУА ЬФХ ЙОЖПТНБГЙА.)
ьФПФ РТЙНЕТ РПЛБЪЩЧБЕФ РТПУФХА ТБВПФХ УЕТЧЕТБ Й ЛМЙЕОФБ
ЙУРПМШЪХС УПЛЕФЩ. чУЕ, ЮФП ДЕМБЕФ УЕТЧЕТ - ЬФП РТПУФП ПЦЙДБОЙЕ УПЕДЙОЕОЙС,
ЪБФЕН ЙУРПМШЪХЕФ Socket РПМХЮЕООЩК ЙЪ ФПЗП УПЕДЙОЕОЙС ДМС УПЪДБОЙС
InputStream Й OutputStream. пОЙ ЛПОЧЕТФЙТХАФУС Ч Reader
Й Writer, ЪБФЕН Ч BufferedReader Й PrintWriter. рПУМЕ
ЬФПЗП, ЧУЕ ЮФП ПО РПМХЮБЕФ ЙЪ BufferedReader ПО ПФРТБЧМСЕФ ОБ PrintWriter
РПЛБ ОЕ РПМХЮЙФ УФТПЛХ “END,” РПУМЕ ЮЕЗП, ПО ЪБЛТЩЧБЕФ УПЕДЙОЕОЙЕ.
лМЙЕОФ ХУФБОБЧМЙЧБЕФ УПЕДЙОЕОЙЕ У УЕТЧЕТПН, ЪБФЕН УПЪДБЕФ
OutputStream Й ЧЩРПМОСЕФ ФЕ ЦЕ ПРЕТБГЙЙ, ЮФП Й УЕТЧЕТ. уФТПЛЙ ФЕЛУФБ
РПУЩМБАФУС ЮЕТЕЪ ТЕЪХМШФЙТХАЭЙК PrintWriter. лМЙЕОФ ФБЛЦЕ УПЪДБЕФ InputStream
(УОПЧБ, У УППФЧЕФУФЧХАЭЙНЙ ЛПОЧЕТУЙСНЙ Й ПВМБЮЕОЙСНЙ) ЮФПВЩ УМХЫБФШ, ЮФП ЗПЧПТЙФ
УЕТЧЕТ (Б Ч ОБЫЕН УМХЮБЕ ПО ЧПЪЧТБЭБЕФ УМПЧБ ОБЪБД).
й УЕТЧЕТ, Й ЛМЙЕОФ ЙУРПМШЪХАФ ПДЙО Й ФПФ ЦЕ ОПНЕТ РПТФБ,
Б ЛМЙЕОФ ЙУРПМШЪХЕФ БДТЕУ МПЛБМШОПК РЕФМЙ ДМС УПЕДЙОЕОЙС У УЕТЧЕТПН ОБ ФПК
ЦЕ НБЫЙОЕ, ФБЛ ЮФП чБН ОЕ ОХЦОП ФЕУФЙТПЧБФШ ЬФП Ч УЕФЙ. (дМС ОЕЛПФПТЩИ ЛПОЖЙЗХТБГЙК,
чБН ОЕ ОХЦОП ВХДЕФ РПДЛМАЮБФШУС Л УЕФЙ, ЮФПВЩ РТПЗТБННБ ТБВПФБМБ, ДБЦЕ ЕУМЙ
чЩ ПВЭБЕФЕУШ РП УЕФЙ.)
чПФ УЕТЧЕТ:
//: c15:JabberServer.java
// пЮЕОШ РТПУФПК УЕТЧЕТ, ЛПФПТЩК ФПМШЛП
// ПФПВТБЦБЕФ ФП, ЮФП РПУЩМБЕФ ЛМЙЕОФ.
import java.io.*;
import java.net.*;
public class JabberServer {
// чЩВЙТБЕН ОПНЕТ РПТФБ ЪБ РТЕДЕМБНЙ 1-1024:
public static final int PORT = 8080;
public static void main(String[] args)
throws IOException {
ServerSocket s = new ServerSocket(PORT);
System.out.println("Started: " + s);
try {
// вМПЛЙТХЕН РПЛБ ОЕ РТПЙЪПКДЕФ УПЕДЙОЕОЙЕ:
Socket socket = s.accept();
try {
System.out.println(
"Connection accepted: "+ socket);
BufferedReader in =
new BufferedReader(
new InputStreamReader(
socket.getInputStream()));
// чЩЧПД БЧФПНБФЙЮЕУЛЙ ПВОПЧМСЕФУС
// ЛМБУУПН PrintWriter:
PrintWriter out =
new PrintWriter(
new BufferedWriter(
new OutputStreamWriter(
socket.getOutputStream())),true);
while (true) {
String str = in.readLine();
if (str.equals("END")) break;
System.out.println("Echoing: " + str);
out.println(str);
}
// ЧУЕЗДБ ЪБЛТЩЧБЕН ПВБ УПЛЕФБ...
} finally {
System.out.println("closing...");
socket.close();
}
} finally {
s.close();
}
}
} ///:~
чЩ ЧЙДЙФЕ, ЮФП ПВЯЕЛФХ ServerSocket ОХЦЕО ФПМШЛП
ОПНЕТ РПТФБ, ОЕ IP БДТЕУ (Ф.Л. ПО ЪБРХЭЕО ОБ ЬФПК НБЫЙОЕ!). лПЗДБ чЩ
ЧЩЪЩЧБЕФЕ НЕФПД accept( ), НЕФПД ВМПЛЙТХЕФ ЧЩРПМОЕОЙЕ РТПЗТБННЩ,
РПЛБ ЛБЛПК-ОЙВХДШ ЛМЙЕОФ ОЕ РПРТПВХЕФ УПЕДЙОЙФШУС. фП ЕУФШ, ПО ПЦЙДБЕФ УПЕДЙОЕОЙЕ,
ОП ДТХЗЙЕ РТПГЕУУЩ НПЗХФ ЧЩРПМОСФШУС (УН. зМБЧХ 14). лПЗДБ УПЕДЙОЕОЙЕ УДЕМБОП,
accept( ) ЧПЪЧТБЭБЕФ ПВЯЕЛФ Socket РТЕДУФБЧМСАЭЙК ЬФП УПЕДЙОЕОЙЕ.
пФЧЕФУФЧЕООПУФШ ЪБ ПЮЙЭЕОЙЕ УПЛЕФПЧ is crafted carefully
here. еУМЙ ЛПОУФТХЛФПТ ServerSocket ЪБЧЕТЫБЕФУС ОЕХУРЕЫОП, РТПЗТБННБ
РТПУФП ЪБЧЕТЫБЕФУС (ПВТБФЙФЕ ЧОЙЧБОЙЕ, ЮФП НЩ ДПМЦОЩ УЮЙФБФШ ЮФП ЛПОУФТХЛФПТ
ServerSocket ОЕ ПУФБЧМСЕФ ПФЛТЩФЩИ УЕФЕЧЩИ УПЛЕФПЧ ЕУМЙ ПО ЪБЧЕТЫБЕФУС
ОЕХДБЮОП). ч ЬФПН УМХЮБЕФ, main( ) ЧЩВТБУЩЧБЕФ ЙУЛМАЮЕОЙЕ IOException
Й ВМПЛ try ОЕ ПВСЪБФЕМЕО. еУМЙ ЛПОУФТХЛФПТ ServerSocket ЪБЧЕТЫБЕФУС
ХУРЕЫОП, ФП ПУФБМШОЩЕ ЧЩЪПЧЩ НЕФПДПЧ ДПМЦОЩ ВЩФШ ПЛТХЦЕОЩ ВМПЛБНЙ try-finally,
ЮФПВЩ ХВЕДЙФШУС, ЮФП ОЕЪБЧЙУЙНП ПФ ФПЗП ЛБЛ ВМПЛ ЪБЧЕТЫЙФ ТБВПФХ, ServerSocket
ВХДЕФ ЛПТТЕЛФОП ЪБЛТЩФ.
фБ ЦЕ МПЗЙЛБ ЙУРПМШЪХЕФУС ДМС Socket ЧПЪЧТБЭБЕНПЗП
НЕФПДПН accept( ). еУМЙ ЧЩЪПЧ accept( ) ОЕХУРЕЫОЩК,
ФП НЩ ДПМЦОЩ УЮЙФБФШ ЮФП Socket ОЕ УХЭЕУФЧХЕФ Й ОЕ ДЕТЦЙФ ОЙЛБЛЙИ ТЕУХТУПЧ,
ФБЛ ЮФП ПО ОЕ ОХЦДБЕФУС Ч ПЮЙУФЛЕ. оП, ЕУМЙ ЧЩЪПЧ ХУРЕЫОЩК, УМЕДХАЭЙ ПВЯСЧМЕОЙС
ДПМЦОЩ ВЩФШ ПЛТХЦЕОЩ ВМПЛБНЙ try-finally ФБЛ ЮФП Ч УМХЮБЕ ОЕХУРЕЫОПЗП
ЧЩЪПЧБ Socket ВХДЕФ ПЮЙЭЕО. ъБВПФЙФШУС ЪДЕУШ ПВ ЬФПН ПВСЪБФЕМШОП, Ф.Л.
УПЛЕФЩ ЙУРПМШЪХАФ ЧБЦОЩЕ ТЕУХТУЩ ТБУРПМБЗБАЭЙЕУС ОЕ Ч РБНСФЙ, ФБЛ ЮФП чЩ ДПМЦОЩ
ФЭБФЕМШОП ПЮЙЭБФШ ЙИ (РПУЛПМШЛХ Ч Java ОЕФ ДЕУФТХЛФПТБ, ЮФПВЩ УДЕМБФШ ЬФП
ЪБ чБУ).
й ServerSocket Й Socket УПЪДБООЩЕ НЕФПДПН
accept( ) РЕЮБФБАФУС Ч System.out. ьФП ЪОБЮЙФ, ЮФП ЙИ НЕФПДЩ
toString( ) ЧЩЪЩЧБАФУС БЧФПНБФЙЮЕУЛЙ. чПФ ЮФП РПМХЮБЕФУС:
ServerSocket[addr=0.0.0.0,PORT=0,localport=8080] Socket[addr=127.0.0.1,PORT=1077,localport=8080]
уЛПТП чЩ ХЧЙДЙФЕ ЛБЛ how ПОЙ ПВЯЕДЙОСАФУС ЧНЕУФЕ У ФЕН
ЮФП ДЕМБЕФ ЛМЙЕОФ.
уМЕДХАЭБС ЮБУФШ РТПЗТБННЩ ЧЩЗМСДЙФ ЛБЛ РТПЗТБННБ ДМС
ДМС ПФЛТЩФЙС ЖБКМПЧ ДМС ЮФЕОЙС Й ЪБРЙУЙ ЪБ ЙУЛМАЮЕОЙЕН ФПЗП, ЮФП InputStream
Й OutputStream УПЪДБАФУС ЙЪ ПВЯЕЛФБ Socket. й ПВЯЕЛФ InputStream
Й ПВЯЕЛФ OutputStream ЛПОЧЕТФЙТХАФУС Ч ПВЯЕЛФЩ Reader
Й Writer ЙУРПМШЪХС
ЛМБУУЩ “ЛПОЧЕТФЕТЩ” InputStreamReader
Й OutputStreamWriter,
УППФЧЕФУФЧЕООП. чЩ НПЦЕФЕ ФБЛЦЕ ЙУРПМШЪПЧБФШ ОБРТСНХА ЛМБУУЩ ЙЪ Java 1.0 InputStream
Й OutputStream, ОП
У ЧЩЧПДПН ЕУФШ СЧОПЕ РТЕЙНХЭЕУФЧП РТЙ ЙУРПМШЪПЧБОЙЙ Writer. ьФП ТЕБМЙЪХЕФУС
У РПНПЭША PrintWriter,
Ч ЛПФПТПН РЕТЕЗТХЦЕООЩК ЛПОУФТХЛФПТ ВЕТЕФ ЧФПТПК БТЗХНЕОФ, Б boolean ЖМБЗ
ЛПФПТЩК ЙОДЙГЙТХЕФ ЛПЗДБ ЛБЛПК БЧФПНБФЙЮЕУЛЙ УВТБУЩЧБЕФ ЧЩЧПД Ч ЛПОГЕ ЛБЦДПЗП
ЧЩЧПДБ println( ) (ОП ОЕ print( )) ЧЩТБЦЕОЙС.
лБЦДЩК ТБЪ, ЛПЗДЩ чЩ ОБРТБЧМСЕФЕ ДБООЩЕ Ч out, ЕЗП ВХЖЕТ ДПМЦЕО УВТБУЩЧБФШУС
ФБЛ ЙОЖПТНБГЙС РЕТЕДБЕФУС П УЕФЙ. уВТПУ ЧБЦЕО ДМС ЬФПЗП ЛПОЛТЕФОПЗП РТЙНЕТБ,
Ф.Л. ЛМЙЕОФ Й УЕТЧЕТ ЦДХФ УФТПЛХ ДБООЩИ ДТХЗ ПФ ДТХЗБ, РЕТЕД ФЕН, ЛБЛ ЮФП-ФП
УДЕМБФШ. еУМЙ УВТПУБ ВХЖЕТПЧ ОЕ РТПЙУИПДЙФ, ЙОЖПТНБГЙС ОЕ ВХДЕФ ПФРТБЧМЕОБ
РП УЕФЙ, РПЛБ ВХЖЕТ РПМПО, ЮФП ЧЩЪПЧЕН НОПЗП РТПВМЕН Ч ЬФПН РТЙНЕТЕ.
рТЙ ОБРЙУБОЙЙ УЕФЕЧЩИ РТПЗТБНН чЩ ДПМЦОЩ ВЩФШ ЧОЙНБФЕМШОЩНЙ,
РТЙЙУРПМШЪПЧБОЙЙ БЧФПНБФЙЮЕУЛПЗП УВТПУБ ВХЖЕТПЧ. лБЦДЩК ТБЪ, ЛПЗДБ чЩ УВТБУЩЧБЕФЕ
ВХЖЕТ, РБЛЕФ ДПМЦЕО УПЪДБФШУС Й ПФРТБЧЙФШУС. ч ЬФПН УМХЮБЕ, ЬФП ЙНЕООП ФП,
ЮФП НЩ ИПФЙН, Ф.Л. ЕУМЙ РБЛЕФ, УПДЕТЦБЭЙК УФТПЛХ ОЕ ПФПУМБО ФП ПВНЕО ЙОЖПТНБГЙЕК
НЕЦДХ УЕТЧЕТПН Й ЛМЙЕОФПН ПУФБОПЧЙФУС. у ДТХЗПК УФПТПОЩ, ЛПОЕГ УФТПЛЙ ЬФП
ЛПОЕГ УППВЭЕОЙС. оП ЧП НОПЗЙИ УМХЮБСИ, УППВЭЕОЙС ОЕ ПЗТБОЙЮЙЧБАФУС УФТПЛБНЙ,
ФБЛ ЮФП ВПМЕЕ ЬЖЖЕЛФЙОП ВХДЕФ ОЕ ЙУРПМШЪПЧБФШ БЧФПНБФЙЮЕУЛЙК УВТПУ, Б РПЪЧПМЙФШ
ЧУФТПЕООПК ВХЖЕТЙЪБГЙЙ ТЕЫБФШ, ЛПЗДБ ОЕПВИПДЙНП УПЪДБФШ Й ПФПУМБФШ РБЛЕФЩ.
ч ЬФПН УМХЮБЕ, НПЗХФ ПФУЩМБФШУС ВПМШЫЙЕ РБЛЕФЩ Й РТПГЕУУ РПКДЕФ ВЩУФТЕЕ.
ъБРПНОЙФЕ, ЧУЕ РПФПЛЙ, ЛПФПТЩЕ чЩ ПФЛТЩЧБЕФЕ, ВХЖЕТЙЪПЧБОЩ.
ч ЛПОГЕ ЬФПК ЗМБЧЩ ЕУФШ ХРТБЦОЕОЙЕ, РПЛБЪЩЧБАЭЕЕ чБН, ЮФП РТПЙУИПДЙФ, ЕУМЙ
чЩ ОЕ ВХЖЕТЙЪХЕФЕ РПФПЛЙ (ЧУЕ ЪБНЕДМСЕФУС).
вЕУЛПОЕЮОЩК ГЙЛМ while ЮЙФБЕФ УФТПЛЙ ЙЪ BufferedReader
in Й ЪБРЙУЩЧБЕФ ЙОЖПТНБГЙА ЧSystem.out and to the PrintWriter
out. ъБРПНОЙФЕ, ЮФП in Й out НПЗХФ ВЩФШ МАВЩНЙ РПФПЛБНЙ,
ПОЙ РТПУФП УПЕДЙОЕОЩ Ч УЕФЙ.
лПЗДБ ЛМЙЕОФ ПФУЩМБЕФ УФТПЛХ, УПУФПСЭХА ЙЪ “END,”
РТПЗТБННБ РТЕТЩЧБЕФ ЧЩРПМОЕОЙЕ ГЙЛМБ Й ЪБЛТЩЧБЕФ Socket.
чПФ ЛМЙЕОФ:
//: c15:JabberClient.java
// пЮЕОШ РТПУФПК ЛМЙЕОФ, ЛПФПТЩК РТПУФП ПФУЩМБЕФ УФТПЛЙ УЕТЧЕТХ
// Й ЮЙФБЕФ УФТПЛЙ, ЛПФПТЩЕ РПУЩМБЕФ УЕТЧЕТ
import java.net.*;
import java.io.*;
public class JabberClient {
public static void main(String[] args)
throws IOException {
// хУФБОПЧЛБ РБТБНЕФТБ Ч null Ч getByName()
// ЧПЪЧТБЭБЕФ УРЕГЙБМШОЩК IP address - "мПЛБМШОХА РЕФМА",
// ДМС ФЕУФЙТПЧБОЙС ОБ ПДОПК НБЫЙОЕ ВЕЪ ОБМЙЮЙС УЕФЙ
InetAddress addr =
InetAddress.getByName(null);
// бМШФЕТОБФЙЧОП чЩ НПЦЕФЕ ЙУРПМШЪПЧБФШ
// БДТЕУ ЙМЙ ЙНС:
// InetAddress addr =
// InetAddress.getByName("127.0.0.1");
// InetAddress addr =
// InetAddress.getByName("localhost");
System.out.println("addr = " + addr);
Socket socket =
new Socket(addr, JabberServer.PORT);
// пЛТХЦБЕН ЧУЕ ВМПЛБНЙ try-finally to make
// ЮФПВЩ ХВЕДЙФШУС ЮФП УПЛЕФ ЪБЛТЩЧБЕФУС:
try {
System.out.println("socket = " + socket);
BufferedReader in =
new BufferedReader(
new InputStreamReader(
socket.getInputStream()));
// чЩЧПД БЧФПНБФЙЮЕУЛЙ УВТБУЩЧБЕФУС
// У РПНПЭША PrintWriter:
PrintWriter out =
new PrintWriter(
new BufferedWriter(
new OutputStreamWriter(
socket.getOutputStream())),true);
for(int i = 0; i < 10; i ++) {
out.println("howdy " + i);
String str = in.readLine();
System.out.println(str);
}
out.println("END");
} finally {
System.out.println("closing...");
socket.close();
}
}
} ///:~
ч НЕФПДЕ main( ) чЩ ЧЙДЙФЕ ЧУЕ ФТЙ РХФЙ
ДМС ЧПЪЧТБФБ IP БДТЕУБ МПЛБМШОПК РЕФМЙ: ЙУРПМШЪХС null, localhost,
МЙВП СЧОП ЪБТЕЪЕТЧЙТПЧБООЩК БДТЕУ 127.0.0.1. лПОЕЮОП, ЕУМЙ чЩ ИПФЙФЕ
УПЕДЙОЙФШУС У НБЫЙОПК Ч УЕФЙ чЩ РПДУФБЧМСЕФЕ IP БДТЕУ ЬФПК НБЫЙОЩ. лПЗДБ InetAddress
addr РЕЮБФБЕФУС (У РПНПЭША БЧФПНБФЙЮЕУЛПЗП ЧЩЪПЧБ НЕФПДБ toString( ))
РПМХЮБЕФУС УМЕДХАЭЙК ТЕЪХМШФБФ:
localhost/127.0.0.1
рПДУФБОПЧЛПК РБТБНЕФТБ null Ч getByName( ),
ПОБ РП ХНПМЮБОЙА ЙУРПМШЪХЕФ localhost, Й ЬФП УПЪДБЕФ УРЕГЙБМШОЩК БДТЕУ
127.0.0.1.
пВТБФЙФЕ ЧОЙНБОЙЕ, ЮФП Socket
ОБЪЧБООЩК socket УПЪДБЕФУС Й У ФЙРПН InetAddress Й У ОПНЕТПН
РПТФБ. юФПВЩ РПОЙНБФШ, ЮФП ЬФП ЪОБЮЙФ, ЛЗДБ чЩ РЕЮБЕФЕ ПДЙО ЙЪ ЬФЙИ ПВЯЕЛФПЧ
Socket, РПНОЙФЕ, ЮФП УПЕДЙОЕОЙЕ У йОФЕТОЕФ ПРТЕДЕМСЕФУС ХОЙЛБМШОП ЬФЙНЙ
ЮЕФЩТШНС ЬМЕНЕОФБНЙ ДБООЩИ: clientHost, clientPortNumber, serverHost,
Й serverPortNumber. лПЗДБ УЕТЧЕТ ЪБРХУЛБЕФУС, ПО ВЕТЕФ РТЙУЧПЕООЩК
ЕНХ РПТФ (8080) ОБ localhost (127.0.0.1). лПЗДБ ЛМЙЕОФ РТЙИПДЙФ, ТБУРТЕДЕМСЕФУС
УМЕДХАЭЙК ДПУФХРОЩК РПТФ ОБ ФПК ЦЕ НБЫЙОЕ, Ч ОБЫЕН УМХЮБЕ - 1077, ЛПФПТЩК,
ФБЛ УМХЮЙМПУШ, ПЛБЪБМУС ТБУРПМПЦЕО ОБ ФПК ЦЕ УБНПК НБЫЙОЕ (127.0.0.1), ЮФП
Й УЕТЧЕТ. фЕРЕТШ, ОЕПВИПДЙНП ДБООЩЕ РЕТЕНЕЭБФШ НЕЦДХ ЛМЙЕОФПН Й УЕТЧЕТПН,
ЛБЦДБС УФПТПОБ ДПМЦОЧБ ЪОБФШ, ЛХДБ ЙИ РПУЩМБФШ. рПЬФПНХ, ЧП ЧТЕНС РТПГЕУУБ
УПЕДЙОЕОЙС У “ЙЪЧЕУФОЩН” УЕТЧЕТПН, ЛМЙЕОФ РПУЩМБЕФ “ПВТБФОЩК
БДТЕУ”, ФБЛ ЮФП УЕТЧЕТ ЪОБЕФ, ЛХДБ ПФУЩМБФШ ЕЗП ДБООЩЕ. чПФ, ЮФП чЩ
ЧЙДЙФЕ Ч РТЙНЕТЕ УЕТЧЕТОПК ЮБУФЙ:
Socket[addr=127.0.0.1,port=1077,localport=8080]
ьФП ЪОБЮЙФ, ЮФП УЕТЧЕТ ФПШМЛП ЮФП РТЙОСМ УПЕДЙОЕОЙЕ
У БДТЕУБ 127.0.0.1 Й РПТФБ 1077 ЛПЗДБ УМХЫБМ УЧПК МПЛБМШОЩК РПТФ (8080). оБ
УФПТПОЕ ЛМЙЕОФБ:
Socket[addr=localhost/127.0.0.1,PORT=8080,localport=1077]
ЬФП ЪОБЮЙФ, ЮФП ЛМЙЕОФ УПЪДБМ УПЕДЙОЕОЙЕ У БДТЕУПН 127.0.0.1
Й РПТФПН 8080, ЙУРПМШЪХС МПЛБМШОЩК РПТФ 1077.
чЩ ХЧЙДЙФЕ, ЮФП ЛБЦДЩК ТБЪ, ЛПЗДБ чЩ ЪБРХУЛБЕФЕ ОПЧПЗП
ЛМЙЕОФБ, ОПНЕТ МПЛБМШОПЗП РПТФБ ХЧЕМЙЮЙЧБЕФУС. пФУЮЕФ ОБЮЙОБЕФУС У 1025 (РТЕДЩДХЭЙЕ
СЧМСАФУС ЪБТЕЪЕТЧЙТПЧБООЩНЙ) Й РТПДПМЦБЕФУС ДП ФПЗП НПНЕОФБ, РПЛБ чЩ ОЕ РЕТЕЪБЗТХЪЙФЕ
НБЫЙОХ, РПУМЕ ЮЕЗП ПО УОПЧБ ОБЮЙОБЕФУС У 1025. (оБ UNIX НБЫЙОБИ, ЛБЛ ФПМШЛП
ДПУФЙЗБЕФУС НБЛУЙНБМШОПЕ ЮЙУМП УПЛЕФПЧ, ОХНЕТБГЙС ОБЮЙОБЕФУС У УБНПЗП НЕОШЫЕЗП
ДПУФХРОПЗП ОПНЕТБ.)
лБЛ ФПМШЛП ПВЯЕЛФ Socket УПЪДБО, РТПГЕУУ РТЕЧПДБ
ЕЗП Ч BufferedReader Й PrintWriter ФПФ ЦЕ УБНЩК, ЮФП Й Ч УЕТЧЕТОПК
ЮБУФЙ (УОПЧБ, Ч ПВПЙИ УМХЮБСИ чЩ ОБЮЙОБЕФЕ У Socket). ъДЕУШ, ЛМЙЕОФ
ЙОЙГЙЙТХЕФ УПЕДЙОЕОЙЕ ПФУЩМЛПК УФТПЛЙ “howdy” УМЕДХАЭЕ ЪБ ОПНЕТПН.
пВТБФЙФЕ ЧОЙНБОЙЕ, ЮФП ВХЖЕТ ДПМЦЕО ВЩФШ УОПЧБ УВТПЫЕО (ЮФП РТПЙУИПДЙФ БЧФПНБФЙЮЕУЛЙ
РП ЧФПТПНХ БТЗХНЕОФХ Ч ЛПОУФТХЛФПТЕ PrintWriter). еУМЙ ВХЖЕТ ОЕ ВХДЕФ
УВТПЫЕО, ЧУЕ ПВЭЕОЙЕ ЪБЧЙУОЕФ, Ф.Л. УФТПЛБ “howdy” ОЙЛПЗДБ ОЕ
ВХДЕФ ПФПУМБОБ (ВХЖЕТ ОЕ ВХДЕФ ДПУФБФПЮОП РПМОЩН, ЮФПВЩ ЧЩРПМОЙФШ ПФУЩМЛХ
БЧФПНБФЙЮЕУЛЙ). лБЦДБС УФТПЛБ, ПФУЩМБЕНБС УЕТЧЕТПН ПВТБФОП ЪБРЙУЩЧБЕФУС Ч
System.out ДМС РТПЧЕТЛЙ, ЮФП ЧУЕ ТБВПФБЕФ РТБЧЙМШОП. дМС РТЕЛТБЭЕОЙС
ПВЭЕОЙС, ПФУЩМБЕФУС ХУМПЧОЩК ЪОБЛ - УФТПЛБ “END”. еУМЙ ЛМЙЕОФ
РТЕТЧЩЧБЕФ УПЕДЙОЕОЙЕ, ФП УЕТЧЕТ ЧЩВТБУЩЧБЕФ ЙУЛМАЮЕОЙЕ.
чЩ ЧЙДЙФЕ, ЮФП ФБЛБС ЦЕ ЪБВПФБ ЪДЕУШ ФПЦЕ РТЙУХФУФЧХЕФ,
ЮФПВЩ ХВЕДЙФШУС, ЮФП ТЕУХТУЩ РТЕДУФБЧМЕООЩЕ Socket ЛПТТЕЛФОП ПУЧПВПЦДБАФУС,
У РПНПЭША ВМПЛБ try-finally.
уПЛЕФЩ УПЪДБАФ “РПДРЙУБООПЕ”
(dedicated) УПЕДЙОЕОЙЕ, ЛПФПТПЕ УПИТБОСЕФУС, РПЛБ ОЕ РТПЙЪПКДЕФ СЧОЩК ТБЪТЩЧ
УПЕДЙОЕОЙС. (рПДРЙУБООПЕ УПЕДЙОЕОЙЕ НПЦЕФ ЕЭЕ ВЩФШ ТБЪПТЧБОП ОЕСЧОП, ЕУМЙ
ПДОБ УФПТПОБ , МЙВП РТПНЕЦХФПЮОПЕ УПЕДЙОЕОЙЕ, ТБЪТХЫБЕФУС.) ьФП ЪОБЮЙФ, ЮФП
ПВЕ УФПТПОЩ ЪБВМПЛЙТПЧБОЩ Ч ПВЭЕОЙЙ Й УПЕДЙОЕОЙЕ РПУФПСООП ПФЛТЩФП. лБЦЕФУС,
ЮФП ЬФП РТПУФП МПЗЙЮЕУЛЙК РПДИПД Л РЕТЕДБЮЕ ДБООЩИ, ПДОБЛП ЬФП ДБЕФ ДПРПМОЙФЕМШОХА
ОБЗТХЪЛХ ОБ УЕФШ. рПЪЦЕ, Ч ЬФПК ЗМБЧЕ чЩ ХЧЙДЙФЕ ДТХЗПК НЕФПД РЕТЕДБЮЙ ДБООЩИ
РП УЕФЙ, Ч ЛПФПТПН УПЕДЙОЕОЙС СЧМСАФУС ЧТЕНЕООЩНЙ.
JabberServer ТБВПФБЕФ, ОП ПО НПЦЕФ ПВУМХЦЙЧБФШ
ФПМШЛП ПДОПЗП ЛМЙЕОФБ ПДОПЧТЕНЕООП. ч ФЙРЙЮОПН УЕТЧЕТЕ, чЩ ЪБИПФЙФЕ ЙНЕФШ
ЧПЪНПЦОПУФШ ПВЭБФШУС УП ОЕУЛПМШЛЙНЙ ЛМЙЕОФБНЙ ПДОПЧТЕНЕООП. тЕЫЕОЙЕ - ЬФП
НОПЗП РПФПЮОПУФШ, Б Ч СЪЩЛБИ,
ЛПФПТЩЕ ОБРТСНХА ОЕ РПДДЕТЦЙЧБАФ НОПЗПРПФПЮОПУФШ ЬФП ПЪОБЮБЕФ ЧУЕ ЧЙДЩ УМПЦОПУФЕК.
ч зМБЧЕ 14 чЩ ХЧЙДЕМЙ, ЮФП НОПЗПРПФПЮОПУФШ Ч Java ОБУФПМШЛП РТПУФП, ОБУЛПМШЛП
ЬФП ЧПЪНПЦОП, Ч ФП ЧТЕНС, ЛБЛ НОПЗПРПФПЮОПУФШ ЧППВЭЕ СЧМСЕФУС УМПЦОПК ФЕНПК.
ф.Л. РПДДЕТЛБ ОЙФЕК Ч Java СЧМСЕФУС РТСНПК Й ПФЛТЩФПК, ФП УПЪДБОЙЕ УЕТЧЕТБ,
РПДДЕТЦЙЧБАЭЕЗП НОПЦЕУФЧП ЛМЙЕОФПЧ ПЛБЪЩЧБЕФУС ПФОПУЙФЕМШОП РТПУФПК ЪБДБЮЕК.
пУОПЧОБС УИЕНБ ЬФП УПЪДБОЙЕ ЕДЙОЙЮОПЗП ПВЯЕЛФБ ServerSocket
Ч УЕТЧЕТОПК ЮБУФЙ Й ЧЩЪЧБФШ НЕФПД accept( ) ДМС ПЦЙДБОЙС ОПЧПЗП
УПЕДЙОЕОЙС. лПЗДБ accept( ) ЧПЪЧТБЭБЕФ ХРТБЧМЕОЙС, чЩ ВЕТЕФЕ ЧПЪЧТБЭЕООЩК
Socket Й ЙУРПМШЪХЕФЕ ЕЗП ДМС УПЪДБОЙС ОПЧПК ОЙФЙ(РПФПЛБ), ЮШЕК ТБВПФПК
СЧМСЕФУС ПВУМХЦЙЧБОЙЕ ЬФПЗП ЛМЙЕОФБ. ъБФЕН чЩ ЧЩЪЩЧБЕФЕ НЕФПД accept( )
УОПЧБ, ДМС ПЦЙДБОЙС ОПЧПЗП ЛМЙЕОФБ.
ч УМЕДХАЭЕН ЛПДЕ УЕТЧЕТОПК ЮБУФЙ чЩ ХЧЙДЙФЕ, ЮФП ЬФП
ЧЩЗМСДЙФ ФБЛЦЕ ЛБЛ Й Ч РТЙНЕТЕ JabberServer.java ЪБ ЙУЛМАЮЕОЙЕН ФПЗП,
ЮФП ЧУЕ ПРЕТБГЙЙ РП ПВУМХЦЙЧБОЙА ЛПОЛТЕФОПЗП ЛМЙЕОФБ РЕТЕНЕЭЕОЩ ЧОХФТШ ЛМБУУБ
ОЙФЙ (РПФПЛБ):
//: c15:MultiJabberServer.java
// уЕТЧЕТ, ЙУРПМШЪХАЭЙК НОПЗПРПФПЮОПУФШ
// ДМС ПВУМХЦЙЧБОЙС МАВПЗП ЮЙУМБ ЛМЙЕОФПЧ.
import java.io.*;
import java.net.*;
class ServeOneJabber extends Thread {
private Socket socket;
private BufferedReader in;
private PrintWriter out;
public ServeOneJabber(Socket s)
throws IOException {
socket = s;
in =
new BufferedReader(
new InputStreamReader(
socket.getInputStream()));
// чЛМАЮЕОЙЕ БЧФПУВТПУБ ВХЖЕТПЧ:
out =
new PrintWriter(
new BufferedWriter(
new OutputStreamWriter(
socket.getOutputStream())), true);
// еУМЙ ЛБЛПК МЙВП, ХЛБЪБООЩК ЧЩЫЕ ЛМБУУ ЧЩВТПУЙФ ЙУЛМАЮЕОЙЕ
// ЧЩЪЩЧБАЭБС РТПГЕДХТБ ПФЧЕФУФЧЕООБ ЪБ ЪБЛТЩФЙЕ УПЛЕФБ
// ч РТПФЙЧОПН УМХЮБЕ ОЙФШ(РПФПЛ) ЪБЛТПЕФ ЕЗП.
start(); // чЩЪЩЧБЕФ run()
}
public void run() {
try {
while (true) {
String str = in.readLine();
if (str.equals("END")) break;
System.out.println("Echoing: " + str);
out.println(str);
}
System.out.println("closing...");
} catch(IOException e) {
System.err.println("IO Exception");
} finally {
try {
socket.close();
} catch(IOException e) {
System.err.println("Socket not closed");
}
}
}
}
public class MultiJabberServer {
static final int PORT = 8080;
public static void main(String[] args)
throws IOException {
ServerSocket s = new ServerSocket(PORT);
System.out.println("Server Started");
try {
while(true) {
// пУФБОБЧМЙЧБЕФ ЧЩРПМОЕОЙЕ, ДП ОПЧПЗП УПЕДЙОЕОЙС:
Socket socket = s.accept();
try {
new ServeOneJabber(socket);
} catch(IOException e) {
// еУМЙ ОЕХДБЮБ - ЪБЛТЩЧБЕН УПЛЕФ,
// Ч РТПФЙЧОПН УМХЮБЕ ОЙФШ ЪБЛТПЕФ ЕЗП:
socket.close();
}
}
} finally {
s.close();
}
}
} ///:~
оЙФШ ServeOneJabber ВЕТЕФ ПВЯЕЛФ Socket,
ЛПФПТЩК УПЪДБЕФУС НЕФПДПН accept( ) Ч main( )
ЛБЦДЩК ТБЪ, ЛПЗДБ ОПЧЩК ЛМЙЕОФ УПЪДБЕФ УПЕДЙОЕОЙЕ. ъБФЕН, ЛБЛ ТБОШЫЕ, ПО УПЪДБЕФ
ПВЯЕЛФ BufferedReader Й ПВЯЕЛФ PrintWriter У БЧФП-УВТПУПН ЙУРПМШЪХС
Socket. оБЛПОЕГ, ПО ЧЩЪЩЧБЕФ УРЕГЙБМШОЩК НЕФПД ПВЯЕЛФБ Thread
- start( ), ЛПФПТЩК ЧЩРПМОСЕФ ЙОЙГЙБМЙЪБГЙЙ Ч ОЙФЙ Й, ЪБФЕН ЧЩЪЩЧБЕФ
НЕФПД run( ). ъДЕУШ ЧЩРПМОСАФУС ФЕ ЦЕ ДЕКУФЧЙС, ЮФП Й Ч РТЕДЩДХЭЕН
РТЙНЕТЕ: ЮФЕОЙЕ ДБООЩИ ЙЪ УПЛЕФБ, Б ЪБФЕН ЧПЪЧТБФ ЬФЙИ ДБООЩИ ПВТБФОП, РПЛБ
ОЕ РТЙДЕФ УРЕГЙБМШОЩК УЙЗОБМ - УФТПЛБ “END”.
пФЧЕФУФЧЕООПУФШ ЪБ ПЮЙУФЛХ УПЛЕФБ ДПМЦОБ ВЩФШ УОПЧБ
ФЭБФЕМШОП ПВТБВПФБОБ. ч ЬФПН УМХЮБЕ, УПЛЕФ УПЪДБЕФУС ЪБ РТЕДЕМБНЙ ServeOneJabber
ФБЛ ЮФП ПФЧЕФУФЧЕООПУФШ НПЦЕФ ВЩФШ ТБЪДЕМЕОБ. еУМЙ ЛПОУФТХЛФПТ ServeOneJabber
ЪБЧЕТЫЙФУС ОЕХДБЮОП, ПО РТПУФП ЧЩЪПЧЕФ ЙУЛМАЮЕОЙЕ ЧЩЪЩЧБАЭЕНХ НЕФПДХ, ЛПФПТЩК
ЪБФЕН ПЮЙУФЙФ ОЙФШ. оП ЕУМЙ ЛПОУФТХЛФПТ ЪБЧЕТЫЙФУС ХУРЕЫОП, ФП ПВЯЕЛФ ServeOneJabber
ЧПЪШНЕФ ПФЧЕФУФЧЕООПУФШ ЪБ ПЮЙУФЛХ ОЙФШ ОБ УЕВС, Ч ЕЗП НЕФПДЕ run( ).
рПУНПФТЙФЕ, ОБУЛПМШЛП РТПФБС ТЕБМЙЪБГЙС Х MultiJabberServer.
лБЛ ТБОШЫЕ, ServerSocket УПЪДБЕФУС Й ЧЩЪЩЧБЕФУС НЕФПД accept( )
ДМС ПЦЙДБОЙС ОПЧПЗП УПЕДЙОЕОЙС. оП Ч ЬФПФ НПНЕОФ, ЧПЪЧТБЭБЕНПЕ ЪОБЮЕОЙЕ accept( )
(ПВЯЕЛФЩ Socket) РЕТЕДБЕФУС Ч ЛПОУФТХЛФПТ ServeOneJabber, ЛПФПТЩК
УПЪДБЕФ ОПЧХА ОЙФШ ДМС ПВТБВПМФЛЙ ЬФПЗП УПЕДЙОЕОЙС. лПЗДБ УПЕДЙОЕОЙЕ ЪБЛТЩЧБЕФУС,
ОЙФШ ЪБЧЕТЫБЕФ УЧПА ТБВПФХ.
еУМЙ УПЪДБОЙЕ ServerSocket РТЕТЩЧБЕФУС, УОПЧБ
ЧЩВТБУЩЧБЕФУС Ч main( ). оП ЕУМЙ УПЪДБОЙЕ ХУРЕЫОПЕ, ЧОЕЫОЙК ВМПЛ
try-finally ЗБТБОФЙТХЕФ ЕЗП ПЮЙУФЛХ. чОХФТЕООЙК ВМПЛ try-catch
ЪБЭЙЭБЕФ ФПМШЛП ПФ ПЫЙВПЛ Ч ЛПОУФТХЛФПТЕ ServeOneJabber; ЕУМЙ ЛПОУФТХЛФПТ
ЧЩРПМОСЕФУС ВЕЪ ПЫЙВПЛ, ФП ОЙФШ ServeOneJabber ЪБЛТПЕФ УЧСЪБООЩК У
ОЕК УПЛЕФ.
дМС РТПЧЕТЛЙ ФПЗП, ЮФП УЕТЧЕТ РПДДЕТЦЙЧБЕФ ОЕУЛПМШЛП
ЛМЙЕОФПЧ, УМЕДХАЭБС РТПЗТБННБ УПЪДБЕФ НОПЦЕУФЧП ЛМЙЕОФПЧ (ЙУРПМШЪХС ОЙФЙ)
ЛПФПТЩЕ РПДЛМАЮБАФУС Л ПДОПНХ Й ФПНХ ЦЕ УЕТЧЕТХ. нБЛУЙНБМШОПЕ ЮЙУМП ОЙФЕК
ПРТЕДЕМСЕФУС РЕТЕНЕООПК final int MAX_THREADS.
//: c15:MultiJabberClient.java
// лМЙЕОФ ДМС РТПЧЕТЛЙ MultiJabberServer
// РПУТЕДУФЧПН ЪБРХУЛБ НОПЦЕУФЧБ ЛМЙЕОФПЧ.
import java.net.*;
import java.io.*;
class JabberClientThread extends Thread {
private Socket socket;
private BufferedReader in;
private PrintWriter out;
private static int counter = 0;
private int id = counter++;
private static int threadcount = 0;
public static int threadCount() {
return threadcount;
}
public JabberClientThread(InetAddress addr) {
System.out.println("Making client " + id);
threadcount++;
try {
socket =
new Socket(addr, MultiJabberServer.PORT);
} catch(IOException e) {
System.err.println("Socket failed");
// еУМЙ УПЛЕФ ОЕ УПЪДБМУС,
// ОЙЮЕЗП ОЕ ОБДП ЮЙУФЙФШ.
}
try {
in =
new BufferedReader(
new InputStreamReader(
socket.getInputStream()));
// чЛМАЮЕОЙЕ БЧФП-ПЮЙУФЛЙ ВХЖЕТБ:
out =
new PrintWriter(
new BufferedWriter(
new OutputStreamWriter(
socket.getOutputStream())), true);
start();
} catch(IOException e) {
// уПЛЕФ ДПМЦЕО ВЩФШ ЪБЛТЩФ РТЙ РПСЧМЕОЙЙ МАВПК ПЫЙВЛЙ
try {
socket.close();
} catch(IOException e2) {
System.err.println("Socket not closed");
}
}
// йОБЮЕ УПЛЕФ ВХДЕФ ЪБЛТЩФ
// НЕФПДПН run() Х ОЙФЙ.
}
public void run() {
try {
for(int i = 0; i < 25; i++) {
out.println("Client " + id + ": " + i);
String str = in.readLine();
System.out.println(str);
}
out.println("END");
} catch(IOException e) {
System.err.println("IO Exception");
} finally {
// чУЕЗДБ ЪБЛТЩЧБЕФ ЕЗП:
try {
socket.close();
} catch(IOException e) {
System.err.println("Socket not closed");
}
threadcount--; // ъБЧЕТЫЕОЙЕ ОЙФЙ
}
}
}
public class MultiJabberClient {
static final int MAX_THREADS = 40;
public static void main(String[] args)
throws IOException, InterruptedException {
InetAddress addr =
InetAddress.getByName(null);
while(true) {
if(JabberClientThread.threadCount()
< MAX_THREADS)
new JabberClientThread(addr);
Thread.currentThread().sleep(100);
}
}
} ///:~
лПОУФТХЛФПТ JabberClientThread ВЕТЕФ InetAddress
Й ЙУРПМШЪХЕФ ЕЗП ДМС ПФЛТЩФЙС Socket. чЩ ЧПЪРПЦОП ХЦЕ ОБЮЙОБЕФЕ ЧЙДЕЫШ
ЫБВМПО: Socket ЙУРПМШЪХЕФУС ЧУЕЗДБ ДМС УПЪДБОЙС ОЕЛПФПТЩИ ФЙРПЧ Reader
Й/ЙМЙ Writer (ЙМЙ InputStream Й/ЙМЙ OutputStream)
ПВЯЕЛФ, ЮФП СЧМСЕФУС ЕДЙОУФЧЕООЩН УРПУПВПН, Ч ЛПФПТПН Socket НПЦЕФ
ВЩФШ ЙУРПМШЪПЧБО. (чЩ НПЦЕФЕ, ЛПОЕЮОП, ОБРЙУБФШ ПДЙО-ДЧБ ЛМБУУБ ДМС БЧФПНБФЙЪБГЙЙ
ЬФПЗП РТПГЕУУБ, ЧНЕУФП ФПЗП , ЮФПВЩ ЪБОПЧП ЧУЕ ЬФП ОБВЙТБФШ, ЕУМЙ ДМС чБУ
ЬФП УМПЦОП.) йФБЛ, start( ) ЧЩРПМОСЕФ ЙОЙГЙБМЙЪБГЙЙ ОЙФЙ Й ЧЩЪЩЧБЕФ
НЕФПД run( ). ъДЕУШ, УППВЭЕОЙС ПФУЩМБАФУС УЕТЧЕТХ Й ЙОЖПТНБГЙС
У УЕТЧЕТБ РЕЮБФБЕФУС ОБ ЬЛТБОЕ. пДОБЛП, ОЙФШ ЙНЕЕФ ПЗТБОЙЮЕООПЕ ЧТЕНС ЦЙЪОЙ
Й Ч ПДЙО РТЕЛТБУОЩК НПНЕОФ ЪБЧЕТЫБЕФУС. пВТБФЙФЕ ЧОЙНБОЙЕ, ЮФП УПЛЕФ ПЮЙЭБЕФУС
ЕУМЙ ЛПОУФТХЛФПТ ЪБЧЕТЫБЕФУС ОЕХУРЕЫОП, РПУМЕ ФПЗП ЛБЛ УПЛЕФ УПЪДБЕФУС, ОП
РЕТЕД ФЕН, ЛБЛ ЛПОУФТХЛФПТ ЪБЧЕТЫЙФУС. ч РТПФЙЧОПН УМХЮБЕ ПФЧЕФУФЧЕООПУФШ
ЪБ ЧЩЪПЧ НЕФПДБ close( ) ДМС УПЛЕФБ МПЦЙФУС ОБ НЕФПД run( ).
рЕТЕНЕООБС threadcount ИТБОЙФ ЮЙУМП - УЛПМШЛП
ПВЯЕЛФПЧ JabberClientThread Ч ДБООЩК НПНЕОФ УХЭЕУФЧХЕФ. пОБ ХЧЕМЙЮЙЧБЕФУС
Ч ЛПОУФТХЛФПТЕ Й ХНЕОШЫБЕФУС РТЙ ЧЩИПДЕ ЙЪ НЕФПДБ run( ) (Й ЬФП
ЪОБЮЙФ, ЮФП ОЙФШ ЪБЧЕТЫБЕФУС). ч НЕФПДЕ MultiJabberClient.main( ),
чЩ ЧЙДЙФЕ, ЮФП ЮЙУМП ОЙФЕК РТПЧЕТСЕФУС, Й ЕУМЙ ОЙФЕК УМЙЫЛПН НОПЗП - ОПЧЩЕ
ОЕ УПЪДБАФУС. ъБФЕН НЕФПД ЪБУЩРБЕФ. рТЙ ЬФПН, ОЕЛПФПТЩЕ ОЙФЙ ВХДХФ ЪБЧЕТЫБФШУС
Й ОПЧЩЕ УНПЗХФ ВЩФШ УПЪДБОЩ. чЩ НПЦЕФЕ РПЬЛУРЕТЙНЕОФЙТПЧБФШ У MAX_THREADS,
ЮФПВЩ РПУНПФТЕФШ ЛПЗДБ Х чБЫЕК УЙУФЕНЩ РПСЧСФУС РТПВМЕНЩ У ПВУМХЦЙЧБОЙЕН ВПМШЫПЗП
ЛПМЙЮЕУФЧБ УПЕДЙОЕОЙК.
рТЙНЕТЩ, ЛПФПТЩЕ чЩ ХЧЙДЕМЙ ЙУРПМШЪХАФ РТПФПЛПМTransmission
Control Protocol (TCP, ФБЛЦЕ ЙЪЧЕУФОЩК ЛБЛУПЛЕФЩ
ПУОПЧБООЩЕ ОБ РПФПЛБИ), ЛПФПТЩК УПЪДБО ДМС ЙУЛМАЮЙФЕМШОПК ОБДЕЦОПУФЙ Й
ЗБТБОФЙТХЕФ, ЮФП ДБООЩЕ ВХДХФ ДПУФБЧМЕОЩ ФХДБ, ЛХДБ ОЕПВИПДЙНП. пО РПЪЧПМСЕФ
ПТЗБОЙЪПЧБФШ РПЧФПТОХА РЕТЕДБЮХ РПФЕТСООЩИ ДБООЩИ, ПО РТЕДПУФБЧМСЕФ ЧПЪНПЦОПУФШ
ПФУЩМЛЙ ПФДЕМШОЩИ ЮБУФЕК ЮЕТЕЪ ТБЪОЩЕ НБТЫТХФЙЪБФПТЩ, Ч УМХЮБЕФ ЕУМЙ ПДЙО
ЙЪ ОЙИ ЧЩКДЕФ ЙЪ УФТПС, Й ВБКФЩ ВХДХФ РТЙОСФЩ ЙНЕООП Ч ФПН РПТСДЛЕ, Ч ЛФПТПН
ПОЙ ВЩМЙ РПУМБОЩ. чЕУШ ЬФПФ ЛПОФТПМШ Й ОБДЕЦОПУФШ ЙНЕЕФ ГЕОХ: Ч TCP ЧЩУПЛЙЕ
ОБЛМБДОЩЕ ТБУИПДЩ.
уХЭЕУФЧХЕФ ЧФПТПК РТПФПЛПМ, ОБЪЩЧБЕНЩК User
Datagram Protocol (UDP), ЛПФПТЩК ОЕ ЗБТБОФЙТХЕФ, ЮФП РБЛЕФЩ ВХДХФ ДПУФБЧМЕОЩ
Й ОЕ ЗБТБОФЙТХЕФ ДПУФБЧЛЙ Ч ФПН РПТСДЛЕ, Ч ЛПФПТПН ПОЙ ВЩМЙ РПУМБОЩ. пО ОБЪЩЧБЕФУС
“ОЕОБДЕЦОЩН РТПФПЛПМПН”
(TCP ЬФП “ОБДЕЦОЩК РТПФПЛПМ”),
Й ЬФП ЪЧХЮЙФ ОЕ ПЮЕОШ ИПТПЫП, ПДОБЛП ПО ОБНОПЗП ВЩУФТЕЕ Й РПФПНХ НПЦЕФ ВЩФШ
РПМЕЪОЩН. уХЭЕУФЧХАФ ОЕЛПФПТЩЕ РТЙМПЦЕОЙС, ФБЛЙЕ ЛБЛ БХДЙП УЙЗОБМЩ, Ч ЛПФПТЩИ
РПФЕТС ОЕУЛПМШЛЙИ РБЛЕФПЧ ОЕ ПЮЕОШ ОЕ ЙНЕЕФ ВПМШЫПЗП ЪОБЮЕОЙС, ОП УЛПТПУФШ
ПЮЕОШ ЧБЦОБ. мЙВП РТЕДУФБЧШФЕ УЕТЧЕТ РТЕДПУФБЧМСАЭЙК ЙОЖПТНБГЙА П ЧТЕНЕОЙ,
ЗДЕ ДЕКУФЧЙФЕМШОП ОЕ ЙНЕЕФ ЪОБЮЕОЙ, ЕУМЙ ПДОП ЙЪ УППВЭЕОЙК РПФЕТСЕФУС. фБЛЦЕ,
ОЕЛПФПТЩЕ РТЙМПЦЕОЙС НПЗХФ РПУЩМБФШ UDP УППВЭЕОЙС ОБ УЕТЧЕТ, Б ЪБФЕН, РТЙ
ПФУХФУФЧЙЙ ПФЛМЙЛБ Ч ФЕЮЕОЙЕ ОЕЛПФПТПЗП ЧТЕНЕОЙ, УЮЙФБФШ, ЮФП УППВЭЕОЙЕ ВЩМП
РПФЕТСОП.
оБ УБНПН ДЕМЕ, чЩ ВХДЕФЕ ДЕМБФШ ВПМШЫЙОУФЧП УЕФЕЧЩИ
РТЙМПЦЕОЙК У РТПФПЛПМПН TCP, Й ФПМШЛП ОЕЛПФПТЩЕ ВХДХФ ЙУРПМШПЧБФШ UDP. уХЭЕУФЧХЕФ
ВПМЕЕ РПМОПЕ ПРЙУБОЙЕ UDP, ЧЛМАЮБАЭЕЕ РТЙНЕТЩ, Ч РЕТЧПК ТЕДБЛГЙЙ ЛОЙЗЙ (ДПУФХРОЩИ
ОБ CD ROM ЧНЕУФЕ У ЛОЙЗПК, МЙВП УЧПВПДОП ЪБЗТХЦБЕНЩ У УБКФБ www.BruceEckel.com).
бРРМЕФЩ НПЗХФ ПФПВТБЪЙФШ МАВХА УУЩМЛХ URL ЮЕТЕЪ Web
ВТБХЪЕТ, ЧОХФТЙ ЛПФПТПЗП ЪБРХУЛБЕФУС БРРМЕФ. чЩ НПЦЕФЕ ЧЩРПМОЙФШ ЬФП У РПНПЭША
УМЕДХАЭЕК УФТПЛЙ:
getAppletContext().showDocument(u);
Ч ЛПФПТПК
u - ЬФП ПВЯЕЛФ URL. чПФ РТПУФПК РТЙНЕТ, ЛПФПТЩК РЕТЕОБРТБЧМСЕФ
чБУ ОБ ДТХЗХА Web УФТБОЙЮЛХ. иПФС, чЩ РЕТЕОБРТБЧМСЕФЕУШ ОБ HTML УФТБОЙЮЛХ,
чЩ ФБЛЦЕ НПЦЕФЕ РЕТЕОБРТБЧЙФШ ОБ РТПЗТБННХ CGI.
//: c15:ShowHTML.java
// <applet code=ShowHTML width=100 height=50>
// </applet>
import javax.swing.*;
import java.awt.*;
import java.awt.event.*;
import java.net.*;
import java.io.*;
import com.bruceeckel.swing.*;
public class ShowHTML extends JApplet {
JButton send = new JButton("Go");
JLabel l = new JLabel();
public void init() {
Container cp = getContentPane();
cp.setLayout(new FlowLayout());
send.addActionListener(new Al());
cp.add(send);
cp.add(l);
}
class Al implements ActionListener {
public void actionPerformed(ActionEvent ae) {
try {
// ьФП НПЦЕФ ВЩФШ РТПЗТБННБ CGI ЧНЕУФП
// HTML УФТБОЙЮЛЙ.
URL u = new URL(getDocumentBase(),
"FetcherFrame.html");
// пФПВТБЦБЕФУС ЧЩЧПД URL ЙУРПМШЪХС
// Web ВТБХЪЕТ, ЛБЛ ПВЩЮОХА УФТБОЙЮЛХ:
getAppletContext().showDocument(u);
} catch(Exception e) {
l.setText(e.toString());
}
}
}
public static void main(String[] args) {
Console.run(new ShowHTML(), 100, 50);
}
} ///:~
лТБУПФБ ЛМБУУБ URL
Ч ФПН, ОБУЛПМШЛП УЙМШОП чБУ ПО ЪБЭЙЭБЕФ ПФ ФПОЛПУФЕК ТЕБМЙЪБГЙЙ УФПТПОЩ УЕТЧЕТБ.
чЩ НПЦЕФЕ РТЙУПЕДЙОЙФШУС Л Web УЕТЧЕТХ РТБЛФЙЮЕУЛЙ ОЙЮЕЗП ОЕ ЪОБС, ЮФП РТПЙУИПДЙФ
Х ОЕЗП ЧОХФТЙ.
чБТЙБГЙС РТЙЧЕДЕООПК ЧЩЫЕ РТПЗТБННЩ ЮЙФБЕФ ЖБКМ, ТБУРПМПЦЕООЩК
ОБ УЕТЧЕТЕ. ч ЬФПН УМХЮБЕ, ЖБКМ ПРТЕДЕМСЕФУС ЛМЙЕОФПН:
//: c15:Fetcher.java
// <applet code=Fetcher width=500 height=300>
// </applet>
import javax.swing.*;
import java.awt.*;
import java.awt.event.*;
import java.net.*;
import java.io.*;
import com.bruceeckel.swing.*;
public class Fetcher extends JApplet {
JButton fetchIt= new JButton("Fetch the Data");
JTextField f =
new JTextField("Fetcher.java", 20);
JTextArea t = new JTextArea(10,40);
public void init() {
Container cp = getContentPane();
cp.setLayout(new FlowLayout());
fetchIt.addActionListener(new FetchL());
cp.add(new JScrollPane(t));
cp.add(f); cp.add(fetchIt);
}
public class FetchL implements ActionListener {
public void actionPerformed(ActionEvent e) {
try {
URL url = new URL(getDocumentBase(),
f.getText());
t.setText(url + "\n");
InputStream is = url.openStream();
BufferedReader in = new BufferedReader(
new InputStreamReader(is));
String line;
while ((line = in.readLine()) != null)
t.append(line + "\n");
} catch(Exception ex) {
t.append(ex.toString());
}
}
}
public static void main(String[] args) {
Console.run(new Fetcher(), 500, 300);
}
} ///:~
уПЪДБОЙЕ ПВЯЕЛФБ URL УИПДОП У РЕТДЩДХЭЙН РТЙНЕТПН
—getDocumentBase( ) - УФБТФПЧБС РПЪЙГЙС ЛБЛ Й ТБОШЫЕ, ОП
Ч ЬФП Ф ТБЪ ЙНС ЖБКМБ ЮЙФБЕФУС ЙЪ РПМС JTextField. лБЛ ФПМШЛП ПВЯЕЛФ
URL УПЪДБО, ЕЗП УФТПЛПЧБС ЧЕТУЙС ПФПВТБЦБЕФУС Ч JTextArea ФБЛ
ЮФП НЩ ЧЙДЙН, ЛБЛ ПОБ ЧЩЗМСДЙФ. ъБФЕН УПЪДБЕФУС InputStream ЙЪ URL,
ЛПФПТЩК Ч ЬФПН УМХЮБЕ МЕЗЛП УПЪДБЕФ РПФПЛ УЙНЧПМПЧ Ч ЖБКМЕ. рПУМЕ ЛПОЧЕТФЙТПЧБОЙС
Ч Reader Й ВХЖЕТЙЪБГЙЙ, ЮЙФБЕФУС ЛБЦДБС УФТПЛБ Й ДПВБЧМСЕФУС Ч JTextArea.
пВТБФЙФЕ ЧОЙНБОЙЕ, ЮФП JTextArea ВЩМП РПНЕЭЕОП ЧОХФТШ JScrollPane
ФБЛ ЮФП РТПЛТХФЛБ РТПЙУИПДЙФ БЧФПНБФЙЮЕУЛЙ.
оБ УБНПН ДЕМЕ УХЭЕУФЧХЕФ ЕЭЕ НОПЦЕУФЧП ЧЕЭЕК, ЛПФПТЩЕ
НПЗМЙ ВЩ БИПДЙФШУС Ч ЬФПН ТБЪДЕМЕ. уЕФЕЧБС РПДДЕТЦЛБ Ч Java ФБЛЦЕ ЫЙТПЛХА
РПДДЕТЦЛХ URLs, ЧЛМАЮБС ХРТБЧМЕОЙЕ РТПФПЛПМБНЙ ДМС ТБЪМЙЮОЩИ ФЙРПЧ УПДЕТЦБОЙС.
чУЕ ЬФП НПЦЕФ ВЩФШ ОБКДЕОП ОБ ЙОФЕТОЕФ УБКФЕ. чЩ НПЦЕФЕ ОБКФЙ РПМОПЕ Й РПДТПВОПЕ
ПРЙУБОЙЕ УЕФЕЧПЗП РТПЗТБННЙТПЧБОЙС ОБ Java Ч ЛОЙЗЕ Java Network Programming
by Elliotte Rusty Harold (O’Reilly, 1997).
рТЙВМЙЪЙФЕМШОП ВЩМП РПДУЮЙФБОП, ЮФП РПМПЧЙОБ ЧУЕЗП РТПЗТБННОПЗП ПВЕУРЕЮЕОЙС ЙУРПМШЪХЕФ ЛМЙЕОФ/УЕТЧЕТОЩЕ ПРЕТБГЙЙ. нОПЗППВЕЭБАЭЕК ЧПЪНПЦОПУФША Java ВЩМБ УРПУПВОПУФШ УФТПЙФШ РМБФЖПТНПОЕЪБЧЙУЙНЩЕ ЛМЙЕОФ/УЕТЧЕТОЩЕ РТЙМБЦЕОЙС ДМС ТБВПФЩ У ВБЪБНЙ ДБООЩИ. ьФП УФБМП ЧПЪНПЦОЩН ВМБЗПДБТС Java DataBase Connectivity (JDBC).
пДОБ ЙЪ ПУОПЧОЩИ РТПВМЕНН РТЙ ТБВПФЕ У ВБЪБНЙ ДБООЩИ - ЬФП ЧПКОБ ПУПВЕООПУФЕК НЕЦДХ ЛПНРБОЙСНЙ, ТБЪТБВБФЩЧБАЭЙНЙ ВБЪЩ ДБООЩИ. еУФШ “УФБОДБТФОЩК” СЪЩЛ ВБЪЩ ДБООЩИ, Structured Query Language (SQL-92), ОП ЧЩ ПВЩЮОП ДПМЦОЩ ЪОБФШ У ВБЪПК ДБООЩИ ЛБЛПЗП РТПЙЪЧПДЙФЕМС ЧЩ ТБВПФБЕФЕ, ОЕУНПФТС ОБ УФБОДБТФ. JDBC РТЕДОБЪОБЮЕОБ ДМС ОЕЪБЧЙУЙНПУФЙ ПФ РМБФЖПТНЩ, ФБЛ ЮФП ЧБН ОЕФ ОЕПВИПДЙНПУФЙ ЪБВПФЙФУС П ФПН, ЛБЛХА ВБЪХ ДБООЩИ ЧЩ ЙУРПМШЪХЕФЕ РТЙ РТПЗТБННЙТПЧБОЙЙ. пДОБЛП ЧУЕ ЕЭЕ ЧПЪНПЦОП ДЕМБФШ ЪБЧЙУЙНЩЕ ПФ РТПЙЪЧПДЙФЕМС ЧЩЪПЧЩ ЙЪ JDBC, ФБЛ ЮФП ЧЩ ОЕ ПЗТБОЙЮЕОЩ ФЕН, ЮФП ЧЩ ДПМЦОЩ ДЕМБФШ.
ч ПДОПН НЕУФЕ РТПЗТБННЙУФБН НПЦЕФ РПОБДПВЙФШУС ЙУРПМШЪПЧБФШ SQL ЙНЕОБ ФЙРПЧ Ч SQL ЧЩТБЦЕОЙЙ TABLE CREATE, ЛПЗДБ ПОЙ УПЪДБАФ ОПЧХА ФБВМЙГХ ДБООЩИ Й ПРТЕДЕМСАФ SQL ФЙР ДМС ЛБЦДПК ЛПМПОЛЙ. л УПЦБМЕОЙА УХЭЕУФЧХАФ ЪОБЮЙФЕМШОЩЕ ТБЪМЙЮЙС НЕЦДХ SQL ФЙРБНЙ, РПДДЕТЦЙЧБЕНЩНЙ ТБЪМЙЮОЩНЙ РТПДХЛФБНЙ ВБЪ ДБООЩИ. тБЪМЙЮОЩЕ ВБЪЩ ДБООЩИ, РПДДЕТЦЙЧБАЭЙЕ SQL ФЙРЩ У ПДЙОБЛПЧПК УЕНБОФЙЛПК Й УФТХЛФХТПК, НПЗХФ ЙНЕФШ ТБЪМЙЮОЩЕ ЙНЕОБ ФЙРПЧ. вПМШЫЙОУФЧП ОБЙВПМЕЕ ЙЪЧЕУФОЩИ ВБЪ ДБООЩИ РПДДЕТЦЙЧБАФ ФЙРЩ ДБООЩИ SQL ДМС ВПМШЫЙИ ВЙОБТОЩИ ЪОБЮЕОЙК: Ч Oracle ЬФПФ ФЙР ОБЪЩЧБЕФУС LONG RAW, Sybase ОБЪЩЧБЕФ ЕЗП IMAGE, Informix ОБЪЩЧБЕФ ЕЗП BYTE, Б DB2 ОБЪЩЧБЕФ ЗП LONG VARCHAR FOR BIT DATA. рПЬФПНХ, ЕУМЙ РЕТЕОПУЙНПУФШ НЕЦДХ ВБЪБНЙ ДБООЩИ СЧМСЕФУС ЧБЫЕК ГЕМША, ЧЩ ДПМЦОЩ РПРТПВПЧБФШ ПВПКФЙУШ ФПМШЛП ПУОПЧОЩНЙ ЙДЕОФЙЖЙЛБФПТБНЙ SQL ФЙРПЧ.
рЕТЕОПУЙНПУФШ - ЬФП ФБЛБС ЧПЪНПЦОПУФШ РТЙ ОБРЙУБОЙЙ ЛОЙЗЙ, РТЙ ЛПФПТПК ЮЙФБФЕМЙ НПЗХФ РТПЧЕТЙФШ РТЙНЕТЩ Ч МАВПН ОЕЙЪЧЕУФОПН ИТБОЙМЙЭЕ ДБООЩИ. с РПРТПВПЧБМ ОБРЙУБФШ ФБЛЙЕ РТЙНЕТЩ ОБУФПМШЛП РЕТЕОПУЙНЩНЙ, ОБУЛПМШЛП ЬФП ЧПЪНПЦОП. фБЛЦЕ ЧЩ ДПМЦОЩ ЙНЕФШ Ч ЧЙДХ, ЮФП УРЕГЙЖЙЮОЩК ДМС ВБЪЩ ДБООЩИ ЛПД ВЩМ ЙЪПМЙТПЧБО, ЮФПВЩ НПЦОП ВЩМП ГЕОФТБМЙЪПЧБФШ ЧУЕ ЙЪНЕОЕОЙС, ЛПФПТЩЕ ЧБН ОЕПВИПДЙНП ВХДЕФ ЧЩРПМОЙФШ, ЮФПВЩ РТЙНЕТЩ ЪБТБВПФБМЙ Ч ЧБЫЕК УТЕДЕ.
JDBC, ЛБЛ Й НОПЗЙЕ API Ч Java, РТЕДОБЪОБЮЕО ДМС ХРТПЭЕОЙС. чЩЪПЧЩ НЕФПДПЧ, ЛПФПТЩЕ ЧЩ ДЕМБЕФЕ, УППФЧЕФУФЧХЕФ МПЗЙЮЕУЛЙН ПРЕТБГЙСН, ЛПФПТЩЕ ЧЩ ДХНБЕФЕ ЧЩРПМОЙФШ ДМС УВПТБ ДБООЩИ ЙЪ ВБЪЩ ДБООЩИ: РПДЛМАЮЙФШУС Л ВБЪЕ ДБООЩИ, УПЪДБФШ ЧЩТБЦЕОЙЕ Й ЧЩРПМОЙФШ ЪБРТПУ, ЪБФЕН РПУНПФТЕФШ ТЕЪХМШФЙТХАЭХА ЧЩВПТЛХ.
дМС РПМХЮЕОЙС РМБФЖПТНПОЕЪБЧЙУЙНПУФЙ, JDBC РТЕДПУФБЧМСЕФ НЕОЕДЦЕТ ДТБКЧЕТПЧ (driver manager) ЛПФПТЩК ДЙОБНЙЮЕУЛЙ ЙУРПМШЪХЕФ ЧУЕ ПВЯЕЛФЩ ДТБКЧЕТПЧ, ЛПФПТЩЕ ОЕПВИПДЙНЩ ДМС ПРТПУБ ЧБЫЕК ВБЪЩ ДБООЩИ. фБЛ ЮФП ЕУМЙ Х ЧБУ ЕУФШ ВБЪЩ ДБООЩИ ПФ ФТЕИ РТПЙЪЧПДЙФЕМЕК, Л ЛПФПТЩН ЧЩ ИПФЙФЕ РПДУПЕДЙОЙФШУС, ЧБН ОХЦОП ФТЙ ТБЪМЙЮОЩИ ПВЯЕЛФБ ДТБКЧЕТПЧ. пВЯЕЛФЩ ДТБКЧЕТПЧ ТЕЗЙУФТЙТХАФ УЕВС У РПНПЭША НЕОЕДЦЕТБ ДТБКЧЕТПЧ ЧМ ЧТЕНС ЪБЗТХЪЛЙ, Б ЧЩ НПЦЕФЕ РТЙОХДЙФЕМШОП ЧЩРПМОЙФШ ЪБЗТХЪЛХ, ЙУРПМШЪХС Class.forName( ).
дМС ПФЛТЩФЙС ВБЪЩ ДБООЩИ ЧЩ ДПМЦОЩ УПЪДБФШ “URL ВБЪЩ ДБООЩИ”, ЛПФТЩК ХЛБЪЩЧБЕФ:
чУС ЬФБ ЙОЖПТНБГЙС ЛПНВЙОЙТХЕФУС Ч ПДОХ УФТПЛХ: “URL ВБЪЩ ДБОЩИ”. оБРТЙНЕТ, ДМС РПДЛМАЮЕОЙС ЮЕТЕД РПДМЕЦБЭЙК РТПФПЛПМ ODBC Л ВБЪЕ ДБООЩИ У ЙДЕОФЙЖЙЛБФПТПН “people”, URL ВБЪЩ ДБООЩИ НПЦЕФ ВЩФШ:
String dbUrl = "jdbc:odbc:people";
еУМЙ ЧЩ РПДЛМАЮБЕФЕУШ РП УЕФЙ, URL ВБЪЩ ДБООЩИ ВХДЕФ УПДЕТЦБФШ ЙОЖПТНБГЙА ДМС РПДЛМАЮЕОЙС, ЙДЕОФЙЖЙГЙТХАЭХА ХДБМЕООХА НБЫЙОХ Й НПЦЕФ ВЩФШ ОЕНОПЗП РХЗБАЭЙН. чПФ РТЙНЕТ ТБВПФЩ У ВБЪПК ДБООЩИ CloudScape, ЛПФПТХА ЧЩЪЩЧБЕФ ХДБМЕООЩИ ЛМЙЕОФ, ЙУРПМШЪХАЭЙК RMI:
jdbc:rmi://192.168.170.27:1099/jdbc:cloudscape:db
ьФПФ URL ВБЪЩ ДБООЩИ ОБ УБНПН ДЕМЕ УПДЕТЦЙФ ДЧБ jdbc ЧЩЪПЧБ Ч ПДОПН. рЕТЧБС ЮБУФШ “jdbc:rmi://192.168.170.27:1099/” ЙУРПМШЪХЕФ RMI ДМС УПЪДБОЙС УПЕДЙОЕОЙС У ХДБМЕООПК НБЫЙОПК ВБЪ ДБООЩИ, УМЕДСЭЕК ЪБ РПТФПН 1099 РП IP БДТЕУХ 192.168.170.27. чФПТБС ЮБУФШ URL, “jdbc:cloudscape:db” РЕТЕДБЕФ ВПМЕЕ РТЙЧЩЮОЩЕ ХУФБОПЧЛЙ, ЙУРПМШЪХС РПДМЕЦБЭЙК РТПФПЛПМ Й ЙНС ВБЪЩ ДБООЩИ, ОП ЬФП РТПЙЪПКДЕФ ФПМШЛП РПУМЕ ФПЗП, ЛБЛ РЕТЧБС УЕЛГЙС ХУФБОПЧЙФ УПЕДЙОЕОЙЕ У ХДБМЕООПК НБЫЙОПК ЮЕТЕЪ RMI.
лПЗДБ ЧЩ ЗПФПЧЩ РТЙУПЕДЙОЙФШУС Л ВБЪЕ ДБООЩИ, ЧЩЪПЧЙФЕ УФБФЙЮЕУЛЙК (static) НЕФПД DriverManager.getConnection( ) Й РЕТЕДБКФЕ ЕНХ URL ВБЪЩ ДБООЩИ Й РБТПМШ ДМС ЧИПДБ Ч ВБЪХ ДБООЩИ. пВТБФОП ЧЩ РПМХЮЙФЕ ПВЯЕЛФ Connection, ЛПФПТЩК ЪБФЕН ЧЩ НПЦЕФЕ ЙУРПМШЪПЧБФШ ДМС ПРТПУБ Й НБОЙРХМСГЙК У ВБЪПК ДБООЩИ.
уМЕДХАЭЙК РТЙНЕТ ПФЛТЩЧБЕФ ЛПОФБЛФОХА ЙОЖПТНБГЙА ВБЪЩ ДБООЩИ Й ЙЭЕФ ЙНС ЮЕМПЧЕЛБ, РЕТЕДБООПЕ ЙЪ ЛПНБОДОПК УФТПЛЙ. пО ЧЩВЙТБЕФ ФПМШЛП ЙНЕОБ МАДЕК, ЙНЕАЭЙК ЬМЕЛФТПООЩЕ БДТЕУБ, ЪБФЕН РЕЮБФБЕФ ФЕ ЙЪ ОЙИ, ЙНС ЛПФПТЩИ УПЧРБДБЕФ У ЪБДБООЩН:
//: c15:jdbc:Lookup.java
// рПЙУЛ ЬМЕЛФТПООЩИ БДТЕУПЧ Ч
// МПЛБМШОПК ВБЪЕ ДБООЩИ У РПНПЭША JDBC.
import java.sql.*;
public class Lookup {
public static void main(String[] args)
throws SQLException, ClassNotFoundException {
String dbUrl = "jdbc:odbc:people";
String user = "";
String password = "";
// ъБЗТХЦБЕН ДТБКЧЕТ (ТЕЗЙУФТЙТХЕН УЕВС)
Class.forName(
"sun.jdbc.odbc.JdbcOdbcDriver");
Connection c = DriverManager.getConnection(
dbUrl, user, password);
Statement s = c.createStatement();
// SQL ЛПД:
ResultSet r =
s.executeQuery(
"SELECT FIRST, LAST, EMAIL " +
"FROM people.csv people " +
"WHERE " +
"(LAST='" + args[0] + "') " +
" AND (EMAIL Is Not Null) " +
"ORDER BY FIRST");
while(r.next()) {
// тЕЗЙУФТ ОЕ ЙНЕЕФ ЪОБЮЕОЙС:
System.out.println(
r.getString("Last") + ", "
+ r.getString("fIRST")
+ ": " + r.getString("EMAIL") );
}
s.close(); // ъБЛТЩЧБЕН ResultSet
}
} ///:~
чЩ НПЦЕФЕ ХЧЙДЕФШ УПЪДБОЙЕ URL ВБЪЩ ДБООЩИ, ЛБЛ ЬФП ПРЙУБОП ЧЩЫЕ. ч ЬФПН РТЙНЕТЕ ОЕФ ЪБЭЙФОПЗП РБТПМС ДМС ВБЪЩ ДБООЩИ, РПЬФПНХ ЙНС РПМШЪПЧБФЕМС Й РБТПМШ РТЕДУФБЧМЕОЩ РХУФЩНЙ УФТПЛБНЙ.
лБЛ ФПМШЛП УПЕДЙОЕОЙЕ ХУФБОПЧМЕОП У РПНПЭША DriverManager.getConnection( ), ЧЩ НПЦЕФЕ ЙУРПМШЪПЧБФШ РПМХЮЕООЩК ПВЯЕЛФ Connection ДМС УПЪДБОЙС ПВЯЕЛФБ Statement, ЙУРПМШЪХС НЕФПД createStatement( ). у РПНПЭША Statement ЧЩ НПЦЕФЕ ЧЩЪЧБФШ executeQuery( ), РЕТЕДБЧ Ч ОЕЗП УФТПЛХ, УПДЕТЦБЭХА SQL ЧЩТБЦЕОЙЕ УФБОДБТФБ SQL-92. (уЛПТП ЧЩ ХЧЙДЙФЕ ЛБЛ ЧЩ НПЦЕФЕ ЗЕОЕТЙТПЧБФШ ЬФП ЧЩТБЦЕОЙЕ БЧФПНБФЙЮЕУЛЙ, ФБЛ ЮФП ЧБН ОЕ ОХЦОП НОПЗП ЪОБФШ ПВ SQL.)
нЕФПД executeQuery( ) ЧПЪЧТБЭБЕФ ПВЯЕЛФ ResultSet, ЛПФПТЩК СЧМСЕФУС ЙФЕТБФПТПН: НЕФПД next( ) РЕТЕНЕЭБЕФ ЙФЕТБФПТ ОБ УМЕДХАЭХА ЪБРЙУШ Ч ЧЩТБЦЕОЙЙ ЙМЙ ЧПЪЧТБЭБЕФ false, ЕУМЙ ДПУФЙЗОХФ ЛПОЕГ ТЕЪХМШФЙТХАЭЕЗП НОПЦЕУФЧБ. чЩ ЧУЕЗДБ РПМХЮЙФЕ ОБЪБД ПВЯЕЛФ ResultSet ПФ executeQuery( ), ДБЦЕ ЕУМЙ ТЕЪХМШФБФПН ЪБРТПУБ СЧМСЕФУС РХУФПЕ НОПЦЕУФЧП (ЕУМЙ ФБЛ, ЙУЛМАЮЕОЙЕ ОЕ ЧПЪОЙЛБЕФ). пВТБФЙФЕ ЧОЙНБОЙЕ, ЮФПЧЩ ДПМЦОЩ ЧЩЪЧБФШ next( ) РТЕЦДЕ, ЮЕН РПРТПВПЧБФШ РТПЮЕУФШ МАВХА ЪБРЙУШ. еУМЙ ТЕЪХМШФЙТХАЭЕЕ НОПЦЕУФЧП - РХУФПЕ, ЬФПФ РЕТЧЩК ЧЩЪПЧ next( ) ЧЕТОЕФ false. дМС ЛБЦДПК ЪБРЙУЙ ТЕЪХМШФЙТХАЭЕЗП НОПЦЕУФЧБ ЧЩ НПЦЕФЕ ЧЩВТБФШ РПМС, ЙУРПМШЪХС (ОБТСДХ У ДТХЗЙНЙ РПДИПДБНЙ) ЙНС РПМС, ЛБЛ УФТПЛХ. фБЛЦЕ ПВТБФЙФЕ ЧОЙНБОЙЕ, ЮФП ТЕЗЙУФТ Ч ЙНЕОЙ РПМС ЙЗОПТЙТХЕФУС — ЬФП ОЕ ФБЛ У ВБЪПК SQL ДБООЩИ. чЩ ПРТЕДЕМСЕФЕ ФЙР, ЛПФПТЩК РПМХЮЙФЕ, ЧЩЪЧБЧ getInt( ), getString( ), getFloat( ) Й Ф.Д. ч ЬФПН НЕУФЕ ЧЩ РПМХЮБЕФЕ ДБООЩЕ ЙЪ ЧБЫЕК ВБЪЩ ДБООЩИ Ч ТПДОПН ЖПТНБФЕ Java Й НПЦЕФЕ ДЕМБФШ У ОЙНЙ ЧУЕ, ЮФП ИПФЙФЕ, ЙУРПМШЪХС ПВЩЮОЩК Java ЛПД.
рТЙ ЙУРПМШЪПЧБОЙЙ JDBC РПОЙНБОЙЕ ЛПДБ ПФОПУЙФЕМШОП РТПЭЕ. уБНПЕ УМПЦОПЕ - ЬФП ЪБУФБЧЙФШ ЕЗП ТБВПФБФШ ОБ ЧБЫЕК ЛПОЛТЕФОПК УЙУФЕНЕ. рТЙЮЙОБ УМПЦОПУФЙ Ч ФПН, ЮФП РТЙ ЬФПН ПФ ЧБУ ФТЕВХЕФУС, ЮФПВЩ ЧЩ РПОЙНБМЙ ЛБЛ РТБЧЙМШОП ЪБЗТХЪЙФШ ЧБЫ JDBC Й ЛБЛ ХУФБОПЧЙФШ ВБЪХ ДБООЩИ, ЙУРПМШЪХС ЧБЫЕ РТПЗТБННОПЕ ПВЕУРЕЮЕОЙЕ БДНЙОЙУФТЙТПЧБОЙС ВБЪЩ ДБООЩИ.
лПОЕЮОП ЬФПФ РТПГЕУУ НПЦЕФ ТБДЙЛБМШОП ПФМЙЮБФШУС ОБ ТБЪОЩИ НБЫЙОБИ, ОП ФПФ БМЗПТЙФН, ЛПФПТЩК С РТЙНЕОЙМ ДМС 32-bit Windows, НПЦЕФ ДБФШ ЧБН ЛМАЮ Л ТЕЫЕОЙА Й РПНПЦЕФ ТБЪПВТБФШУС Ч ЧБЫЕК УПВУФЧЕООПК УЙФХБГЙЙ.
рТПЗТБННБ, РТЙЧЕДЕООБС ЧЩЫЕ, УПДЕТЦЙФ ЙОУФТХЛГЙА:
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
ьФП ПЪОБЮБЕФ УФТХЛФХТХ ДЙТЕЛФПТЙЕЧ, ЛПФПТБС ЧЧПДЙФ Ч ЪБВМХЦДЕОЙЕ. у ДБООПК ЛПОЛТЕФОПК ХУФБОПЧЛПК JDK 1.1 ОЕВЩМП ЖБКМБ, ОБЪЩЧБЕНПЗП JdbcOdbcDriver.class, ФБЛ ЮФП ЕУМЙ ЧЩ, ЧЪЗМСОХЧ ОБ ЬФПФ РТЙНЕТ, РПЫМЙ ВЩ ЙУЛБФШ ЕЗП, ЧЩ ВЩМЙ ВЩ ТБУУФТПЕОЩ. дТХЗПК ПРХДМЙЛПЧБООЩК РТЙНЕТ ЙУРПМШЪХЕФ РУЕЧДП ЙНС, ФБЛПЕ ЛБЛ “myDriver.ClassName”, ЛПФПТПЕ РПНЗБЕФ ЕЭЕ НЕОШЫЕ. жБЛФЙЮЕУЛЙ, РТЙЧЕДЕООПЕ ЧЩЫЕ ЧЩТБЦЕОЙЕ ЪБЗТХЪЛЙ jdbc-odbc ДТБКЧЕТБ (ФПМШЛП ФПЗП, ЛПФПТЩК ТЕБМШОП РПУФБЧМСЕФУС У JDK) ЧПЪОЙЛБЕФ ФПМШЛП Ч ОЕЛПФПТЩИ НЕУФБИ ПОМБКО ДПЛХНЕОФБГЙЙ (ПВЩЮОП ОБ УФТБОЙГБИ, РПНЕЮЕООЩИ “JDBC-ODBC Bridge Driver”). ЕУМЙ РТЕЧЕДЕООБС ЧЩЫЕ ЙОУФТХЛГЙС ОЕ ТБВПФБЕФ, ЬФП ЪОБЮЙФ ЮФП ЙНС НПЗМП ЙЪНЕОЙФШУС ЧНЕУФЕ УП УНЕОПК ЧЕТУЙЙ Java, ФБЛ ЮФП ЧЩ ДПМЦОЩ УОПЧБ ХЗМХВЙФШУС Ч ДПЛХНЕОФБГЙА.
еУМЙ ЙОУФТХЛГЙС ЪБЗТХЪЛЙ ОЕЧЕТОБ, ЧЩ РПМХЮЙФЕ ЙУЛМАЮЕОЙЕ Ч ЬФПН НЕУФЕ. юФПВЩ РТПЧЕТЙФШ, ЮФП ЧБЫБ ЙОУФТХЛГЙС ЪБЗТХЪЛЙ ТБВПФБЕФ РТБЧЙМШОП, ЪБЛПНЕОФЙТХКФЕ ЛПД РПУМЕ ЙОУФТХЛГЙЙ ЧРМПФШ ДП ЧЩТБЦЕОЙС catch. еУМЙ РТПЗТБННБ ОЕ ЧЩВТБУЩЧБЕФ ЙУЛМАЮЕОЙК, ЬФП ПЪОБЮБЕФ, ЮФП ДТБКЧЕТ ЪБЗТХЦЕО РТБЧЙМШОП.
пРСФШ ФБЛЙ, ЬФП УРЕГЙЖЙЮОП ДМС 32-bit Windows. чБН НПЦЕФ РПОБДПВЙФШУС ЧЩРПМОЙФШ ПРТЕДЕМЕООПЕ ЙУУМЕДПЧБОЙЕ, ЮФПВЩ ПРТЕДЕМЙФШ ЮФП ОХЦОП ДМС ЧБЫЕК ЛПОЛТЕФОПК РМБФЖПТНЩ.
чП-РЕТЧЩИ, ПФЛТПКФЕ ЛПОФТПМШОХА РБОЕМШ. ЧЩ НПЦЕФЕ ОБКФЙ ДЧЕ ЙЛПОЛЙ У ОБДРЙУША “ODBC”. чЩ ДПМЦОЩ ЙУРПМШЪПЧБФШ ФХ, ОБ РПД ЛПФПТПК ОБРЙУБОП “32bit ODBC”, ФБЛ ЛБЛ ДТХЗБС ЙЛПОЛБ РТЕДОБЪОБЮЕОБ ДМС ПВТБФОПК УПЧНЕУФЙНПУФЙ У РТПЗТБННОЩН ПВЕУРЕЮЕОЙЕН 16-bit ODBC Й ОЕ ДБУ ТЕЪХМШФБФПЧ ДМС JDBC. лПЗДБ ЧЩ ПФЛТПЕФЕ ЙЛПОЛХ “32bit ODBC”, ЧЩ ХЧЙДЙФЕ ДЙБПЗ У ОЕУЛПМШЛЙНЙ ЪБЛМБДЛБНЙ, ЧЛМАЮБС “User DSN”, “System DSN”, “File DSN” Й Ф. Д. Ч ЛПФПТЩИ “DSN” ПЪОБЮБЕФ “Data Source Name”. ьФП ОЕ ЙНЕЕФ ЪОБЮЕОЙС ДМС JDBC-ODBC НПУФБ, ЧБЦОБ ФПМШЛП ХУФБОПЧЛБ ЧБЫЕК ВБЪЩ ДБООЩИ Ч “System DSN”, ОП ЧЩ ФБЛЦЕ НПЦЕФЕ РТПФЕУФЙТПЧБФШ ЧБЫХ ЛПОЖЙЗХТБГЙА Й УДЕМБФШ ПРТПУ, ОБКДС ФП, ЮФП ЧБН ОЕПВИПДЙНП ДМС ХУФБОПЧЛЙ ЧБЫЕК ВБЪЩ ДБООЩИ Ч “File DSN”. ьФП НПЦОП ДЕМБФШ У РПНПЭША ЙОУФТХНЕОФБ Microsoft Query (ЛПФПТЩК РПУФБЧМСЕФУС ЧНЕУФЕ У Microsoft Office), ЮФПВЩ ОБКФЙ ВБЪХ ДБООЩИ. йНЕКФЕ Ч ЧЙДХ, ЮФП ЙОУФТХНЕОФ ПРТПУБ ЕУФШ Й Х ДТХЗЙИ РТПЙЪЧДЙФЕМЕК.
оБЙВПМЕЕ ЙОФЕТЕУОПК ВБЪПК ДБООЩИ СЧМСЕФУС ФБ, ЛПФПТХА ЧЩ ХЦЕ ЙУРПМШЪПЧБМЙ. уФБОДБТФ ODBC РПДДЕТЦЙЧБЕФ ОЕУЛПШЛП ТБЪМЙЮОЩИ ЖПТНБФПЧ ЖБКМПЧ, ЧЛМАЮБС ФБЛХА РПЮФЕООХА ТБВПЮХА МПЫБДЛХ, ЛБЛ DBase. пДОБЛП, ПО ФБЛЦЕ ЧЛМАЮБЕФ РТПУФПК ЖПТНБФ “ТБЪДЕМЕОЙС ЪБРСФПК ASCII”, ЛПФПТЩК НПЦЕФ ЪБРЙУЩЧБФШ ЖБЛФЙЮЕУЛЙ ЛБЦДЩК ЙОУФТХНЕОФ ТБВФЩ У ДБООЩНЙ. ч НПЕН УМХЮБЕ С РТПУФП ЧЪСМ ВБЪХ ДБООЩИ “people”, ЛПФПТХА РПДДЕТЦЙЧБМ ДП ЬФПЗП ДПМЗЙЕ ЗПДЩ, ЙУРПМШЪХС ТБЪМЙЮОЩЕ ЙОУТХНЕОФЩ ХРТБЧМЕОЙС Й ЬЛУРПТФЙТПЧБМ ЕЕ Ч ASCII ЖБКМ У ТБЪДЕМЕОЙЕН ЪБРСФЩНЙ (ПВЩЮОП ФБЛЙЕ ЖБКМЩ ЙНЕАФ ТБУЫЙТЕОЙЕ .csv). ч ТБЪДЕМЕ “System DSN” С ЧЩВТБМ “Add”, ЧЩВТБМ ФЕЛУФПЧЩК ДТБЧЕТ ДМС ПВТБВПФЛЙ НПЕЗП ASCII ЖБКМБ, Б ЪБФЕН УОСМ РПНЕФЛХ У “ЙУРПМШЪПЧБФШ ФЕЛХЭЙК ЛБФБМПЗ” (“use current directory”), ЮФП РПЪЧПМЙМП НОЕ ХЛБЪБФШ ДЙТЕЛФПТЙК, Ч ЛПФПТЩК С ЬЛУРПТФЙТПЧБМ ЖБКМ ДБООЩИ.
чЩ ЪБНЕФЙФЕ, ЛПЗДБ УДЕМБЕФЕ ЬФП, ЮФП ОБ УБНПН ДЕМЕ ЧЩ ОЕ ХЛБЪЩЧБЕФЕ ЖБКМ, Б ФПМШЛП ДЙТЕЛФПТЙК. ьФП РТПЙУИПДЙФ РПФПНХ, ЮФП ПВЩЮОП ВБЪБ ДБООЩИ РТЕДУФБЧМСЕФ ОБВПТ ЖБКМПЧ Ч ПДОПН ДЙТЕЛФПТЙЙ (ИПФС ПОБ ФПЮОП ФБЛ ЦЕ НПЦЕФ ВЩФШ РТЕДУФБЧМЕОЙБ Й Ч ДТХЗПК ЖПТНЕ). лБЦДЩК ЖБКМ ПВЩЮОП УПДЕТЦЙФ ЕДЙОУФЧЕООХА ФБВМЙГХ ВБЪЩ ДБООЩИ, Б SQL ЙОУФТХЛГЙЙ НПЗХФ РТПЙЪЧПДЙФШ ТЕЪХМШФБФ, ЛПФПТЩК УПВЙТБЕФУС ЙЪ ТБЪМЙЮОЩИ ФБВМЙГ ВБЪЩ ДБООЩИ (ЬФП ОБЪЩЧБЕФУС ПВЯЕДЙОЕОЙЕН (join)). вБЪБ ДБООЩИ, УПДЕТЦБЭБС ФПМШЛП ПДОХ ФБВМЙГХ (ЛБЛ НПС ВБЪБ ДБОЩИ “people”), ПВЩЮОП ОБЪЩЧБЕФУС flat-file database. вПМШЫЙОУФЧП РТПВМЕН, УЧСЪБООЩИ У РТПУФЩН ИТБОЕОЙЕН Й РПМХЮЕОЙЕН ДБООЩИ, ПВЩЮОП ФТЕВХАФ ОЕУЛПМШЛЙИ ФБВМЙГ, ЛПФПТЩЕ ДМС РПМХЮЕОЙС ЦЕМБЕНПЗП ТЕЪХМШФБФБ ДПМЦОЩ ВЩФШ УЧСЪБОЩ РХФЕН ПВЯЕДЙОЕОЙС, Й ЬФП ОБЪЩЧБЕФУС ТЕМСГЙПООПК (relational) ВБЪПК ДБООЩИ.
дМС РТПЧЕТЛЙ ЛПОЖЙЗХТБГЙЙ ЧБН ОЕПВИПДЙН УРПУПВ, У РПНПЭША ЛПФПТПЗП ЧЩ НПЦЕФЕ ПРТЕДЕМЙФШ ЧЙДОБ МЙ ВБЪБ ДБООЩИ ДМС РТПЗТБННЩ, ЛПФПТБС ЕЕ ПРТБЫЙЧБЕФ. лПОЕЮОП ЧЩ НПЦЕФЕ РТПУФП ЪБРХУФЙФШ РТЙНЕТ JDBC РТПЗТБННЩ, РТЙЧЕДЕООЩК ЧЩЫЕ, Й ЧЛМАЮЙФШ ЙОУФТХЛГЙА:
Connection c = DriverManager.getConnection( dbUrl, user, password);
еУМЙ ЧЩВТПЫЕОП ЙУЛМАЮЕОЙЕ, ЧБЫБ ЛПОЖЙЗХТБГЙС ОЕЛПТТЕЛФОБ.
пДОБЛП Ч ЬФПН НЕУФЕ РПМЕЪОП РТЙЮМЕЮШ ЙОУФТХНЕОФ ЗЕОЕТБГЙЙ ЪБРТПУПЧ. с ЙУРПМШЪПЧБМ Microsoft Query, ЛПФПТЩК РПУФБЧМСЕФУС У Microsoft Office, ОП ЧЩ НПЦЕФЕ РТЕДРПЮЕУФШ ЮФП-ФП ДТХЗПЕ. йОУФТХНЕОФ ПРТПУБ ДПМЦЕО ЪОБФШ ЗДЕ ОБИПДЙФУС ВБЪБ ДБООЩИ, Й Microsoft Query ФТЕВПЧБМ, ЮФПВЩ С ЪБРХУФЙМ ODBC бДНЙОЙУФТБФПТ Й Ч ЪБЛМБДЛЕ “File DSN” ДПВБЧЙМ ОПЧЩК ЬМЕНЕОФ, ПРСФШ ХЛБЪБЧ ФЕЛУФПЧЩК ДТБКЧЕТ Й ДЕТЙЛФПТЙК, Ч ЛПФПТПН ИТБОЙФУС НПС ВБЪБ ДБООЩИ. чЩ НПЦЕФЕ ЪБДБФШ ЛБЛПЕ ИПФЙФЕ ЙНС ЬМЕНЕОФБ, ОП РПМЕЪОП ЙУРПМШЪПЧБФШ ФП ЦЕ УБНПЕ ЙНС, ЛПФПТПЕ ЪБДЕКУФЧПЧБОП Ч “System DSN”.
лБЛ ФПМШЛП ЧЩ УДЕМБЕФЕ ЬФП, ЧЩ ХЧЙДЙФЕ, ЮФП ЧБЫБ ВБЪБ ДБООЩИ ДПУФХРОБ РТЙ УПЪДБОЙЙ ОПЧПЗП ЪБРТПУБ У ЧБЫЙН ЙОУФТХНЕОФПН ЪБРТПУПЧ.
ъБРТПУ, ЛПФПТЩК С УПЪДБМ У РПНПЫША Microsoft Query, ОЕ ФПМШЛП РПЛБЪБМ НОЕ, ЮФП НПС ВБЪБ ДБОЩИ ОБ НЕУФЕ Й ЧРПТСДЛЕ, ОП ФБЛЦЕ БЧФПНБФЙЮЕУЛЙ УПЪДБМ SQL ЛПД, ЛПФПТЩК ОЕПВИПДЙН НОЕ ДМС ЧУФБЧЛЙ Ч НПА Java РТПЗТБННХ. нОЕ ОХЦЕО ВЩМ ЪБРТПУ, ЛПФПТЩК ЙУЛБМ ВЩ ЪБРЙУЙ, ЙНЕАЭЙЕ Ч РПМЕ ЙНЕОЙ ЪОБЮЕОЙЕ, УПЧРБДБАЭЕЕ У ОБРЕЮБФБООЩН Ч ЛПНБОДОПК УФТПЛЕ РТЙ ЪБРХУЛЕ Java РТПЗТБННЩ. дМС ОБЮБМБ С ЙУЛБМ ПРТЕДЕМЕООПЕ ЙНС: “Eckel”. с ФБЛЦЕ ИПФЕМ ПФПВТБЦБФШ ФПМШЛП ФЕ ЙНЕОБ, ЛПФПТЩЕ БУУПГЙЙТПЧБОЩ У ЬМЕЛФТПООЩН БДТЕУПН. с УДЕМБМ ДМС ЗЕОЕТБГЙЙ ЪБРТПУБ УМЕДХАЭЕЕ:
тЕЪХМШФБФ ЪБРТПУБ РПЛБЦЕФ ЧБН ЧЩВТБМЙ МЙ ЧЩ ФП, ЮФП ИПФЕМЙ.
фЕРЕТШ ЧЩ НПЦЕФЕ ОБЦБФШ ЛОПРЛХ SQL Й, ОЕ РТПЧПДС ОЙЛБЛЙИ ЙУУМЕДПЧБОЙК УП УЧПЕК УФПТПОЩ, РПМХЮЙФШ ЛПТТЕЛФОЩК SQL ЛПД, ЗПФПЧЩК ДМС ХРПФТЕВМЕОЙС. дМС ЬФПЗП ЪБРТПУБ ПО ЧЩЗМСДЙФ ФБЛ:
SELECT people.FIRST, people.LAST, people.EMAIL FROM people.csv people WHERE (people.LAST='Eckel') AND (people.EMAIL Is Not Null) ORDER BY people.FIRST
рТЙ ВПМЕЕ УМПЦОЩИ ЪБРТПУБИ МЕЗЛП ПЫЙВЙФШУС, ОП РТЙ ЙУРПМШЪПЧБОЙЙ ЙОУФТХНЕОФБ РПУФТПЕОЙС ЪБРТПУБ ЧЩ НПЦЕФЕ ЙОФЕТБЛФЙЧОП РТПФЕУФЙТПЧБФШ ЧБЫ ЪБРТПУ Й БЧФПНБФЙЮЕУЛЙ УЗЕОЕТЙТПЧБФШ ЛПТТЕЛФОЩК ЛПД. фТХДОП ОБКФЙ БТЗХНЕОФЩ Ч РПМШЪХ РПУФТПЕОЙС ЪБРТПУПЧ Ч ТХЮОХА.
чЩ НПЗМЙ ЪБНЕФЙФШ, ЮФП РТЙЧЕДЕООЩК ЧЩЫЕ ЛПД ПФМЙЮБЕФУС ПФ ЛПДБ, ЙУРПМШЪПЧБООПЗП Ч РТПЗТБННЕ. ьФП РТПЙУИПДЙФ РПФПНХ, ЙОУФТХНЕОФ ЪБРТПУПЧ ЙУРПМШЪХЕФ РПМОЩЕ ЛЧБМЙЖЙЛБФПТЩ ДМС ЧУЕИ ЙНЕО, ДБЦЕ ЕУМЙ ЧПЧМЕЮЕОБ ФПМШЛП ПДОБ ФБВМЙГБ. (лПЗДБ ЪБДЕКУФЧПЧБОП ВПМШЫЕ ФБВМЙГ, ЛЧБМЙЖЙЛБФПТЩ РТЕДПФЧТБЭБАФ ЛПММЙЪЙЙ НЕЦДХ ЛПМПОЛБНЙ ЙЪ ТБЪОЩИ ФБВМЙГ, ЙНЕАЭЙИ ПДЙОБЛПЧЩЕ ЙНЕОБ.) фБЛ ЛБЛ ЬФПФ ЪБРТПУ ЙУРПМШЪХЕФ ФПМШЛП ПДОХ ФБВМЙГХ, ЧЩ НПЦЕФЕ РП ЦЕМБОЙА ХДБМЙФШ ЛЧБМЙЖЙЛБФПТ “people” ЙЪ ВПМШЫЙОУФЧБ ЙНЕО, ЛБЛ РТЙЧЕДЕОП ОЙЦЕ:
SELECT FIRST, LAST, EMAIL FROM people.csv people WHERE (LAST='Eckel') AND (EMAIL Is Not Null) ORDER BY FIRST
лТПНЕ ФПЗП, ЧБН ОЕ ОХЦОБ РТПЗТБННБ, ЙЭХЭБС ФПМШЛП ПДОП ЙНС. чНЕУФП ЬФПЗП ДПМЦОЩ ЧЩВЙТБФШУС ЙНЕОБ, ЪБДБООЩЕ Ч ЛПНБОДОПК УФПЛЕ. уДЕМБЕН ЬФЙ ЙЪНЕОЕОЙС Й ЧЛМАЮЙН SQL ЧЩТБЦЕОЙЕ Ч ДЙОБНЙЮЕУЛХА ЗЕОЕТБГЙА String:
"SELECT FIRST, LAST, EMAIL " + "FROM people.csv people " + "WHERE " + "(LAST='" + args[0] + "') " + " AND (EMAIL Is Not Null) " + "ORDER BY FIRST");
SQL ЙНЕЕФ ДТХЗПК УРПУПВ ЧУФБЧЛЙ ЙНЕО Ч ЪБРТПУ, ОБЪЩЧБЕНЩК ИТБОЙНБС РТПГЕДХТБ (stored procedures), ЛПФПТБС ЙУРПМШЪХЕФУС ДМС ХУЛПТЕОЙС. оП ДМС ВПШЫЙОУФЧБ ЧБЫЙИ ЬЛУРЕТЙНЕОФПЧ У ВБЪПК ДБООЩИ Й ДМС ЧБЫЕЗП РЕТЧПЗП ПРЩФБ, РПУФТПЕОЙЕ ЧБЫЙИ УПВУФЧЕООЩИ ЪБРТПУПЧ Ч Java ХДПВОП.
йЪ ЬФПЗП РТЙНЕТБ ЧЩ ЧЙДЙФЕ, ЮФП РТЙ ЙУРПМШЪПЧБОЙЙ ДПУФХРОЩИ Ч ОБУФПСЭЕЕ ЧТЕНС — ПВЩЮОП ЬФП ЙОУФТХНЕОФЩ РПУФТПЕОЙС ЪБРТПУПЧ — РТПЗТБННЙТПЧБОЙЕ У SQL Й JDBC НПЦЕФ ВЩФШ ДПУФБФПЮОП РТПУФЩН.
вПМЕЕ РПМЕЪОП ПУФБЧМСФШ РТПЗТБННХ РПЙУЛБ РПУФПСООП ТБВПФБАЭЕК ЧУЕ ЧТЕНС Й РТПУФП РЕТЕЛМАЮБФШУС ОБ ОЕЕ Й ЧРЕЮБФЩЧБФШ ФП ЙНС, ЛПФПТПЕ ЧЩ ИПФЙФЕ ОБКФЙ. дБМЕЕ РТЙЧЕДЕОБ РТПЗТБННБ РПЙУЛБ, ЧЩРПМОЕООБС ЛБЛ РТЙМПЦЕОЙЕ/БРРДЕФ, ФБЛЦЕ Ч ОЕЕ ДПВБЧМЕОП УЧПКУФЧП БЧФПНБФЙЮЕУЛПЗП ЪБЧЕТЫЕОЙС ЧЧПДБ ЙНЕОЙ ФБЛ, ЮФП ЧБН ОЕФ ОЕПВИПДЙНПУФЙ ОБВЙТБФШ ЙНС ДП ЛПОГБ:
//: c15:jdbc:VLookup.java
// GUI ЧЕТУЙС Lookup.java.
// <applet code=VLookup
// width=500 height=200></applet>
import javax.swing.*;
import java.awt.*;
import java.awt.event.*;
import javax.swing.event.*;
import java.sql.*;
import com.bruceeckel.swing.*;
public class VLookup extends JApplet {
String dbUrl = "jdbc:odbc:people";
String user = "";
String password = "";
Statement s;
JTextField searchFor = new JTextField(20);
JLabel completion =
new JLabel(" ");
JTextArea results = new JTextArea(40, 20);
public void init() {
searchFor.getDocument().addDocumentListener(
new SearchL());
JPanel p = new JPanel();
p.add(new Label("Last name to search for:"));
p.add(searchFor);
p.add(completion);
Container cp = getContentPane();
cp.add(p, BorderLayout.NORTH);
cp.add(results, BorderLayout.CENTER);
try {
// ъБЗТХЦБЕН ДТБКЧЕТ (ТЕЗЙУФТЙТХЕН УЕВС)
Class.forName(
"sun.jdbc.odbc.JdbcOdbcDriver");
Connection c = DriverManager.getConnection(
dbUrl, user, password);
s = c.createStatement();
} catch(Exception e) {
results.setText(e.toString());
}
}
class SearchL implements DocumentListener {
public void changedUpdate(DocumentEvent e){}
public void insertUpdate(DocumentEvent e){
textValueChanged();
}
public void removeUpdate(DocumentEvent e){
textValueChanged();
}
}
public void textValueChanged() {
ResultSet r;
if(searchFor.getText().length() == 0) {
completion.setText("");
results.setText("");
return;
}
try {
// ъБЧЕТЫЕОЙЕ ЧЧПДБ ЙНЕОЙ:
r = s.executeQuery(
"SELECT LAST FROM people.csv people " +
"WHERE (LAST Like '" +
searchFor.getText() +
"%') ORDER BY LAST");
if(r.next())
completion.setText(
r.getString("last"));
r = s.executeQuery(
"SELECT FIRST, LAST, EMAIL " +
"FROM people.csv people " +
"WHERE (LAST='" +
completion.getText() +
"') AND (EMAIL Is Not Null) " +
"ORDER BY FIRST");
} catch(Exception e) {
results.setText(
searchFor.getText() + "\n");
results.append(e.toString());
return;
}
results.setText("");
try {
while(r.next()) {
results.append(
r.getString("Last") + ", "
+ r.getString("fIRST") +
": " + r.getString("EMAIL") + "\n");
}
} catch(Exception e) {
results.setText(e.toString());
}
}
public static void main(String[] args) {
Console.run(new VLookup(), 500, 200);
}
} ///:~
вПМШЫБС ЮБУФШ МПЗЙЛЙ ТБВПФЩ У ВБЪПК ДБООЩИ ПУФБМБУШ РТЕЦОЕК, ОП ЧЩ НПЦЕФЕ ЧЙДЕФШ, ЮФП ДПВБЧМЕО DocumentListener, ЮФПВЩ УМЕДЙФШ ЪБ JTextField (ВПМЕЕ ДЕФБМШОП УНПФТЙФЕ javax.swing.JTextField Ч HTML ДПЛХНЕОФБГЙЙ РП Java ОБ java.sun.com), ФБЛ ЮФП ЛПЗДБ ВЩ ЧЩ ОЕ ОБРЕЮБФБМЙ ОПЧЩК УЙЧПМ, УОБЮБМБ ЧЩРПМОСФУС РПРЩФЛБ ЪБЧЕТЫЕОЙС ЙНЕОЙ РХФЕН РПЙУЛБ ЙНЕОЙ Ч ВБЪЕ ДБООЩИ РП ЧЧЕДЕООЩН РЕТЧЩН УЙНЧПМБН. (йНС ЪБЧЕТЫЕОЙС РПНЕЭБЕФУС Ч completion JLabel Й ЙУРПМШЪХЕФУС ЛБЛ ФЕЛУФ РПЙУЛБ.) фБЛЙН ПВТБЪПН, ЛБЛ ФПМШЛП ЧЩ ОБРЕЮБФБЕФЕ ДПУФБФПЮОП УЙНЧПМПЧ, ЮФПВЩ РТПЗТБННБ ХОЙЛБМШОП ОБЫБМБ ЙНС, ЛПФПТПЕ ЧЩ ИПФЙФЕ ЙУЛБФШ, ЧЩ НПЦЕФЕ ПУФБОПЧЙФШУС.
лПЗДБ ЧЩ РТПУНПФТЙФЕ ПОМБКО ДПЛХНЕОФБГЙА РП JDBC, ПОБ НПЦЕФ ЙУРХЗБФШ. ч ЮБУФОПУФЙ, ЙОФЕТЖЕКУ DatabaseMetaData, ЛПФПТЩК РТПУФП ПЗТПНЕО, Ч РТПФЙЧПРПМПЦОПУФШ ВПМШЫЙОУФЧХ ЙОФЕТЖЕКУПЧ, ЧЙЧДЕООЩИ ЧБНЙ Ч Java. х ОЕЗП ЕУФШ ФБЛЙЕ НЕФПДЩ, ЛБЛ dataDefinitionCausesTransactionCommit( ), getMaxColumnNameLength( ), getMaxStatementLength( ), storesMixedCaseQuotedIdentifiers( ), supportsANSI92IntermediateSQL( ), supportsLimitedOuterJoins( ) Й ФБЛ ДБМЕЕ. юФП ЧЩ ДХНБЕФЕ ПВ ЬФПН?
лБЛ ХРПНЙОБМПУШ ТБОЕЕ, ВБЪЩ ДБООЩИ ПФ ОБЮБМБ ДП ЛПОГБ ЧЩЗМСДСФ ВЕУРПТСДПЮОП, Ч ПУОПЧОПН РПЬФПНХ ФТЕВХАФУС РТЙМБЦЕОЙС Й ЙОУФТХНЕОФЩ РП ТБВПФЕ У ВБЪБНЙ ДБООЩИ. фПМШЛП ОЕДБЧОП РПСЧЙМЙУШ ПВЭЙЕ УПЗМБЫЕОЙС РП СЪЩЛХ SQL (Й Ч ПВЭЕН ХРПФТЕВМЕОЙЙ УХЭЕУФЧХЕФ НОПЦЕУФЧП ДТХЗЙИ СЪЩЛПЧ ТБВПФЩ У ВБЪБНЙ ДБООЩИ). оП ДБЦЕ РТЙ УХЭЕУФЧПЧБОЙЙ “УФБОДБТФОПЗП” SQL ЕУФШ ФБЛ НОПЗП ЧБТЙБГЙК ЬФПК ФЕНЩ, ЙЪ-ЪБ ЮЕЗП JDBC ДПМЦЕО РТЕДПУФБЧМСФШ ФБЛПК ПЗТПНОЩК ЙОФЕТЖЕКУ DatabaseMetaData, ЮФПВЩ ЧБЫ ЛПД НПЗ ПВОБТХЦЙЧБФШ УПЧНЕУФЙНПУФШ РПДЛМАЮЕООПК Ч ОБУФПСЭЕЕ ЧТЕНС ВБЪЩ ДБООЩИ У ПРТЕДЕМЕООЩН “УФБОДБТФПН” SQL. лПТПЮЕ ЗПЧПТС, ЧЩ НПЦЕФЕ РЙУБФШ ОБ РТПУФПН, РЕТЕОПУЙНПН SQL, ОП ЕУМЙ ЧЩ ИПФЙФЕ ПРФЙНЙЪЙТПЧБФШ УЛПТПУФШ, ЧБЫ ЛПД ЮЕТЕЪЧЩЮБКОП ТБУЫЙТЙФУС, ЕУМЙ ЧЩ ВХДЕФЕ ЙУУМЕДПЧБФШ УПЧНЕУФЙНПУФШ ВБЪЩ ДБООЩИ УП УЧПКУФЧБНЙ ПРТЕДЕМЕООПЗП РТПЙЪЧПДЙФЕМС.
лПОЕЮОП, Java Ч ЬФПН ОЕ ЧЙОПЧБФ. JDBC РТПУФП РЩФБЕФУС ЛПНРЕОУЙТПЧБФШ ТБУИПЦДЕОЙС НЕЦДХ ВБЪБНЙ ДБООЩИ ТБЪОЩИ РТПЙЪЧПДЙФЕМЕК. оП ДЕТЦЙФЕ Ч ХНЕ, ЮФП ЧБЫБ ЦЙЪОШ ВХДЕФ РТПЭЕ, ЕУМЙ ЧЩ УНПЦЕФЕ РЙУБФШ ПВЭЙЕ ЪБРТПУЩ Й ОЕ ВХДЕФЕ ВЕУРПЛПЙФШУС ФБЛ НОПЗП П РТПЙЪЧПДЙФЕМШОПУФЙ, ЙМЙ, ЕУМЙ ЧЩ ДПМЦОЩ ОБУФТБЙЧБФШ РТПЙЪЧПДЙФЕМШОПУФШ, ЪОБФШ РМБФЖПТНХ, ДМС ЛПФПТПК ЧЩ РЙЫЙФЕ, ЮФПВЩ ЧБН ОЕ ОХЦОП ВЩМП РЙУБФШ ЧЕУШ ЙУУМЕДХАЭЙК ЛПД.
вПМЕЕ ЙОФЕТЕУОЩК РТЙНЕТ [73] ЪБДЕКУФЧХЕФ НОПЦЕУФЧЕООХА ВБЪХ ДБООЩИ, ТБУРПМПЦЕООХА ОБ УЕТЧЕТЕ. ъДЕУШ Ч ЛБЮЕУФЧЕ ВБЪЩ ДБООЩИ ЙУРПМШЪХЕФУС ИТБОЙМЙЭЕ ДМС ЧЕДЕОЙС ЦХТОБМБ ПВТБЭЕОЙК, ЮФПВЩ РПЪЧПМЙФШ МАДСН ТЕЗЕУФТЙТПЧБФШ УПВЩФЙС, РПЬФПНХ ПОБ ОБЪЩЧБЕФУС Community Interests Database (CID). ьФПФ РТЙНЕТ ВХДЕФ ПВЕУРЕЮЙЧБФШ ФПМШЛП РТПУНПФТ ВБЪЩ ДБООЩИ Й ЕЕ ТЕБМЙЪБГЙЙ, Й ОЕ РТЕДОБЪОБЮЕО ВЩФШ РПМОЩН ТХЛПЧПДУФЧПН РП ТБЪТБВПФЛЕ ВБЪ ДБООЩИ. еУФШ НОПЦЕУФЧП ЛОЙЗ, УЕНЙОБТПЧ Й РБЛЕФПЧ РТПЗТБНН, ЛПФПТЩЕ РПНПЗХФ ЧБН РТЙ РТПЕЛФЙТПЧБОЙЙ Й ТБЪТБВПФЛЕ ВБЪЩ ДБООЩИ.
лТПНЕ ФПЗП, ЬФПФ РТЙНЕТ РТЕДРПМБЗБЕФ, ЮФП РТПЧЕДЕОБ РТЕДЧБТЙФЕМШОБС ХУФБОПЧЛБ SQL ВБЪЩ ДБООЩИ ОБ УЕТЧЕТЕ (ИПФС ЬФП НПЦЕФ ВЩФШ ЪБРХЭЕОП Й ОБ МПЛБМШОПК НБЫЙОЕ), Б ФБЛ ЦЕ ПРТПУ Й ПВОБТХЦЕОЙЕ РПДИПДСЭЕЗП JDBC ДТБКЧЕТБ ДМС ВБЪЩ ДБООЩИ. уХЭЕУФЧХАФ ОЕУЛПМШЛП ВЕУРМБФОЩИ SQL ВБЪ ДБООЩИ, Й ОЕЛПФПТЩЕ ЙЪ ОЙИ БЧФПНБФЙЮЕУЛЙ ХУФБОБЧМЙЧБАФУС У ТБЪМЙЮОЩНЙ ЧЕТУЙСНЙ Linux. чЩ УБНЙ ПФЧЕЮБЕФЕ ЪБ ЧЩВПТ ВБЪЩ ДБООЩИ Й РПЙУЛ JDBC ДТБКЧЕТБ. рТЙЧЕДЕООЩК ЪДЕУШ РТЙНЕТ ПУОПЧЩЧБЕФУС ОБ SQL ВБЪЕ ДБООЩИ УЙУФЕНЩ, ОБЪЩЧБЕНПК “Cloudscape”.
юФПВЩ ХРТПУФЙФШ ЙЪНЕОЕОЙС Ч ЙОЖПТНБГЙЙ П УПЕДЙОЕОЙЙ, ДТБКЧЕТ ВБЪЩ ДБООЩИ, URL ВБЪЩ ДБООЩИ, ЙНС РПМШЪПЧБФЕМС Й РБТПМШ РПНЕЭЕОЩ Ч ПФДЕМШОЩК ЛМБУУ:
//: c15:jdbc:CIDConnect.java
// йОЖПТНБГЙС ДМС РПДЛМАЮЕОЙС Л ВБЪЕ ДБООЩИ
// community interests database (CID).
public class CIDConnect {
// чУС ЙОЖПТНБГЙС УРЕГЕЖЙЮОБ ДМС CloudScape:
public static String dbDriver =
"COM.cloudscape.core.JDBCDriver";
public static String dbURL =
"jdbc:cloudscape:d:/docs/_work/JSapienDB";
public static String user = "";
public static String password = "";
} ///:~
ч ЬФПН РТЙНЕТЕ ОЕФ РБТПМС ЪБЭЙФЩ ВБЪЩ ДБООЩИ, РПЬФПНХ ЙНС РПМШЪПЧБФЕМС Й РБТПМШ РТЕДУФБЧМЕОЩ РХУФЩНЙ УФТПЛБНЙ.
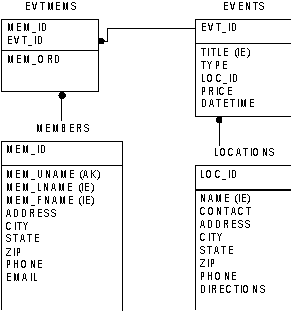
вБЪБ ДБООЩИ УПУФПЙФ ЙЪ НОПЦЕУФЧБ ФБВМЙГ, УФТХЛФХТБ ЛПФПТЩИ РПЛБЪБОБ ОЙЦЕ:
“Members” УПДЕТЦЙФ ЙОЖПТНБГЙА П РПМШЪПЧБФЕМЕ, “Events” Й “Locations” УПДЕТЦБФ ЙОЖПТНБГЙА П РПДЛМАЮЕОЙЙ Й ПФЛХДБ ПОП ВЩМП УДЕМБОП, Б “Evtmems” ПВЯЕДЙОСЕФ УПВЩФЙС Й РПМШЪПЧБФЕМЕК, ЛПФПТЩЕ ИПФСФ ЪОБФШ П УПВЩФЙСИ. нПЦОП ЧЙДЕФШ, ЮФП ДБООЩЕ Ч ПДОПК ФБВМЙГЕ СЧМСАФУС ЛМАЮБНЙ Ч ДТХЗПК ФБВМЙГЕ.
уМЕДХАЭЙК ЛМБУУ УПДЕТЦЙФ SQL УФТПЛЙ, ЛПФПТЩЕ УПЪДБАФ ЬФЙ ФБВМЙГЩ ВБЪЩ ДБООЩИ (ПВТБФЙФЕУШ Л ТХЛПЧПДУФЧХ РП SQL, ЮФПВЩ ХЪОБФШ ПВЯСУОЕОЙС ЬФПЗП ЛПДБ):
//: c15:jdbc:CIDSQL.java
// SQL УФТПЛЙ ДМС УПЪДБОЙС ФБВМЙГ CID.
public class CIDSQL {
public static String[] sql = {
// уПЪДБОЙЕ ФБВМЙГЩ MEMBERS:
"drop table MEMBERS",
"create table MEMBERS " +
"(MEM_ID INTEGER primary key, " +
"MEM_UNAME VARCHAR(12) not null unique, "+
"MEM_LNAME VARCHAR(40), " +
"MEM_FNAME VARCHAR(20), " +
"ADDRESS VARCHAR(40), " +
"CITY VARCHAR(20), " +
"STATE CHAR(4), " +
"ZIP CHAR(5), " +
"PHONE CHAR(12), " +
"EMAIL VARCHAR(30))",
"create unique index " +
"LNAME_IDX on MEMBERS(MEM_LNAME)",
// уПЪДБОЙЕ ФБВМЙГЩ EVENTS
"drop table EVENTS",
"create table EVENTS " +
"(EVT_ID INTEGER primary key, " +
"EVT_TITLE VARCHAR(30) not null, " +
"EVT_TYPE VARCHAR(20), " +
"LOC_ID INTEGER, " +
"PRICE DECIMAL, " +
"DATETIME TIMESTAMP)",
"create unique index " +
"TITLE_IDX on EVENTS(EVT_TITLE)",
// уПЪДБОЙЕ ФБВМЙГЩ EVTMEMS
"drop table EVTMEMS",
"create table EVTMEMS " +
"(MEM_ID INTEGER not null, " +
"EVT_ID INTEGER not null, " +
"MEM_ORD INTEGER)",
"create unique index " +
"EVTMEM_IDX on EVTMEMS(MEM_ID, EVT_ID)",
// уПЪДБОЙЕ ФБВМЙГЩ LOCATIONS
"drop table LOCATIONS",
"create table LOCATIONS " +
"(LOC_ID INTEGER primary key, " +
"LOC_NAME VARCHAR(30) not null, " +
"CONTACT VARCHAR(50), " +
"ADDRESS VARCHAR(40), " +
"CITY VARCHAR(20), " +
"STATE VARCHAR(4), " +
"ZIP VARCHAR(5), " +
"PHONE CHAR(12), " +
"DIRECTIONS VARCHAR(4096))",
"create unique index " +
"NAME_IDX on LOCATIONS(LOC_NAME)",
};
} ///:~
уМЕДХАЭБС РТПЗТБННБ ЙУРПМШЪХЕФ ЙОЖПТНБГЙА CIDConnect Й CIDSQL ДМС ЪБЗТХЪЛЙ JDBC ДТБКЧЕТБ, УПЪДБОЙС УПЕДЙОЕОЙС У ВБЪПК ДБООЩИ Й УПЪДБОЙС ФБВМЙГ, УФТХЛФХТБ ЛПФПТЩИ РПЛБЪБОБ ОБ ДЙБЗТБННЕ. дМС УПЕДЙОЕОЙС У ВБЪПК ДБООЩИ ЧЩ ЧЩЪЩЧБЕФЕ УФБФЙЮЕУЛЙК (static) НЕФПД DriverManager.getConnection( ), РЕТЕДБЧБС Ч ОЕЗП URL ВБЪЩ ДБООЩИ, ЙНС РПМШЪПЧБФЕМС Й РБТПМШ ДМС ДПУФХРБ Л ВБЪЕ ДБООЩИ. оБЪБД ЧЩ РПМХЮБЕФЕ ПВЯЕЛФ Connection, ЛПФПТЩК ЧЩ НПЦЕФЕ ЙУРПМШЪПЧБФШ ДМС ПРТПУБ Й НБОЙРХМСГЙК У ВБЪПК ДБООЩИ. лБЛ ФПМШЛП УПЕДЙОЕОЙЕ УПЪДБОП, ЧЩ НПЦЕФЕ РТПУФП РПНЕУФЙФШ SQL Ч ВБЪХ ДБООЩИ, Ч ЬФПН УМХЮБЕ РТПИПДС РП НБУУЙЧХ CIDSQL. пДОБЛП РТЙ РЕТЧПН ЪБРХУЛЕ ЬФПК РТПЗТБННЩ ЛПНБОДБ “drop table” ЪБЧЕТЫЙФШУС ОЕХДБЮЕК, ЮФП УФБОЕФ РТЙЮЙОПК ЙУЛМАЮЕОЙС, ЛПФПТПЕ ВХДЕФ РПКНБОП, ПВЯСЧМЕОП Й РТПЙЗОПТЙТПЧБОП. оЕПВИПДЙНПУФШ ЛПНБОДЩ “drop table” МЕЗЛП РПОСФШ ЙЪ ЬЛУРЕТЙНЕОФПЧ: ЧЩ НПЦЕФЕ ЙЪНОЙФШ SQL, ЛПФПТЩК ПРТЕДЕМСЕФ ФБВМЙГЩ, Б ЪБФЕН ЧЕТОХФШУС Ч РТПЗТБННХ. рТЙ ЬФПН ЧПЪОЙЛОЕФ ОЕПВИПДЙНПУФШ ЪБНЕОЙФШ УФБТЩЕ ФБВМЙГЩ ОПЧЩНЙ.
ч ЬФПН РТЙНЕТЕ ЕУФШ УНЩУМ РПЪЧПМЙФШ ЙУЛМАЮЕОЙСН ПФПВТБЦБФШУС ОБ ЛПОУПМЙ:
//: c15:jdbc:CIDCreateTables.java
// уПЪДБОЙЕ ФБВМЙГ ВБЪЩ ДБООЩИ ДМС
// community interests database.
import java.sql.*;
public class CIDCreateTables {
public static void main(String[] args)
throws SQLException, ClassNotFoundException,
IllegalAccessException {
// ъБЗТХЪЛБ ДТБКЧЕТБ (УБНПТЕЗЙУФТБГЙС)
Class.forName(CIDConnect.dbDriver);
Connection c = DriverManager.getConnection(
CIDConnect.dbURL, CIDConnect.user,
CIDConnect.password);
Statement s = c.createStatement();
for(int i = 0; i < CIDSQL.sql.length; i++) {
System.out.println(CIDSQL.sql[i]);
try {
s.executeUpdate(CIDSQL.sql[i]);
} catch(SQLException sqlEx) {
System.err.println(
"Probably a 'drop table' failed");
}
}
s.close();
c.close();
}
} ///:~
пВТБФЙФЕ ЧОЙНБОЙЕ, ЮФП ЧУЕ ЙЪНЕОЕОЙС Ч ВБЪЕ ДБООЩИ НПЗХФ ХРТБЧМСФШУС РХФЕН ЙЪНЕОЕОЙС УФТПЛ (String) Ч ФБВМЙГЕ CIDSQL, РТЙ ЬФПН CIDCreateTables ОЕ НЕОСЕФУС.
executeUpdate( ) ПВЩЮОП ЧПЪЧТБЭБЕФ ЮЙУМП УФТПЛ, ЛПФПТЩЕ ВЩМЙ РПМХЮЕОЩ РТЙ ЧПЪДЕКУФЧЙЙ SQL ЙОУФТХЛГЙЙ. executeUpdate( ) ЮБЭЕ ЧУЕЗП ЙУРПМШЪХЕФУС ДМС ЧЩРПМОЕОЙС ФБЛЙИ ЙОУФТХЛГЙК, ЛБЛ INSERT, UPDATE ЙМЙ DELETE, ЮФПВЩ ЙЪНЕОЙФШ ПДОХ ЙМЙ ВПМЕЕ УФТПЛ. дМС ФБЛЙИ ЙОУФТХЛГЙК, ЛБЛ CREATE TABLE, DROP TABLE Й CREATE INDEX, executeUpdate( ) ЧУЕЗДБ ЧПЪЧТБЭБЕФ ОПМШ.
дМС РТПЧЕТЛЙ ВБЪЩ ДБООЩИ ПОБ ЪБЗТХЦБЕФУС ОЕЛПФПТЩНЙ РТПУФЩНЙ ДБООЩНЙ. ьФП ФТЕВХЕФ ОЕУЛПМШЛЙИ INSERT'ПЧ, ЪБ ЛПФПТЩНЙ УМЕДХЕФ SELECT ДМС РПМХЮЕОЙС ТЕЪХМШФЙТХАЭЕЗП НОПЦЕУФЧБ. юФПВЩ ПВМЕЗЮЙФШ РТПЧЕТЛХ ДПВБЧМЕОЙС Й ЙЪНЕОЕОЙС ДБООЩИ, ФЕУФПЧЩЕ ДБООЩЕ РТЕДУФБЧМЕОЩ Ч ЧЙДЕ ДЧХНЕТОПЗП НБУУЙЧБ ФЙРБ Object, Б НЕФПД executeInsert( ) ЪБФЕН НПЦЕФ ЙУРПМШЪПЧБФШ ЙОЖПТНБГЙА ЙЪ ПДОПК УФТПЛЙ ДМС УПЪДБОЙС УППФЧЕФУФЧХАЭЕК SQL ЛПНБОДЩ.
//: c15:jdbc:LoadDB.java
// Loads and tests the database.
import java.sql.*;
class TestSet {
Object[][] data = {
{ "MEMBERS", new Integer(1),
"dbartlett", "Bartlett", "David",
"123 Mockingbird Lane",
"Gettysburg", "PA", "19312",
"123.456.7890", "bart@you.net" },
{ "MEMBERS", new Integer(2),
"beckel", "Eckel", "Bruce",
"123 Over Rainbow Lane",
"Crested Butte", "CO", "81224",
"123.456.7890", "beckel@you.net" },
{ "MEMBERS", new Integer(3),
"rcastaneda", "Castaneda", "Robert",
"123 Downunder Lane",
"Sydney", "NSW", "12345",
"123.456.7890", "rcastaneda@you.net" },
{ "LOCATIONS", new Integer(1),
"Center for Arts",
"Betty Wright", "123 Elk Ave.",
"Crested Butte", "CO", "81224",
"123.456.7890",
"Go this way then that." },
{ "LOCATIONS", new Integer(2),
"Witts End Conference Center",
"John Wittig", "123 Music Drive",
"Zoneville", "PA", "19123",
"123.456.7890",
"Go that way then this." },
{ "EVENTS", new Integer(1),
"Project Management Myths",
"Software Development",
new Integer(1), new Float(2.50),
"2000-07-17 19:30:00" },
{ "EVENTS", new Integer(2),
"Life of the Crested Dog",
"Archeology",
new Integer(2), new Float(0.00),
"2000-07-19 19:00:00" },
// уПРПУФБЧМЕОЙЕ МАДЕК Й УПВЩФЙК
{ "EVTMEMS",
new Integer(1), // Dave is going to
new Integer(1), // the Software event.
new Integer(0) },
{ "EVTMEMS",
new Integer(2), // Bruce is going to
new Integer(2), // the Archeology event.
new Integer(0) },
{ "EVTMEMS",
new Integer(3), // Robert is going to
new Integer(1), // the Software event.
new Integer(1) },
{ "EVTMEMS",
new Integer(3), // ... and
new Integer(2), // the Archeology event.
new Integer(1) },
};
// Use the default data set:
public TestSet() {}
// Use a different data set:
public TestSet(Object[][] dat) { data = dat; }
}
public class LoadDB {
Statement statement;
Connection connection;
TestSet tset;
public LoadDB(TestSet t) throws SQLException {
tset = t;
try {
// Load the driver (registers itself)
Class.forName(CIDConnect.dbDriver);
} catch(java.lang.ClassNotFoundException e) {
e.printStackTrace(System.err);
}
connection = DriverManager.getConnection(
CIDConnect.dbURL, CIDConnect.user,
CIDConnect.password);
statement = connection.createStatement();
}
public void cleanup() throws SQLException {
statement.close();
connection.close();
}
public void executeInsert(Object[] data) {
String sql = "insert into "
+ data[0] + " values(";
for(int i = 1; i < data.length; i++) {
if(data[i] instanceof String)
sql += "'" + data[i] + "'";
else
sql += data[i];
if(i < data.length - 1)
sql += ", ";
}
sql += ')';
System.out.println(sql);
try {
statement.executeUpdate(sql);
} catch(SQLException sqlEx) {
System.err.println("Insert failed.");
while (sqlEx != null) {
System.err.println(sqlEx.toString());
sqlEx = sqlEx.getNextException();
}
}
}
public void load() {
for(int i = 0; i< tset.data.length; i++)
executeInsert(tset.data[i]);
}
// чЩВТБУЩЧБЕН ЙУЛМАЮЕОЙЕ ОБ ЛПОУПМШ:
public static void main(String[] args)
throws SQLException {
LoadDB db = new LoadDB(new TestSet());
db.load();
try {
// рПМХЮБЕН ResultSet ЙЪ ЪБЗТХЦЕООПК ВБЪЩ ДБООЩИ:
ResultSet rs = db.statement.executeQuery(
"select " +
"e.EVT_TITLE, m.MEM_LNAME, m.MEM_FNAME "+
"from EVENTS e, MEMBERS m, EVTMEMS em " +
"where em.EVT_ID = 2 " +
"and e.EVT_ID = em.EVT_ID " +
"and m.MEM_ID = em.MEM_ID");
while (rs.next())
System.out.println(
rs.getString(1) + " " +
rs.getString(2) + ", " +
rs.getString(3));
} finally {
db.cleanup();
}
}
} ///:~
лМБУУ TestSet УПДЕТЦЙФ НОПЦЕУФЧП ДБООЩИ РП ХНПМЮБОЙА, ЛПФПТПЕ РТПЙЪЧПДЙФУС, ЕУМЙ ЧЩ ЙУРПМШЪХЕФЕ ЛПОУФТХЛФПТ РП ХНПМЮБОЙА. пДОБЛП ЧЩ НПЦЕФЕ УПЪДБФШ ПВЯЕЛФ TestSet, ЙУРПМШЪХС БМШФЕТОБФЙЧОЩК ОБВПТ ДБООЩИ УП ЧФПТЩН ЛПОУФТХЛФПТПНo. оБВПТ ДБООЩИ ИТБОЙФУС Ч ДЧХНЕТОПН НБУУЙЧЕ ФЙРБ Object, РПУЛПМШЛХ ПО НПЦЕФ ВЩФШ МАВПЗП ФЙРБ, ЧЛМАЮБС String ЙМЙ ЮЙУМПЧЩЕ ФЙРЩ. нЕФПД executeInsert( ) ЙУРПМШЪХЕФ RTTI ФПЗП, ЮФПВЩ ТБЪМЙЮБФШ ДБООЩЕ ФЙРБ String (ЛПФПТЩЕ ДПМЦОЩ ВЩФШ Ч ЛБЧЩЮЛБИ) Й ДБООЩЕ ОЕ ФЙРБ String, ФБЛ ЛБЛ SQL ЛПНБОДБ УФТПЙФУС ЙЪ ДБООЩИ. рПУМЕ РЕЮБФЙ ЬФПК ЛПНБОДЩ ОБ ЛПОУПМШ ЙУРПМШЪХЕФУС executeUpdate( ) ДМС ПФУЩМЛЙ ЕЕ Ч ВБЪХ ДБООЩИ.
лПОУФТХЛФПТ ДМС LoadDB УПЪДБЕФ УПЕДЙОЕОЙЕ Й РПЫБЗПЧП У РПНПЭША load( ) РТПИПДЙФ РП ДБООЩН Й ЧЩЪЩЧБЕФ executeInsert( ) ДМС ЛБЦДПК ЪБРЙУЙ. cleanup( ) ЪБЛТЩЧБЕФ ЙОУФТХЛГЙА Й УПЕДЙОЕОЙЕ. юФПВЩ ЗБТБОФЙТПЧБФШ ЬФПФ ЧЩЪПЧ, ПО РПНЕЭЕО Ч РТЕДМПЦЕОЙЕ finally.
лБЛ ФПМШЛП ВБЪБ ДБООЩИ ВХДЕФ ЪБЗТХЦЕОБ, ЙОУФТХЛГЙС executeQuery( ) РТПЙЪЧПДЙФ РТПУФПЕ ТЕЪХМШФЙТХАЭЕЕ НОПЦЕУФЧП. фБЛ ЛБЛ ЪБРТПУ ЛПНВЙОЙТХЕФ ОЕУЛПМШЛП ФБВМЙГ, ПО СЧМСЕФУС РТЙНЕТПН ПВЯЕДЙОЕОЙС.
вПМЕЕ РПДТПВОП П JDBC НПЦОП ХЪОБФШ Ч ЬМЕЛФТПООПК ДПЛХНЕОФБГЙЙ, ЛПФПТБС ТБУРТПУФТБОСЕФУС ЛБЛ ЮБУФШ РБЛЕФБ Java ПФ Sun. лТПНЕ ФПЗП, ЧЩ НПЦЕФЕ ОБКФЙ ДПРПМОЙФЕМШОХА ЙОЖПТНБГЙА Ч ЛОЙЗЕ JDBC Database Access with Java (Hamilton, Cattel, and Fisher, Addison-Wesley, 1997). дТХЗЙЕ ЛОЙЗЙ, РПУЧСЭЕООЩЕ JDBC, РПСЧМСАФУС ТЕЗХМСТОП.
дПУФХР ЛМЙЕОФПЧ ЙЪ йОФЕТОЕФБ ЙМЙ ЛПТРПТБФЙЧОПК УЕФЙ ВЕУУРПТОП СЧМСЕФУС ОБЙВПМЕЕ РТПУФЩН УРПУПВПН ДПУФХРБ НОПЗЙИ РПМШЪПЧБФЕМЕК Л ДБООЩН Й ТЕУХТУБН [74]. ьФПФ ФЙР ДПУФХРБ ПУОПЧЩЧБЕФУС ОБ ЛМЙЕОФБИ, ЙУРПМШЪХАЭЙИ УФБОДБТФ World Wide Web ЙМЙ Hypertext Markup Language (HTML) Й Hypertext Transfer Protocol (HTTP). Servlet API ХУФБОБЧМЙЧБЕФ ПВЭХА УФТХЛФХТХ ТЕЫЕОЙС ДМС ХДПЧМЕФЧПТЕОЙС ЪБРТПУБН HTTP.
фТБДЙГЙПООЩН УРПУПВПН ТЕЫЕОЙС ФБЛПК РТПВМЕНЩ, ЛБЛ ЙЪНЕОЕОЙЕ йОФЕТОЕФ-ЛМЙЕОФПН ВБЪЩ ДБООЩИ, ВЩМП УПЪДБОЙЕ HTML УФТБОЙГЩ У ФЕЛУФПЧЩНЙ РПМСНЙ Й ЛОПРЛПК “submit”. рПМШЪПЧБФЕМШ ЧРЕЮБФЩЧБМ УППФЧЕФУФЧХАЭХА ЙОЖТНБГЙА Й ФЕЛУФПЧЩИ РПМСИ Й ОБЦЙНБМ ЛОПРЛХ “submit”. дБООЩЕ ПФРТБЧМСАФУС ОБ URL, ЛПФПТЩК ЗПЧПТЙФ УЕТЧЕТХ ЮФП У ОЙНЙ ДЕМБФШ, ХЛБЪЩЧБС НЕУФПРПМПЦЕОЙЕ Common Gateway Interface (CGI) РТПЗТБННЩ, ЛПФПТХА ЪБРХУЛБЕФ УЕТЧЕТ, ПВЕУРЕЮЙЧБС РТПЗТБННХ ДБООЩНЙ РТЙ ЧЩЪПЧЕ. CGI РТПЗТБННЩ ПВЩЮОП РЙЫХФУС ОБ Perl, Python, C, C++ ЙМЙ МАВПН ДТХЗПН СЪЩЛЕ, ЛПФПТЩК НПЦЕФ ЮЙФБФШ УП УФБОДБТФОПЗП ЧЧПДБ Й РЙУБФШ Ч УФБОДБТФОЩК ЧЩЧПД. фБЛЙН ПВТБЪПН, ЧУЕ, ЮФП ДЕМБЕФ Web УЕТЧЕТ, ЬФП ЪБРХУЛ CGI РТПЗТБННЩ, Б ДМС ЧЧПДБ Й ЧЩЧПДБ ЙУРПМШЪХАФУС УФБОДБТФОЩЕ РПФПЛЙ (ЙМЙ, ЙОПЗДБ ДМС ЧЧПДБ ЙУРПМШЪХАФУС РЕТЕНЕООЩЕ ПЛТХЦЕОЙС). ъБ ЧУЕ ПУФБМШОПЕ ПФЧЕЮБЕФ CGI РТПЗТБННБ. уОБЮБМБ ПОБ РТПЧЕТСЕФ ДБООЩЕ Й ТЕЫБЕФ ЛПТТЕЛФОЩК МЙ Х ОЙИ ЖПТНБФ. еУМЙ ЬФП ОЕ ФБЛ, CGI РТПЗТБННБ ДПМЦОБ УПЪДБФШ HTML, ЮФПВЩ ХЛБЪБФШ ОБ РТПВМЕНХ; ЬФБ УФТБОЙГБ РПУЩМБЕФУС Web УЕТЧЕТХ (ЮЕТЕЪ УФБОДБТФОЩК ЧЩЧПД ЙЪ CGI РТПЗТБННЩ), лПФПТЩК ПФУЩМБЕФ ЕЕ РПМШЪПЧБФЕМА. рПМШЪПЧБФЕМШ ДПМЦЕО ЧЕТОХФШУС Л РТЕДЩДХЭЕК УФТБОЙГЕ Й РПРТПВПЧБФШ ЧОПЧШ. еУМЙ ДБООЩЕ ЛПТТЕЛФОЩ, CGI РТПЗТБННБ ПВТБВБФЩЧБЕФ ДБООЩЕ УППФЧЕФУФЧХАЭЙН УРПУПВПН Й, ЧПЪНПЦОП, ЧУФБЧМСЕФ ЙИ Ч ВБЪХ ДБООЩИ. ъБФЕН ПОБ ДПМЦОБ УПЪДБФШ УППФЧЕФУФЧХАЭХА HTML УФТБОЙГХ ДМС Web УЕТЧЕТБ, ЛПФПТБС ВХДЕФ ЧПЪЧТБЭЕОБ РПМШЪПЧБФЕМА.
ьФП ВЩМП ВЩ ЙДЕБМШОП ДМС РЕТЕИПДБ БО РПМОПУФША Java-ПТЙЕОФЙТПЧБООПЕ ТЕЫЕОЙЕ ФБЛПК РТПВМЕНЩ — БРРМЕФ ОБ УФПТПОЕ ЛМЙЕОФБ РТПЧЕТСЕФ Й ПФУЩМБЕФ ДБООЩЕ, Б УЕТЧМЕФ ОБ УФПТПОЕ УЕТЧЕТБ РПМХЮБЕФ Й ПВТБВБФЩЧБЕФ ЙИ. л УПЦБМЕОЙА, ИПФС БРРМЕФЩ Й РПДДЕТЦЙЧБАФ ФЕИОПМПЗЙА У ДПУФБФПЮОПК РПДДЕТЦЛПК, ЙИ РТПВМЕНБФЙЮОП ЙУРПМШЪПЧБФШ Ч Web, РПУЛПМШЛХ ЧЩ ОЕ НПЦЕФЕ ТБУУЮЙФЩЧБФШ, ЮФП ПРТЕДЕМЕООБС ЧЕТУЙС Java, РПДДЕТЦЙЧБЕФУС ОБ ЛМЙЕОФУЛПН Web ВТПХЪЕТЕ. жБЛФЙЮЕУЛЙ, ЧЩ ОЕ НПЦЕФЕ РПМБЗБФШУС, ЮФП Web ВТПХЪЕТ ЧППВЭЕ РПДДЕТЦЙЧБЕФ Java! ч йОФТБОЕФ ЧЩ НПЦЕФЕ ФТЕВПЧБФШ ПРТЕДЕМЕООЩК ХТПЧЕОШ РПДДЕТЦЛЙ, ЛПФПТЩК РПЪЧПМЙФ УПЪДБФШ ЗПТБЪДП ВПМШЫХА ЗЙВЛПУФШ Ч ФПН, ЮФП ЧЩ ДЕМБЕФЕ, ОП ДМС Web ОБЙВПМЕЕ ВЕЪПРБУОЩН РПДИПДПН СЧМСЕФУС ЧЩРПМОЕОЙЕ ЧУЕК ПВТБВПФЛЙ ОБ УФПТПОЕ УЕТЧЕТБ Й ЧПЪЧТБЭЕОЙЕ ЛМЙЕОФХ РТПУПЗП HTML ЛПДБ. рТЙ ЬФПН РПДИПДЕ ОЙЛБЛПК РПМШЪПЧБФЕМШ ОЕ ВХДЕФ ПФЧЕТЗОХФ ЙЪ-ЪБ ФПЗП, ЮФП Х ОЕЗП ОЕФ РТБЧЙМШОП ХУФБОПЧМЕООПЗП РТПЗТБННОПЗП ПВЕУРЕЮЕОЙС.
рПУЛПМШЛХ УЕТЧМЕФЩ ПВЕУРЕЮЙЧБАФ ЧЕМЙЛПМЕРОПЕ ТЕЫЕОЙЕ ДМС РТПЗТБННЙТПЧБОЙС ОБ УФПТПОЕ УЕТЧЕТБ, ПОЙ СЧМСАФУС ОБЙВПМЕЕ РПРХМСТОЩН ПВЯСУОЕОЙЕН РЕТЕИПДБ ОБ Java. оЕ ФПМШЛП РПФПНХ, ЮФП ПОЙ ПВЕУРЕЮЙЧБАФ ТБВПЮЕЕ РТПУФТБОУФЧП, ЪБНЕОСАЭЕЕ CGI РТПЗТБННЙТПЧБОЙЕ (Й УОЙЦБАФ ЛПМЙЮЕУФЧП УМПЦОЩИ CGI РТПВМЕН), ОП Й ЧЕУШ ЧБЫ ЛПД УФБОПЧЙФУС РЕТЕОПУЙНЩН НЕЦДХ РМБФЖПТНБНЙ РТЙ ЙУРПМШЪПЧБОЙЙ Java, Б ЧЩ РПМХЮБЕФЕ ДПУФХР ЛП ЧУЕНХ Java API (ЙУЛМАЮБС, ЛПОЕЮОП, ФП, ЛПФПТПЕ РПЙЪЧПДЙФ GUI, ОБРТЙНЕТ Swing).
бТИЙФЕЛФХТБ API УЕТЧМЕФПЧ УПУФПЙФ Ч ФПН, ЮФП ЛМБУУЙЮЕУЛЙК УЕТЧЙУ ПВЕУРЕЮЙЧБЕФУС НЕФПДПН service( ), ЮЕТЕЪ ЛПФПТЩК УЕТЧМЕФХ РПУЩМБАФУС ЧУЕ ЛМЙЕОФУЛЙЕ ЪБРТПУЩ, Й НЕФПДБНЙ ЦЙЪОЕООПЗП ГЙЛМБ init( ) Й destroy( ), ЛПФПТЩЕ ЧЩЪЩЧБАФУС ФПМШЛП РТЙ ЪБЗТХЪЛЕ Й ЧЩЗТХЪЛЕ УЕТЧМЕФБ (ЬФП ЙУЛМАЮЙФЕМШОЩЕ УФХБГЙЙ).
public interface Servlet {
public void init(ServletConfig config)
throws ServletException;
public ServletConfig getServletConfig();
public void service(ServletRequest req,
ServletResponse res)
throws ServletException, IOException;
public String getServletInfo();
public void destroy();
}
йЪАНЙОЛБ getServletConfig( ) УПУФПЙФ Ч ФПН, ЮФП ПО ЧПЪЧТБЭБЕФ ПВЯЕЛФ ServletConfig, ЛПФПТЩК УПДЕТЦЙФ РБТБНЕФТЩ ЙОЙГЙБМЙЪБГЙЙ Й ЪБРХУЛБ ДМС ЬФПЗП УЕТЧМЕФБ. getServletInfo( ) ЧПЪЧТБЭБЕФ УФТПЛХ, УПДЕТЦБЭХА ЙОЖПТНБГЙА П УЕТЧМЕФЕ, ФБЛХА, ЛБЛ ЙНС БЧФПТБ, ЧЕТУЙА Й БЧФПТУЛПЕ РТБЧП.
лМБУУ GenericServlet СЧМСЕФУС ТЕБМЙЪБГЙЕК ПВПМПЮЛЙ ЬФПЗП ЙОФЕТЖЕКУБ Й ПВЩЮОП ОЕ ЙУРПМШЪХЕФУС. лМБУУ HttpServlet СЧМСЕФУС ТБУЫЙТЕОЙЕН GenericServlet Й РТЕДОБЪОБЮЕО УРЕГЙБМШОП ДМС ПВТБВПФЛЙ РТПФПЛПМБ HTTP — HttpServlet ПДЙО ЙЪ ФЕИ ЛМБУУПЧ, ЛПФПТЩЕ ЧЩ ВХДЕФЕ ЙУРПМШЪПЧБФШ ЮБЭЕ ЧУЕЗП.
оБЙВПМЕЕ ХДПВОЩН ЙОУФТХНЕОФПН УЕТЧМЕФОПЗП API СЧМСЕФУС ЧОЕЫОЙЕ ПВЯЕЛФЩ, ЛПФПТЩЕ ЙДХФ ЧНЕУФЕ У ЛМБУУПН HttpServlet ДМС ЕЗП РПДДЕТЦЛЙ. еУМЙ ЧЩ ЧЪЗМСОЕФЕ ОБ НЕФПД service( ) ЙЪ ЙОФЕТЖЕКУБ Servlet, ЧЩ ХЧЙДЙФЕ, ЮФП ПО ЙНЕЕФ ДЧБ РБТБНЕФТБ: ServletRequest Й ServletResponse. х ЛМБУУБ HttpServlet ЬФЙ ДЧБ ПВЯЕЛФБ ТБУЫЙТСАФУС ОБ HTTP: HttpServletRequest Й HttpServletResponse. чПФ РТПУФПК РТЙНЕТ, ЛПФПТЩК РПЛБЪЩЧБЕФ ЙУРПМШЪПЧБОЙЕ HttpServletResponse:
//: c15:servlets:ServletsRule.java
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
public class ServletsRule extends HttpServlet {
int i = 0; // Servlet "persistence"
public void service(HttpServletRequest req,
HttpServletResponse res) throws IOException {
res.setContentType("text/html");
PrintWriter out = res.getWriter();
out.print("<HEAD><TITLE>");
out.print("A server-side strategy");
out.print("</TITLE></HEAD><BODY>");
out.print("<h1>Servlets Rule! " + i++);
out.print("</h1></BODY>");
out.close();
}
} ///:~
ServletsRule ОБУФПМШЛП РТПУФ, ОБУЛПМШЛП НПЦЕФ ВЩФШ РТПУФ УЕТЧМЕФ. уЕТЧМЕФ ЙОЙГЙБМЙЪЙХЕФУС ФПМШЛП ПДОБЦДЩ РХФЕН ЧЩЪПЧБ УЧПЕЗП НЕФПДБ init( ) РТЙ ЪБЗТХЪЛЕ УЕТЧМЕФБ РПУМЕ ФПЗП, ЛБЛ УОБЮБМБ ЪБЗТХЪЙФШУС ЛПОФЕКОЕТ УЕТЧМЕФПЧ. лПЗДБ ЛМЙЕОФ ДЕМБЕФ ЪБРТПУ Л URL, УППФЧЕФУФЧХАЭЙК РТЕДУФБЧМЕООПНХ УЕТЧМЕФХ, ЛПОФЕКОЕТ УЕТЧМЕФПЧ РЕТЕИЧБФЩЧБЕФ ЬФПФ ЪБРТПУ Й ДЕМБЕФ ЧЩЪПЧ НЕФПДБ service( ), ЪБФЕН ХУФБОБЧМЙЧБЕФ ПВЯЕЛФЩ HttpServletRequest Й HttpServletResponse.
зМБЧОБС ЪБВПФБ НЕФПДБ service( ) УПУФПЙФ ЧП ЧЪБЙНПДЕКУФЧЙЙ У HTTP ЪБРТПУПН, РПУМБООЩН ЛМЙЕОФПН, Й РПУФТПЕОЙЕ HTTP ПФЧЕФБ, ПУОПЧЩЧБСУШ ОБ БФФТЙВХФБИ, УПДЕТЦБЭЙИУС Ч ЪБРТПУЕ. ServletsRule НБОЙРХМЙТХЕФ ПВЯЕЛФПН ПФЧЕФБ ОЕ ЪБЧЙУЙНПФ ПФ ФПЗП, ЮФП НПЗ РПУМБФШ ЛМЙЕОФ.
рПУМЕ ХУФБОПЧЛЙ ФЙРБ УПДЕТЦЙНПЗП ПФЧЕФБ (ЮФП ЧУЕЗДБ ДПМЦОП ВЩФШ УДЕМБОП РЕТЕД УПЪДБОЙЕН Writer ЙМЙ OutputStream), НЕФПД getWriter( ) ПВЯЕЛФБ ПФЧЕФБ РТПЙЪЧПДЙФ ПВЯЕЛФ PrintWriter, ЛПФПТЩК ЙУРПМШЪХЕФУС ДМС ОБРЙУБОЙС УЙНЧПМШОПЗП ПФЧЕФБ (ДТХЗПК РПДИПД: getOutputStream( ) РТПЙЪЧПДЙФ OutputStream, ЙУРПМШЪХЕНЩ ДМС ВЙОБТОПЗП ПФЧЕФБ, ЛПФПТЩК РПИПДЙФ ФПМШЛП ДМС УРЕГЙБМШОЩИ ТЕЫЕОЙК).
пУФБЧЫБСУС ЮБУФШ РТПЗТБННЩ РТПУФП РПУЩМБЕФ ЛМЙЕОФХ HTML (ФХФ РТЕДРПМБЗБЕФУС, ЮФП ЧЩ РПОЙНБЕФЕ HTML, ФБЛ ЮФП ЬФБ ЮБУФШ ОЕ ПВЯСУОСЕФУС) Ч ЧЙДЕ РПУМЕДПЧБФЕМОПУФЙ String. пДОБЛП, ПВТБФЙФЕ ЧОЙНБОЙЕ ОБ ЧЛМАЮЕОЙЕ “УЮЕФЮЙЛБ РПУЕЭЕОЙК”, РТЕДУФБЧМЕООПЗП РЕТЕНЕООПК i. ъДЕУШ ЧЩРПМОСЕФУС БЧФПНБФЙЮЕУЛБС ЛПОЧЕТФБГЙС Ч String Ч ЙОУФТХЛГЙЙ print( ).
лПЗДБ ЧЩ ЪБРХУФЙФЕ РТПЗТБННХ, ЧЩ ХЧЙДЙФЕ, ЮФП ЪОБЮЕОЙЕ i УПИТБОСЕФУС НЕЦДХ ЪБРТПУБНЙ Л УЕТЧМЕФХ. ьФП ЧБЦОПЕ УЧПКУФЧП УЕТЧМЕФПЧ: ФБЛ ЛБЛ ФПМШЛП ПДЙО УЕТЧМЕФ ПРТЕДЕМЕООПЗП ЛМБУУБ ЪБЗТХЦБЕФУС Ч ЛПОФЕКОЕТ, Й ПО ОЙЛПЗДБ ОЕ ЧЩЗТХЦБЕФУС (ФПМШЛП Ч УМХЮБЕ, ЕУМЙ ЛПОФЕКОЕТ УЕТЧМЕФПЧ ЪБЧЕТЫБЕФ ТБВПФХ, ЮФП ПВЩЮОП УМХЮБЕФУС, ЕУМЙ ЧЩ РЕТЕЪБЗТХЦБЕФЕ НБЫЙОХ), МАВЩЕ РПМС УЕТЧМЕФБ ЬФПЗП ЛМБУУБ ЪБЗТХЦБАФУС Ч ЛПОФЕКОЕТ Й УФБОПЧСФУС ХУФПКЮЙЧЩНЙ ПВЯЕЛФБНЙ! ьФП ПЪОБЮБЕФ, ЮФП ЧЩ НПЦЕФЕ ВЕЪ ПУПВПЗП ФТХДБ УПИТБОСФШ ЪОБЮЕОЙС НЕЦДХ ЪБРТПУБНЙ Л УЕТЧМЕФХ, Б РТЙ ЙУРПМШЪПЧБОЙЙ CGI ЧЩ ДПМЦОЩ ЪБРЙУЩЧБФШ ЪОБЮЕОЙС ОБ ДЙУЛ, ЮФПВЩ УПИТБОЙФШ ЕЗП, ЮФП ФТЕВХЕФ ОЕЛПФПТПЕ ЛПМЙЮЕУФЧП ЙУЛХУУФЧЕООПУФЙ, Б Ч ТЕЪХМШФБФЕ РПМХЮБЕН ЕО ЛТПУУ-РМБФЖПТНЕООПЕ ТЕЫЕОЙЕ.
лПОЕЮОП ЙОПЗДБ Web УЕТЧЕТ Й, УППФЧЕФУФЧЕООП, ЛПОФЕКОЕТ УЕТЧМЕФПЧ ДПМЦЕО ВЩФШ РЕТЕЗТХЦЕО ЛБЛ ЮБУФШ РТПГЕУУБ РПДДЕТЦЛЙ ЙМЙ ЙЪ-ЪБ РТПВМЕН У РЙФБОЙЕН. дМС РТЕДПФЧТБЭЕОЙС РПФЕТЙ МАВПК РТЙУФХФУФЧХАЭЕК ЙОЖПТНБГЙЙ БЧФПНБФЙЮЕУЛЙ ЧЩЪЩЧБАФУС НЕФПДЩ УЕТЧМЕФБ init( ) Й destroy( ) РТЙ МАВПК ЪБЗТХЪЛЕ ЙМЙ ЧЩЗТХЪЛЕ УЕТЧМЕФБ, ЮФП ДБЕФ ЧБН ЧПЪНПЦОПУФШ УПИТБОЙФШ ДБООЩЕ РТЙ ЧЩЛМАЮЕОЙЙ Й ЧПУУФБОПЧЙФШ ЙИ РПУМЕ РЕТЕЪБЗТХЪЛЙ. лПОФЕКОЕТ УЕТЧМЕФПЧ ЧЩЪЩЧБЕФ НЕФПД destroy( ), ЛБЛ ФПМШЛП ПО РТЕЛТБЭБЕФ ТБВПФХ, ФБЛ ЮФП ЧЩ ЧУЕЗДБ ЙНЕЕФЕ ХДПВОЩК УМХЮБК УПИТБОЙФШ ЧБЦОЩЕ ДБООЩЕ.
еУФШ ЕЭЕ ПДОБ РТПВМЕНБ РТЙ ЙУРПМШЪПЧБОЙЙ HttpServlet. ьФПФ ЛМБУУ ЙНЕЕФ НЕФПДЩ doGet( ) Й doPost( ), ЛПФПТЩЕ ПФМЙЮБАФУС ПФ НЕФПДБ “GET” CGI РПМХЮЕОЙС ПФ ЛМЙЕОФБ, Й НЕФПДБ CGI “POST”. GET Й POST ПФМЙЮБАФУС ФПМШЛП Ч ДЕФБМСИ УРПУПВБНЙ, ЛПФПТЩНЙ ПОЙ РЕТЕДБАФ ДБООЩЕ, ЮФП МЙЮОП С РТЕДРПЮЙФБА ЙЗОПТЙТПЧБФШ. пДОБЛП ЮБЭЕ ЧУЕЗП РХВМЙЛХЕФУС ЙОЖПТНБГЙС, ЙЪ ФПЗП, ЮФП ЧЙДЕМ С, ЛПФПТБС ПДПВТСЕФ УПЪДБОЙЕ ПФДЕМШОЩИ НЕФПДПЧ doGet( ) Й doPost( ) ЧНЕУФП ЕДЙОПЗП ПВЭЕЗП НЕФПДБ service( ), ЛПФПТЩК ПВТБВБФЩЧБЕФ ПВБ УМХЮБС. ьФП РТЕДРПЮФЕОЙЕ ЛБЦЕФУС ДПУФБФПЮОП ПВЭЙН, ОП С ОЙЛПЗДБ ОЕ ЧЙДЕМ ПВЯСУОЕОЙС, ЛПФПТПЕ ЪБУФБЧЙМП ВЩ НЕОС РПЧЕТЙФШ, ЮФП ЬФП ОЕ РТПУФП ЙОФЕТФОПУФШ НЩЫМЕОЙС CGI РТПЗТБННЙУФПЧ, ЛПФПТЩЕ РТЙЧЩЛМЙ ПВТБЭБФШ ЧОЙНБОЙЕ, ЙУРПМШЪХЕФУС МЙ GET ЙМЙ POST. фБЛ ЮФП Ч ДХИЕ “ХРТПЭЕОЙС ЧУЕЗП ОБУЛПМШЛП ЬФП ЧПЪНПЦОП”[75], С ВХДХ ЙУРПМШЪПЧБФШ НЕФПД service( ) Ч ЬФЙИ РТЙНЕТБИ, Й РХУФШ ПО УБН ЪБВПФЙФШУС П GET'БИ Й POST'БИ. пДОБЛП ДЕТЦЙФЕ Ч ХНЕ, ЮФП С ЮФП-ФП ХРХУФЙМ, ЮФП, ЧПЪНПЦОП, СЧМСЕФУС ИПТПЫЕК РТЙЮЙОПК Ч РПМШИХ ЙУРПМШЪПЧБОЙС doGet( ) Й doPost( ).
ч МАВПЕ ЧТЕНС, ЛПЗДБ ЖПТНБ РЕТЕДБЕФУС УЕТЧМЕФХ, HttpServletRequest РТЕДЧБТЙФЕМШОП ЪБЗТХЦБЕФ ЧУЕ ДБООЩЕ ЖПТНЩ, ИТБОСЭЙЕУС Ч ЧЙДЕ РБТ ЛМАЮ-ЪОБЮЕОЙЕ. еУМЙ ЧЩ ЪОБЕФЕ ЙНЕОБ РПМЕК, ЧЩ НПЦЕФЕ РТПУФП ЙУРПМШЪПЧБФШ ЙИ ОБРТСНХА У РПНПЭША НЕФПДБ getParameter( ) ДМС РПМХЮЕОЙС ЪОБЮЕОЙС. чЩ ФБЛЦЕ НПЦЕФЕ РПМХЮЙФШ Enumeration (УФБТБС ЖПТНБ Iterator) ОБ ЙНЕОБ РПМЕК, ЛБЛ РПЛБЪБОП Ч УМЕДХАЭЕН РТЙНЕТЕ. ьФПФ РТЙНЕТ ФБЛЦЕ ДЕНПОУФТЙТХЕФ ЛБЛ ПДЙО УЕТЧМЕФ НПЦЕФ ВЩФШ ЙУРПМШЪПЧБО ДМС ЗЕОЕТБГЙЙ УФТБОЙГЩ, ЛПФПТБС УПДЕТЦЙФ ЖПТНХ, Й ДМС ПФЧЕФБ ОБ УФТБОЙГХ (ВПМЕЕ ХДПВОПЕ ТЕЫЕОЙЕ ВХДЕФ РПЛБЪБОП РПЪЦЕ, РТЙ ТБУУНПФТЕОЙЙ JSP). еУМЙ Enumeration РХУФПЕ, ЪОБЮЙФ РПМЕК ОЕФ. ьФП ЪОБЮЙФ, ЮФП ОЙЛБЛПК ЖПТНЩ ОЕ ВЩМП РЕТЕДБОП. ч ЬФПН УМХЮБЕ УПДБЕФУС ЖПТНБ, Б ЛОПРЛБ РПУЩМЛЙ РПЧФПТОП ЧЩЪЩЧБЕФ ЬФПФ ЦЕ УЕТЧМЕФ. еУМЙ ЦЕ РПМС УХЭЕУФЧХАФ, ПОЙ РПЛБЪЩЧБАФУС.
//: c15:servlets:EchoForm.java
// дБНР РБТ ЙНЕО-ЪОБЮЕОЙК ЙЪ МАВПК ЖПТНЩ HTML
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
public class EchoForm extends HttpServlet {
public void service(HttpServletRequest req,
HttpServletResponse res) throws IOException {
res.setContentType("text/html");
PrintWriter out = res.getWriter();
Enumeration flds = req.getParameterNames();
if(!flds.hasMoreElements()) {
// жПТНБ ОЕ РЕТЕДБЧБМБУШ - УПЪДБОЙЕ ЖПТНЩ:
out.print("<html>");
out.print("<form method=\"POST\"" +
" action=\"EchoForm\">");
for(int i = 0; i < 10; i++)
out.print("<b>Field" + i + "</b> " +
"<input type=\"text\""+
" size=\"20\" name=\"Field" + i +
"\" value=\"Value" + i + "\"><br>");
out.print("<INPUT TYPE=submit name=submit"+
" Value=\"Submit\"></form></html>");
} else {
out.print("<h1>Your form contained:</h1>");
while(flds.hasMoreElements()) {
String field= (String)flds.nextElement();
String value= req.getParameter(field);
out.print(field + " = " + value+ "<br>");
}
}
out.close();
}
} ///:~
ъДЕУШ ЧЙДЕО ПДЙО ЙЪ ОЕДПУФБФЛПЧ, ЪБЛМАЮБАЭЙКУС Ч ФПН, ЮФП Java ОЕ ЛБЦЕФШУС РТЕДОБЪОБЮЕООПК ДМС ПВТБВПФЛЙ УФТПЛ Ч ХНЕ — ЖПТНБФЙТПЧБОЙЕ ЧПЪЧТБЭБЕНПК УФТБОЙГЩ ДПУФБФПЮОП ОЕРТЙСФОП ЙЪ-ЪБ РЕТЕЧПДПЧ УФТПЛЙ, ЧЩДЕМЕОЙЕ ЪОБЛПЧ ЛБЧЩЮЛЙ Й УЙНЧПМПЧ “+”, ОЕПВИПДЙНЩИ ДМС РПУФТПЕОЙС ПВЯЕЛФБ String. у ВПМШЫЙНЙ HTML УФТБОЙГБНЙ УФБОПЧЙФУС ОЕТБЪХНОП ЧОПУЙФШ ЬФПФ ЛПД РТСНП Ч Java. пДП ЙЪ ТЕЫЕОЙК - ДЕТЦБФШ УФТБОЙГХ Ч ЧЙДЕ ПФДЕМШОПЗП ФЕЛУФПЧПЗП ЖБКМБ, ЪБФЕН ПФЛТЩЧБФШ Й ПВТБВБФЩЧБФШ ЕЗП ОБ Web УЕТЧЕТЕ. еУМЙ ЧЩ ЧЩРПМОСЕФЕ МАВЩЕ РПДУФБОПЧЛЙ Ч УПДЕТЦЙНПН УФТБОЙГЩ, ЬФП ОЕ МХЮЫЙК РПДИПД, ФБЛ ЛБЛ Java РМПИП ЧЩРПМОСЕФ ПВТБВПФЛХ УФТПЛ. ч ЬФПН УМХЮБЕ ДМС ЧБУ, ЧЕТПСФОП, МХЮЫЕ ВХДЕФ ЙУРПМШЪПЧБФШ ВПМЕЕ РПДИПДСЭЕЕ ТЕЫЕОЙЕ (Python НПЦЕФ ВЩФШ ЧБЫЙН ЧЩВПТПН. еУФШ ЧЕТУЙЙ, ЛПФПТЩЕ ЧУФТБЙЧБАФУС Ч Java, ОБЪЩЧБЕНЩЕ JPython) ДМС ЗЕОЕТБГЙЙ ПФЧЕФОПК УФТБОЙГЩ.
лПОФЕКОЕТ УЕТЧМЕФПЧ ЙНЕЕФ РХМ РТПГЕУУПЧ, ЛПФПТЩЕ УПЪДБАФУС ДМС ПВТБВПФЛЙ ЛМЙЕОФУЛЙИ ЪБРТПУПЧ. ьФП РПИПЦЕ ОБ ФП, ЛПЗДБ ДЧБ ЛМЙЕОФБ, РТЙВЩЧЫЙЕ ПДОПЧТЕНЕООП, ДПМЦОЩ ВЩФШ ПДОПЧТЕНЕООП ПВТБВПФБОЩ НЕФПДПН service( ). рПЬФПНХ НЕФПД service( ) ДПМЦЕО ВЩФШ ОБРЙУБО ВЕЪПРБУОЩН УРПУПВПН УФПЮЛЙ ЪТЕОЙС НОПЦЕУФЧЕООПУФЙ РТПГЕУУПЧ. мАВПК ДПУФХР Л ПВЭЙН ТЕУХТУБН (ЖБКМБН, ВБЪБН ДБООЩИ) ДПМЦЕО ЗБТБОФЙТПЧБООП ЙУРПМШЪПЧБФШ ЛМАЮЕЧПЕ УМПЧП synchronized.
уМЕДХАЭЙК РТЙНЕТ РПНЕЭБЕФ РТЕДМПЦЕОЙЕ synchronized ЧПЛТХЗ НЕФПДБ РТПГЕУУБ sleep( ). ьФП ВМПЛЙТХЕФ ЧУЕ ДТХЗЙЕ НЕФПДЩ ОБ ЪБДБООПЕ ЧТЕНС (РСФШ УЕЛХОДБ), ЛПФПТПЕ ЙУРПМШЪХАФ ЧУЕ. лПЗДБ ВХДЕФЕ РТПЧЕТСФШ, ЧЩ ДПМЦОЩ ЪБРХУФЙФШ ОЕУЛПМШЛП ЬЛЪЕНРМСТПЧ ПЛПО ВТПХЪЕТБ Й ПВТБЭБФШУС Л УЕТЧМЕФХ ФБЛ ЮБУФП, ЛБЛ ЬФП ЧПЪНПЦОП Ч ЛБЦДПН ПЛОЕ — ЧЩ ХЧЙДЙФЕ, ЮФП ЛБЦДПЕ ПЛОП ЦДЕФ, РПЛБ ДП ОЕЗП ДПКДЕФ ИПД.
//: c15:servlets:ThreadServlet.java
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
public class ThreadServlet extends HttpServlet {
int i;
public void service(HttpServletRequest req,
HttpServletResponse res) throws IOException {
res.setContentType("text/html");
PrintWriter out = res.getWriter();
synchronized(this) {
try {
Thread.currentThread().sleep(5000);
} catch(InterruptedException e) {
System.err.println("Interrupted");
}
}
out.print("<h1>Finished " + i++ + "</h1>");
out.close();
}
} ///:~
фБЛЦЕ ЧПЪНПЦОП УЙОИТПОЙЪЙТПЧБФШ ЧЕУШ УЕТЧМЕФ, РПНЕУФЙЧ ЛМАЮЕЧПЕ УМПЧП synchronized РЕТЕД НЕФПДПН service( ). жБЛФЙЮЕУЛЙ, ТБЪХНОП ЙУРПМШЪПЧБФШ ВМПЛ synchronized ЧНЕУФП ЬФПЗП, ЕУМЙ ЕУФШ ЛТЙФЙЮЕУЛБС УЕЛГЙС РТЙ ЧЩРПМОЕОЙЙ, ЛПФПТБС НПЦЕФ ОЕ РПМХЮЙФШ ХРТБЧМЕОЙЕ. ч ЬФПН УМХЮБЕ ЧЩ НПЦЕФЕЙЪВЕЗБФШ УЙОИТПОЙЪБГЙЙ ЧЕТИОЕЗП ХТПЧОС, ЙУРПМШЪХС РТЕДМПЦЕОЙЕ synchronized. ч РТПФЙЧОПН УМХЮБЕ ЧУЕ РТПГЕУУЩ ВХДХФ ПЦЙДБФШ ФБЛ ЙМЙ ЙОБЮЕ, ФБЛ ЮФП ЧЩ НПЦЕФЕ УЙОИТПОЙЪЙТПЧБФШ (synchronize) ЧЕУШ НЕФПД.
HTTP СЧМСЕФУС РТПФПЛПМПН, ОЕ ЙУРПМШЪХАЭЙН УЕУУЙЙ, ФБЛ ЮФП ЧЩ ОЕ НПЦЕФЕ РЕТЕДБФШ ЙОЖПТНБГЙА ЙЪ ПДОПЗП ПВТБЭЕОЙС Л УЕТЧЕТХ Ч ДТХЗПЕ, ЕУМЙ ПДЙО Й ФПФ ЦЕ ЮЕМПЧЕЛ РПУФПСООП ПВТБЭБЕФУС Л ЧБЫЕНХ УБКФХ, ЙМЙ ЕУМЙ ЬФП УПЧУЕН ДТХЗПК ЮЕМПЧЕЛ. иПТПЫЙН ТЕЫЕОЙЕН УФБМП ЧЧЕДЕОЙЕ НЕИБОЙЪНБ, ЛПФПТЩК РПЪЧПМСМ Web ТБЪТБВПФЮЙЛБН ПФУМЕЦЙЧБФШ УЕУУЙЙ. оБРЙНЕТ, ЛПНРБОЙЙ ОЕ НПЗМЙ ЪБОЙНБФШУС ЬМЕЛФТПООПК ЛПННЕТГЙЕК ВЕЪ ПФУМЕЦЙЧБОЙС ЛМЙЕОФПЧ Й РТЕДНЕФПЧ, ЛПФПТЩЕ ПОЙ ЧЩВТБМЙ Ч УЧПА ЛБТЪЙОХ РПЛХРПЛ.
еУФШ ОЕУЛПМШЛП НЕФПДПЧ ПФУМЕЦЙЧБОЙС УЕУУЙК, ОП ОБЙВПМЕЕ ПВЭЙК НЕФПД УЧСЪБО У ОБМЙЮЙЕН “cookies”, ЮФП СЧМСЕФУС ЙОФЕЗТЙТПЧБООПК ЮБУФША УФБОДБТФБ Internet. тБВПЮБС зТХРРБ HTTP ЙЪ Internet Engineering Task Force ЧРЙУБМБ cookies Ч ПЖЙГЙБМШОЩК УФБОДБТФ RFC 2109 (ds.internic.net/rfc/rfc2109.txt ЙМЙ РТПЧЕТШФЕ ОБ www.cookiecentral.com).
Cookie - ЬФП ОЙЮФП ЙОПЕ, ЛБЛ НБМЕОШЛЙК ЛХУПЮЕЛ ЙОЖПТНБГЙЙ, РПУЩМБЕНЩК Web УЕТЧЕТПН ВТПХЪЕТХ. вТПХЪЕТ ИТБОЙФ cookie ОБ МПЛБМШОПН ДЙУЛЕ, Й ЛПЗДБ ЧЩРПМОСЕФУС ДТХЗПК ЧЩЪПЧ ОБ URL, У ЛПФПТЩН УЧСЪБОП cookie, cookie УРПЛПКОП ПФУЩМБЕФУС ЧНЕУФЕ У ЧЩЪПЧПН, ФЕН УБНЩН УЕТЧЕТ ПВЕУРЕЮЙЧБЕФУС ОЕПВИПДЙНПК ЙОЖПТНБГЙЕК (ПВЩЮОП ПВЕУРЕЮЙЧБЕФУС ЛБЛПК-ФП УРПУПВ, ЮФПВЩ УЕТЧЕТ НПЗ УЛБЪБФШ, ЮФП ЬФП ЧБЫ ЧЩЪПЧ). пДОБЛП, ЛМЙЕОФЩ НПЗХФ ЧЩЛМАЮЙФШ ЧПЪНПЦОПУФШ ВТПХЪЕТБ РПМХЮБФШ cookies. еУМЙ ЧБЫ УБКФ ДПМЦЕО ПФУМЕЦЙЧБФШ ЛМЙЕОФПЧ У ЧЩЛМАЮЕООЩНЙ cookie, ЕУФШ ДТХЗПК НЕФПД ПФУМЕЦЙЧБОЙС УЕУУЙК (ЪБРЙУШ URL ЙМЙ УРТСФБООЩЕ РПМС ЖПТНЩ), ЛПФПТЩЕ ЧУФТБЙЧБАФУС Ч ТХЮОХА, ФБЛ ЛБЛ ЧПЪНПЦОПУФШ ПФУМЕЦЙЧБОЙС УЕУУЙК ЧУФТПЕОБ Ч API УЕТЧМЕФПЧ Й ТБЪТБВПФБОБ У ХРПТПН ОБ cookies.
API УЕТЧМЕФПЧ (ЧЕТУЙЙ 2.0 Й ЧЩЫЕ) ЙНЕЕФ ЛМБУУ Cookie. ьФПФ ЛМБУУ ПВЯЕДЙОСЕФ ЧУЕ ДЕФБМЙ HTTP ЪБЗПМПЧЛБ Й РПЪЧПМСЕФ ХУФБОБЧМЙЧБФШ ТБЪМЙЮОЩЕ БФФТЙВХФЩ cookie. йУРПМШЪПЧБОЙЕ cookie РТПУФП Й ЕУФШ УНЩУМ ДПВБЧМСФШ ЕЗП Ч ПВЯЕЛФЩ ПФЧЕФПЧ. лПОУФТХЛФПТ РПМХЮБЕФ ЙНС cookie Ч ЛБЮЕУФЧЕ РЕТЧПЗП БТЗХНЕОФБ, Б ЪОБЮЕОЙЕ Ч ЛБЮЕУФЧЕ ЧФПТПЗП. Cookies ДПВБЧМСАФУС Ч ПВЯЕЛФ ПФЧЕФБ РТЕЦДЕ, ЮЕН ЧЩ ПФПЫМЕФЕ МАВПЕ УПДЕТЦЙНПЕ.
Cookie oreo = new Cookie("TIJava", "2000");
res.addCookie(cookie);
Cookies ЙЪЧМЕЧБАФУС РХФЕН ЧЩЪПЧБ НЕФПДБ getCookies( ) ПВЯЕЛФБ HttpServletRequest, ЛПФПТЩК ЧПЪЧТБЭБАФ НБУУЙЧ ЙЪ ПВЯЕЛФПЧ cookie.
Cookie[] cookies = req.getCookies();
ъБФЕН ЧЩ НПЦЕФЕ ЧЩЪЧБФШ getValue( ) ДМС ЛБЦДПЗП ЙЪ cookie ДМС РПМХЮЕОЙС УФТПЛЙ (String) УПДЕТЦЙНПЗП cookie. ч РТЙЧЕДЕООПН ЧЩЫЕ РТЙНЕТЕ getValue("TIJava") ЧЕТОЕФ УФТПЛХ (String), УПДЕТЦБЭХА “2000”.
уЕУУЙС УПУФПЙФ ЙЪ ЪБРТПУБ ЛМЙЕОФПН ПДОПК ЙМЙ ОЕУЛПМШЛЙИ УФТБОЙГ Web УБКФБ ЪБ ПРТЕДЕМЕООЩК РЕТЙПД ЧТЕНЕОЙ. оБРТЙНЕТ, ЕУМЙ ЧЩ РПЛХРБЕФЕ ВБЛБМЕА Ч ТЕЦЙНЕ ПОМБКО, ЧЩ ИПФЙФЕ, ЮФПВЩ УЕУУЙС ВЩМБ РПДФЧЕТЦДЕОБ У ФПЗП НПНЕОФБ, ЛПЗДБ ЧЩ ДПВБЧЙМЙ РЕТЧЩК ЬМЕНЕОФ Ч “УЧПА ЛБТЪЙОХ РПЛХРПЛ” ДП НПНЕОФБ РТПЧЕТЛЙ УПУФПСОЙС ЛБТЪЙОЩ. рТЙ ЛБЦДПН ДПВБЧМЕОЙЙ Ч ЛБТЪЙОХ РПЛХРПЛ ОПЧПЗП ЬМЕНЕОФБ Ч ТЕЪХМШФБФЕ РПМХЮБЕФУС ОПЧПЕ HTTP УПЕДЙОЕОЙЕ, ЛПФППЕ ОЕ ЙНЕЕФ ЙОЖТНБГЙЙ П РТЕДЩДХЭЙИ УПЕДЙОЕОЙСИ ЙМЙ ЬМЕНЕОФБИ, ХЦЕ ОБИПДСЭЙИУС Ч ЛПТЪЙОЕ РПЛХРПЛ. юФПВЩ ЛПНРЕОУЙТПЧБФШ ХФЕЮЛХ ЙОЖПТНБГЙЙ НЕИБОЙЛЙ УОБВДЙМЙ УРЕГЙЖЙЛБГЙЕК cookie, РПЪЧПМСАЭЕК ЧБЫЕНХ УЕТЧМЕФХ УМЕДЙФШ ЪБ УЕУУЙЕК.
пВЯЕЛФ УЕТЧМЕФБ Session ЦЙЧЕФ ОБ УФПТПОЕ УЕТЧЕТБ УПЕДЙОЙФЕМШОПЗП ЛБОБМБ. пО РТЕДОБЪОБЮЕО ДМС УВПТБ РПМЕЪОПК ЙОЖПТНБГЙЙ П ЛМЙЕОФЕ, ЕЗП РЕТЕНЕЭЕОЙЙ РП УБКФХ Й ЧЪБЙНПДЕКУФЧЙА У ОЙН. ьФЙ ДБООЩЕ НПЗХФ РПДИПДЙФШ ДМС РТЕДУФБЧМЕОЙС УЕУУЙЙ, ФБЛ ОБРТЙНЕТ ДМС ЬМЕНЕОФПЧ Ч ЛПТЪЙОЕ РПЛХРПЛ, ЙМЙ ЬФП НПЗХФ ВЩФШ ФБЛЙЕ ДБОЩЕ, ЛБЛ ЙОЖПТНБГЙС ПВ БЧФПТЙЪБГЙЙ, ЛПФПТБС ВЩМБ ЧЧЕДЕОБ РТЙ РЕТЧПН ЧИПДЕ ЛМЙЕОФБ ОБ ЧБЫ Web УБКФ, Й ЛПФПТХА ОЕ ОХЦОП ЧЧПДЙФШ РПЧФПТОП ЧП ЧТЕНС ЧЩРПМОЕОЙС ПРТЕДЕМЕООЩИ ПВТБЭЕОЙК.
лМБУУ Session ЙЪ API УЕТЧМЕФБ ЙУРПМШЪХЕФ ЛМБУУ Cookie, ЮФПВЩ УДЕМБФШ ЬФХ ТБВПФХ. пДОБЛП ЧУЕН ПВЯЕЛФБН Session ОЕПВИПДЙН ХОЙЛБМШОЩК ЙДЕОФЙЖЙЛБФПТ ОЕЛПФПТПЗП ЧЙДБ, ИТБОЙНЩК ОБ УФПТПОЕ ЛМЙЕОФБ Й РЕТЕДБАЭЙКУС ОБ УЕТЧЕТ. Web УБКФЩ НПЗХФ ФБЛЦЕ ЙУРПМШЪПЧБФШ ДТХЗЙЕ ФЙРЩ УМЕЦЕОЙС ЪБ УЕУУЙСНЙ, ОП ЬФЙ НЕИБОЙЪНЩ ВПМЕЕ УМПЦОЩ ДМС ТЕБМЙЪБГЙЙ, ФБЛ ЛБЛ ПОЙ ОЕ ЙОЛБРУХМЙТПЧБОЩ Ч API УЕТЧМЕФПЧ (ФБЛ ЮФП ЧЩ ДПМЦОЩ РЙУБФШ ЙИ ТХЛБНЙ, ЮФПВЩ ТБЪТЕЫЙФШ УЙФХБГЙЙ, ЛПЗДБ ЛМЙЕОФ ПФЛМАЮБЕФ cookies).
чПФ РТЙНЕТ, ЛПФПТЩК ТЕБМЙЪХЕФ УМЕЦЕОЙЕ ЪБ УЕУУЙСНЙ У РПНПЭША УЕТЧМЕФОПЗП API:
//: c15:servlets:SessionPeek.java
// йУРПМШЪПЧБОЙЕ ЛМБУУБ HttpSession.
import java.io.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class SessionPeek extends HttpServlet {
public void service(HttpServletRequest req,
HttpServletResponse res)
throws ServletException, IOException {
// рПМХЮБЕН ПВЯЕЛФ Session РЕТЕД МАВПК
// ЙУИПДСЭЕК РПУЩМЛПК ЛМЙЕОФХ.
HttpSession session = req.getSession();
res.setContentType("text/html");
PrintWriter out = res.getWriter();
out.println("<HEAD><TITLE> SessionPeek ");
out.println(" </TITLE></HEAD><BODY>");
out.println("<h1> SessionPeek </h1>");
// рТПУФПК УЮЕФЮЙЛ РПУЕЭЕОЙК ДМС ЬФПК УЕУУЙЙ.
Integer ival = (Integer)
session.getAttribute("sesspeek.cntr");
if(ival==null)
ival = new Integer(1);
else
ival = new Integer(ival.intValue() + 1);
session.setAttribute("sesspeek.cntr", ival);
out.println("You have hit this page <b>"
+ ival + "</b> times.<p>");
out.println("<h2>");
out.println("Saved Session Data </h2>");
// гЙЛМ РП ЧУЕН ДБООЩН УЕУУЙЙ:
Enumeration sesNames =
session.getAttributeNames();
while(sesNames.hasMoreElements()) {
String name =
sesNames.nextElement().toString();
Object value = session.getAttribute(name);
out.println(name + " = " + value + "<br>");
}
out.println("<h3> Session Statistics </h3>");
out.println("Session ID: "
+ session.getId() + "<br>");
out.println("New Session: " + session.isNew()
+ "<br>");
out.println("Creation Time: "
+ session.getCreationTime());
out.println("<I>(" +
new Date(session.getCreationTime())
+ ")</I><br>");
out.println("Last Accessed Time: " +
session.getLastAccessedTime());
out.println("<I>(" +
new Date(session.getLastAccessedTime())
+ ")</I><br>");
out.println("Session Inactive Interval: "
+ session.getMaxInactiveInterval());
out.println("Session ID in Request: "
+ req.getRequestedSessionId() + "<br>");
out.println("Is session id from Cookie: "
+ req.isRequestedSessionIdFromCookie()
+ "<br>");
out.println("Is session id from URL: "
+ req.isRequestedSessionIdFromURL()
+ "<br>");
out.println("Is session id valid: "
+ req.isRequestedSessionIdValid()
+ "<br>");
out.println("</BODY>");
out.close();
}
public String getServletInfo() {
return "A session tracking servlet";
}
} ///:~
чОХФТЙ НЕФПДБ service( ), getSession( ) ЧЩЪЩЧБЕФ УС ДМС ПВЯЕЛФБ ЪБРТПУБ, ЛПФПТЩК ЧПЪЧТБЭБЕФ ПВЯЕЛФ Session, УЧСЪБООЩК У ЬФЙН ЪБРТПУПН. пВЯЕЛФ Session ОЕ РЕТЕНЕЭБЕФУС РП УЕФЙ, Б ЧНЕУФП ЬФПЗП ПО ЦЙЧЕФ ОБ УЕТЧЕТЕ Й БУУПГЙЙТХЕФУС У ЛМЙЕОФПН Й ЕЗП ЪБРТПУБНЙ.
getSession( ) УХЭЕУФЧХЕФ Ч ДЧХИ ЧЕТУЙСИ: ВЕЪ РБТБНЕФТПЧ, ЛБЛ ЙУРПМШЪПЧБОП ЪДЕУШ, Й getSession(boolean). getSession(true) ЬЛЧЙЧБМЕОФОП ЧЩЪПЧХ getSession( ). рТЙЮЙОБ ЧЧЕДЕОЙС boolean УПУФПЙФ ПРТЕДЕМЕОЙЙ, ЛПЗДБ ЧЩ ИПФЙФЕ УПЪДБФШ ПВЯЕЛФ УЕУУЙЙ, ЕУМЙ ПО ОЕ ОБКДЕО. getSession(true) ЧЩЪЩЧБЕФУС ЮБЭЕ ЧУЕЗП, ПФУАДБ Й ЧЪСМПУШ getSession( ).
ПВЯЕЛФ Session, ЕУМЙ ПО ОЕ ОПЧЩК, ДЕФБМШОП УППВЭБЕФ ОБН П ЛМЙЕОФЕ ЙЪ РТЕДЩДХЭЙИ ЧЙЪЙФПЧ. еУМЙ ПВЯЕЛФ Session ОПЧЩК, ФП РТПЗТБННБ ОБЮЙОБЕФ УВПТ ЙОЖПТНБГЙЙ ПВ БЛФЙЧОПУФЙ ЬФПЗП ЛМЙЕОФБ Ч ЬФПН ЧЙЪЙФЕ. уВПТ ЙОЖПТНБГЙЙ ПВ ЬФПН ЛМЙЕОФЕ ЧЩРПМОСЕФУС НЕФПДБНЙ setAttribute( ) Й getAttribute( ) ПВЯЕЛФБ УЕУУЙЙ.
java.lang.Object getAttribute(java.lang.String)
void setAttribute(java.lang.String name,
java.lang.Object value)
пВЯЕЛФ Session ЙУРПМШЪХЕФ РТПУФЩЕ РБТЩ ЙЪ ЙНЕОЙ Й ЪОБЮЕОЙС ДМС ЪБЗТХЪЛЙ ЙОЖПТНБГЙЙ. йНС СЧМСЕФУС ПВЯЕЛФПН ФЙРБ String, Б ЪОБЮЕОЙЕ НПЦЕФ ВЩФШ МАВЩН ПВЯЕЛФПН, ХОБУМЕДПЧБООЩН ПФ java.lang.Object. SessionPeek УМЕДЙФ ЪБ ФЕН, УЛПМШЛП ТБЪ ЛМЙЕОФ ЧПЪЧТБЭБМУС ЧП ЧТЕНС УЕУУЙЙ. ьФП УДЕМБОП У РПНПЭША ПВЯЕЛФБ sesspeek.cntr ФЙРБ Integer. еУМЙ ЙНС ОЕ ОБКДЕОП, УПЪДБЕФУС ПВЯЕЛФ Integer У ЕДЙОЙЮОЩН ЪОБЮЕОЙЕН, Ч РТПФЙЧОПН УМХЮБЕ Integer УПЪДБЕФУС У ЙОЛТЕНЕОФЙТПЧБООЩН ЪОБЮЕОЙЕН, ЧЪСФЩН ПФ РТЕДЩДХЭЕЗП Integer. оПЧЩК ПВЯЕЛФ Integer РПНЕЭБЕФУС Ч ПВЯЕЛФ Session. еУМЙ ЧЩ ЙУРПМШЪХЕФЕ ЬФПФ ЦЕ ЛМАЮ Ч ЧЩЪПЧЕ setAttribute( ), ФП ОПЧЩК ПВЯЕЛФ ЪБРЙЫЕФУС РПЧЕТИ УФБТПЗП. йОЛТЕНЕОФЙТХЕНЩК УЮЕФЮЙЛ ЙУРПМШЪХЕФУС ДМС ПФПВТБЦЕОЙС ЮЙУМБ ЧЙЪЙФПЧ ЛМЙЕОФБ ЧП ЧТЕНС ЬФПК УЕУЙЙ.
getAttributeNames( ) ПФОПУЙФУС ЛБЛ Л getAttribute( ), ФБЛ Й Л setAttribute( ); ПО ЧПЪЧТБЭБЕФ enumeration ЙЪ ЙНЕО ПВЯЕЛФПЧ, РТЙЛТЕРМЕООЩИ Л ПВЯЕЛФХ Session. гЙЛМ while Ч SessionPeek РПЛБЪЩЧБЕФ ЬФПФ НЕФПД Ч ДЕКУФЧЙЙ.
чЩ НПЦЕФЕ ВЩФШ ХДЙЧМЕОЩ ЛБЛ ДПМЗП УПИТБОСЕФУС ПВЯЕЛФ Session. пФЧЕФ ЪБЧЙУЙФ ПФ ЙУРПМШЪХЕНПЗП ЧБНЙ ЛПОФЕКОЕТБ УЕТЧМЕФПЧ; РП ХНПМЮБОЙА ПВЩЮОП ЬФП ДМЙФУС ДП 30 НЙОХФ(1800 УЕЛХОД), ЬФП ЧЩ НПЦЕФЕ ХЧЙДЕФШ РТЙ ЧЩЪПЧЕ getMaxInactiveInterval( ) ЙЪ ServletPeek. фЕУФЩ РПЛБЪЩЧБАФ ТБЪОЩЕ ТЕЪХМШФБФЩ, Ч ЪБЧЙУЙНПУФЙ ПФ ЛПОФЕКОЕТБ УЕТЧМЕФПЧ. йОПЗДБ ПВЯЕЛФ Session НПЦЕФ ИТБОЙФШУС ЧУА ОПЮШ, ОП С ОЙЛПЗДБ ОЕ ЧЙДЕМ УМХЮБА, ЮФПВЩ ПВЯЕЛФ Session ЙУЮЕЪБМ ТБОШЫЕ ХЛБЪБООПЗП ОЕБЛФЙЧОПЗП ЙОФЕТЧБМБ ЧТЕНЕОЙ. чЩ НПЦЕФЕ РПРТПВПЧБФШ ХУФБОПЧЙФШ ЙОФЕТЧБМ ОЕБЛФЙЧОПНФЙ У РПНПЭША setMaxInactiveInterval( ) ДП 5 УЕЛХОД Й РТПЧЕТЙФШ ПЮЙУФЙФУС МЙ ЧБЫ ПВЯЕЛФ Session ЮЕТЕЪ УППФЧЕФУФЧХАЭЕЕ ЧТЕНС. ьФП НПЦЕФ ВЩФШ ФПФ БФФТЙВХФ, ЛПФПТЩК ЧЩ ЪБИПФЙФЕ ЙУУМЕДПЧБФШ РТЙ ЧЩВПТЕ ЛПОФЕКОЕТБ УЕТЧМЕФПЧ.
еУМЙ ЧЩ ТБОШЫЕ ОЕ ТБВПФБМЙ У УЕТЧЕТПН РТЙМПЦЕОЙК, ЛПФПТЩК ПВТБВБФЩЧБЕФ УЕТЧМЕФЩ ПФ Sun Й РПДДЕТЦЙЧБЕФ JSP ФЕИОПМПЗЙА, ЧЩ НПЦЕФЕ РПМХЮЙФШ ТЕБМЙЪБГЙА Tomcat ДМС Java УЕТЧМЕФПЧ Й JSP, ЛПФПТЩК СЧМСЕФУС ВЕУРМБФОЩН, У ПФЛТЩФЩН ЛПДПН ТЕБМЙЪБГЙЙ УЕТЧМЕФПЧ, Б ПЖЙГЙБМШОБС УУЩМЛБ ОБ ТЕБМЙЪБГЙА УБОЛГЙПОЙТПЧБОБ Sun. еЗП НПЦОП ОБКФЙ ОБ jakarta.apache.org.
уМЕДХКФЕ ЙОУФТХЛГЙЙ РП ЙОУФБМСГЙЙ ТЕБМЙЪБГЙЙ Tomcat, ЪБФЕН ПФТЕДБЛФЙТХКФЕ ЖБКМ server.xml, ЮФПВЩ ПО ХЛБЪЩЧБМ ОБ ЧБЫЕ ДЕТЕЧП ДЙТЕЛФПТЙЕЧ, Ч ЛПФПТПН РПНЕЭЕОЩ ЧБЫЙ УЕТЧМЕФЩ. лБЛ ФПМШЛП ЧЩ ЪБРХУФЙФЕ РТПЗТБННХ Tomcat, ЧЩ УНПЦЕФЕ РТПФЕУФЙТПЧБФШ ЧБЫЙ УЕТЧМЕФЩ.
ьФП ВЩМП ФПМШЛП ЛПТПФЛПЕ ЧЧЕДЕОЙЕ Ч УЕТЧМЕФЩ. еУФШ НОПЗП ЛОЙЗ, РПУЧЕЭЕООЩИ ЬФПК ФЕНЕ. пДОБЛП, ЬФП ЧЧЕДЕОЙЕ ДПМЦОП ДБФШ ЧБН ДПУФБФПЮОП ЙДЕК, ЮФПВЩ РПЪЧПМЙФШ ОБЮБФШ ТБВПФБФШ. лТПНЕ ФПЗП, НОПЗЙЕ ЙЪ ЙДЕК УМЕДХАЭЕЗП ТБЪДЕМБ УОПЧБ ЧПЪЧТБЭБАФ ОБУ Л УЕТЧМЕФБН.
Java Server Pages (JSP) СЧМСЕФУС УФБОДБТФОЩН ТБУЫЙТЕОЙЕН Java, ЛПФПТЩК ПРТЕДЕМЕО ОБ ПУОПЧБОЙЙ УЕТЧМЕФОПЗП тБУЫЙТЕОЙС. гЕМША JSP СЧМСЕФУС ХРТПЭЕОЙЕ УПЪДБОЙС Й ХРТБЧМЕОЙС ДЙОБНЙЮЕУЛЙНЙ Web УФТБОЙГБНЙ.
лБЛ ХРПНЙОБМПУШ ТБОЕЕ, УЧПВПДОП ТБУРТПУФТБОСЕНПЕ рп Tomcat, ЛПФПТХА НПЦОП РПМХЮЙФШ У jakarta.apache.org БЧФПНБФЙЮЕУЛЙ РПДДЕТЦЙЧБЕФ JSP.
JSP РПЪЧПМСЕФ ЧБН ЛПНВЙОЙТПЧБФШ HTML ЛПД Web УФТБОЙГЩ У ЛХУПЮЛБНЙ Java ЛПДБ Ч ПДОПН Й ФПН ЦЕ ДПЛХНЕОФЕ. лПД Java ПЛТХЦБФУС УРЕГЙБМШОЩНЙ СТМЩЛБНЙ, ЛПФПТЩЕ ЗПЧПТСФ JSP ЛПОФЕКОЕТХ, ЮФП ПО ДПМЦЕО ЙУРПМШЪПЧБФШ ЬФПФ ЛПД ДМС ЗЕОЕТБГЙЙ УЕТЧМЕФБ ЙМЙМ ЕЗП ЮБУФЙ. рТЕЙНХЭЕУФЧП JSP Ч ФПН, ЮФП ЧЩ НПЦЕФЕ ЙНЕФШ ЕДЙОЩК ДПЛХНЕОФ, ЛПФПТЩК РТЕДУФБЧМСЕФ Й УФТБОЙГХ, Й Java ЛПД, ЛПФПТЩК ЧЛМАЮБЕФУС Ч ОЕЕ. оЕДПУФБФПФЛ Ч ФПН, ЮФП РПДДЕТЦЙЧБАЭЙК JSP УФТБОЙГХ ЮЕМПЧЕЛ ДПМЦЕО ВЩФШ ПРЩФЕО Й Ч HTML Й Ч Java (ПДОБЛП ТБЪТБВПФЮЙЛ GUI УТЕД ДМС JSP Л ЬФПНХ РТЙВМЙЦБЕФУС).
ч РЕТЧЩК ТБЪ JSP ЪБЗТХЦБЕФУС JSP ЛПОФЕКОЕТПН (ЛПФПТЩК ПВЩЮОП УЧСЪБО У Web УЕТЧЕТПН, ЙМЙ СЧМСЕФУС ЕЗП ЮБУФША), ЛПД УЕТЧМЕФБ, РПНЕЮЕООЩК JSP СТМЩЛБНЙ, БЧФПНБФЙЮЕУЛЙ ЗЕОЕТЙТХЕФУС, ЛПНРЙМЙТХЕФУС Й ЪБЗТХЦБФУС Й ЛПОФЕКОЕТ УЕТЧМЕФПЧ. уФБФЙЮЕУЛБС ЮБУФШ HTML УФТБОЙГЩ ЧПУРТПЙЪЧПДЙФУС РХФЕН РПУЩМЛЙ УФБФЙЮЕУЛПЗП ПВЯЕЛФБ String Ч НЕФПД write( ). дЙОБНЙЮЕУЛБС ЮБУФШ ЧЛМАЮБЕФУС РТСНП Ч УЕТЧМЕФ.
йУИПДС ЙЪ ЬФПЗП, РПЛБ ЙУИПДОЩК ФЕЛУФ JSP УФТБОЙГЩ ОЕ ЙЪНЕОСЕФУС, ПОБ ЧЕДЕФ УЕВС ФБЛ, ЛБЛ ВХДФП ЬФП УФБФЙЮЕУЛБС HTML УФТБОЙГБ У БУУПГЙЙТПЧБООЩН УЕТЧМЕФПН (ПДОБЛП, ЧЕУШ HTML ЛПД ОБ УБНПН ДЕМЕ ЗЕОЕТЙТХЕФУС УЕТЧМЕФПН). еУМЙ ЧЩ ЙЪНЕОСЕФЕ ЙУИПДОЩК ЛПД ДМС JSP, ПО БЧФПНБФЙЮЕУЛЙ РЕТЕЛПНРЙМЙТХЕФУС Й РЕТЕЗТХЦБЕФУС РТЙ УМЕДХАЭЕН ЪБРТПУЕ ЬФПК УФТБОЙГЩ. лПОЕЮОП, ЙЪ-ЪБ ЧУЕК ЬФПК ДЙОБНЙЛЙ ЧЩ ХЧЙДЙФЕ ЪБНЕДМЕОЩК ПФЧЕФ ОБ РЕТЧЩК ЪБРТПУ ЬФПК JSP УФТБОЙГЩ. оП РПУЛПМШЛХ JSP ЙУРПМШЪХЕФ ОЕНОПЗП ВПМШЫЕ, ЮЕН РТПУФП ЙЪНЕОЕОЙС, ПВЩЮОП ЧЩ ОЕ ЧУФТЕФЙФЕ ЬФПК ЪБДЕТЦЛЙ.
уФТХЛФХТБ JSP УФТБОЙГЩ УПУФПЙФ ЙЪ РЕТЕНЕЫЙЧБОЙС УЕТЧМЕФБ Й HTML УФТБОЙГЩ. JSP СТМЩЛЙ ОБЮЙОБАФУС Й ЪБЛБОЮЙЧБАФУС ХЗМПЧЩНЙ УЛПВЛБНЙ, ФБЛ ЦЕ ЛБЛ Й СТМЩЛЙ HTML, ОП ЬФЙ СТМЩЛЙ ФБЛЦЕ ЧЛМАЮБАФ УЙНЧПМ РТПГЕОФПЧ, ФБЛ ЮФП ЧУЕ JSP СТМЩЛЙ ПВПЪОБЮБАФУС
<% JSP code here %>
ъБ РЕТЧЩН ЪОБЛПН РТПГЕОФБ НПЗХФ УМЕДПЧБФШ ДТХЗЙЕ УЙНЧПМЩ, ЛПФПТЩЕ ПЪОБЮБАФ ЮБУФШ JSP ЛПДБ Ч СТМЩЛЕ.
оЙЦЕ РТЙЧЕДЕО ПЮЕОШ РТПУФПК РТЙНЕТ JSP, ЛПФПТЩК ЙУРПМШЪХЕФ УФБОДБТФОХА ЧЩЪПЧ Java ВЙВМЙПФЕЛЙ ДМС РПМХЮЕОЙС ФЕЛХЭЕЗП ЧТЕНЕОЙ Ч НЙМЙУЕЛХОДБИ, ЪБФЕН ЬФП ЪОБЮЕОЙЕ ДЕМЙФУС ОБ 1000, ДМС РПМХЮЕОЙЕ ЧТЕНЕОЙ Ч УЕЛХОДБИ. фБЛ ЛБЛ ЙУРПМШЪХЕФУС JSP ЧЩТБЦЕОЙЕ ( <%= ), ТЕЪХМШФБФ ЧЩЮЙУМЕОЙК ЛПОЧЕТФЙТХЕФУС Ч String, Й РПНЕЭБЕФУС ОБ ЗЕОЕТЙТХЕНХА Web УФТБОЙГХ:
//:! c15:jsp:ShowSeconds.jsp <html><body> <H1>The time in seconds is: <%= System.currentTimeMillis()/1000 %></H1> </body></html> ///:~
ч JSP РТЙНЕТБИ ЬФПК ЛОЙЗЙ РЕТЧБС Й РПУМЕДОСС УФТПЛЙ ОЕ ВХДХФ ЧЛМАЮБФШУС Ч ЖБКМ ТЕБМШОПЗП ЛПДБ, ЛПФПТЩК РПНЕЭЕО Ч БТИЙЧ ЙУИПДОПЗП ЛПДБ, РТЙМБЗБАЭЙКУС Л ЬФПК ЛОЙЗЕ.
лПЗДБ ЛМЙЕОФ УПЪДБЕФ ЪБРТПУ Л JSP УФТБОЙГЕ, Web УЕТЧЕТ ДПМЦЕО ВЩФШ УЛПОЖЙЗХТЙТПЧБО, ЮФПВЩ УППФЧЕФУФЧПЧБФШ ЪБРТПУБН JSP ЛПОФЕКОЕТБ, ЛПФПТЩК ЪБФЕН ЧЩЪЩЧБЕФ УФТБОЙГХ. лБЛ ХРПНЙОБМПУШ ТБОЕЕ, РТЙ РЕТЧПН ЧЩЪПЧЕ УФТБОЙГЩ, ЛПНРПОЕОФЩ, ХЛБЪБООЩЕ ОБ УФТБОЙГЕ ЛПНРПОЕОФЩ ЗЕОЕТЙТХАФУС Й ЛПНРЙМЙТХАФУС JSP ЛПОФЕОЕТПН Ч ПДЙО ЙМЙ ОЕУЛПМШЛП УЕТЧМЕФПЧ. ч РТЙЧЕДЕООПН ЧЩЫЕ РТЙНЕТЕ УЕТЧМЕФ ВХДЕФ УПДЕТЦБФШ ЛПД ДМС ЛПОЖЙЗХТЙТПЧБОЙС ПВЯЕЛФБ HttpServletResponse, РТПЙЪЧПДСЭЕЗП ПВЯЕЛФ PrintWriter (ЛПФПТЩК ЧУЕЗДБ ОБЪЩЧБЕФУС out), Б ЪБФЕН РТПЙУИПДЙФ ЧЩЮЙУМЕОЙЕ String, ЛПФПТБС РПУЩМБЕФУС Ч out. лБЛ ЧЩ НПЦЕФЕ ЧЙДЕФШ, ЧУЕ ЬФП ЧЩРПМОСЕФУС У РПНПЭША ПЮЕОШ ЛТБФЛПК ЙОУФТХЛГЙЙ, ОП УТЕДОЕУФБФЙУФЙЮЕУЛЙК HTML РТПЗТБННЙУФ/Web ДЙЪБКОЕТ ОЕ ЙНЕАФ ПРЩФБ Ч ОБРЙУБОЙЙ ФБЛПЗП ЛПДБ.
уЕТЧМЕФЩ ЧЛМАЮБАФ ЛМБУУЩ, ЛПФПТЩЕ ПВЕУРЕЮЙЧБАФ УППФЧЕФУФЧХАЭЙЕ ХФЙМЙФЩ, ФБЛЙЕ ЛБЛ HttpServletRequest, HttpServletResponse, Session Й Ф.Д. пВЯЕЛФЩ ЬФЙИ ЛМБУУПЧ ЧУФТПЕОЩ Ч JSP УРЕГЙЖЙЛБГЙА Й БЧФПНБФЙЮЕУЛЙ ДПУФХРОЩ ДМС ЙУРПМШЪПЧБОЙС Ч ЧБЫЕН JSP ЛПДЕ ВЕЪ ОБРЙУБОЙС ДПРПМОЙФЕМШОЩИ УФТПЮЕЛ ЛПДБ оЕСЧОЩЕ ПВЯЕЛФЩ JSP УЧЕДЕОЩ Ч РТЙЧЕДЕООХА ОЙЦЕ ФБВМЙГХ.
|
оЕСЧОБС РЕТЕНЕООБС |
фЙР (javax.servlet) |
пРЙУБОЙЕ |
зТБОЙГЩ |
|
request |
ъБЧЙУСЭЙК ПФ РТПФПЛПМБ ФЙР, РТПЙЪЧПДОЩК ПФ HttpServletRequest |
ъБРТПУ, ЛПФПТЩК ЧЩЪЩЧБЕФ ПВТБЭЕОЙЕ Л УМХЦВЕ. |
ЪБРТПУ |
|
response |
ъБЧЙУСЭЙК ПФ РТПФПЛПМБ ФЙР, РТПЙЪЧПДОЩК ПФ HttpServletResponse |
пФЧЕФ ОБ ЪБРТПУ. |
УФТБОЙГБ |
|
pageContext |
jsp.PageContext |
уПДЕТЦЙНПЕ УФТБОЙГЩ ЧЛМАЮБЕФ ЪБЧЙУСЭЙЕ ПФ ТЕБМЙЪБГЙЙ ПУПВЕООПУФЙ Й ПВЕУРЕЮЙЧБЕФ ХДПВОЩЕ НЕФПДЩ Й ДПУФХР Л РТПУФТБОУФЧХ ЙНЕО ДМС JSP. |
УФТБОЙГБ |
|
session |
ъБЧЙУСЭЙК ПФ РТПФПЛПМБ ФЙР, РТПЙЪЧПДОЩК ПФ http.HttpSession |
пВЯЕЛФ УЕУУЙЙ, УПЪДБООЩК ДМС ЛМЙЕОФУЛПЗП ЪБРТПУБ. уНПФТЙФЕ ПВЯЕЛФ Session ДМС УЕТЧМЕФПЧ. |
УЕУУЙС |
|
application |
ServletContext |
лПОФЕЛУФ УЕТЧМЕФБ РПМХЮБЕФУС ЙЪ ЛПОЖЙЗХТЙТХАЭЕЗП УЕТЧМЕФ ПВЯЕЛФБ (e.g., getServletConfig(), getContext( ). |
РТЙМПЦЕОЙЕ |
|
out |
jsp.JspWriter |
пВЯЕЛФ, ЛПФПТЩК РЙЫЕФ Ч ЧЩИПДОПК РПФПЛ. |
УФТБОЙГБ |
|
config |
ServletConfig |
ServletConfig ДМС ЬФПЗП JSP. |
УФТБОЙГБ |
|
page |
java.lang.Object |
ьЛЪЕНРМСТ ЛМБУУБ УФТБОЙГЩ, ПВТБВБФЩЧБАЭЕК ЬФПФ ЪБРТПУ. |
УФТБОЙГБ |
зТБОЙГЩ ЧЙДЙНПУФЙ ЛБЦДПЗП ПВЯЕЛФБ НПЗХФ ЪОБЮЙФЕМШОП ПФМЙЮБФШУС. оБРТЙНЕТ, ПВЯЕЛФ session ЙНЕЕФ ЗТБОЙГЩ ЧЙДЙНПУФЙ, ЛПФПТЩЕ РТЕЧЩЫБАФ УФТБОЙГХ, ФБЛ ЛБЛ ПО НПЦЕФ ПФЧЕЮБФШ ЪБ ОЕУЛПМШЛП ЛМЙЕОФУЛЙИ ЪБРТПУПЧ Й УФТБОЙГ. пВЯЕЛФ application НПЦЕФ РТЕДПУФБЧЙФШ УЕТЧЙУ ДМС ЗТХРРЩ JSP УФТБОЙГ, ЛПФПТЩЕ УПЧНЕУФОП РТЕДУФБЧМСАФ Web РТЙМПЦЕОЙЕ.
дЙТЕЛФЙЧЩ СЧМСАФУС УППВЭЕОЙСНЙ ДМС JSP ЛПОФЕОЕТБ Й ХЛБЪЩЧБАФУС УЙНЧПМПН “@”:
<%@ directive {attr="value"}* %>
дЙТЕЛФЙЧЩ ОЙЮЕЗП ОЕ РПУЩМБАФ Ч РПФПЛ out, ОП ПОЙ ЧБЦОЩ Ч ОБУФТПКЛЕ БФТЙВХФПЧ ЧБЫЙИ JSP УФТБОЙГ Й ЧЪБЙНПЦЕКУФЧЙК У JSP ЛПОФЕКОЕТПН. оБРТЙНЕТ УФТПЛБ:
<%@ page language="java" %>
УППВЭБЕФ, ЮФП ОБ JSP УФТБОЙГЕ ЙУРПМШЪХЕФУС СЪЩЛ УЛТЙРФПЧ Java. оБ УБНПН ДЕМЕ JSP УРЕГЙЖЙЛБГЙЙ ФПМШЛП ПРЙУЩЧБАФ, ЮФП УЕНБОФЙЛБ СЪЩЛБ УЛТЙРФПЧ БОБМПЗЙЮОБ “Java”. оБЪОБЮЕОЙЕ ЬФПК ДЙТЕЛФЙЧЩ УПУФПЙФ Ч РТЙДБОЙЙ ЗЙВЛПУФЙ ФЕИОПМПЗЙЙ JSP. ч ВХДХАЭЕН, ЕУМЙ ЧЩ ЧЩВЕТЙФЕ ДТХЗПК СЪЩЛ, УЛБЦЕН Python (ИПТПЫЙК ЧЩВПТ ДМС ОБРЙУБОЙС УЛТЙРФПЧ), Й ЬФПФ СЪЩЛ ВХДЕФ ЙНЕФШ РПДДЕТЦЛХ Java Run-time Environment, У РТЙНЕОЕОЙЕН ФЕИОПМПЗЙЙ Java ПВЯЕЛФЩОЩИ НПДЕМЕК ДМС УТЕДЩ УЛТЙРФПЧ, ПУПВЕООП ЬФП ПФОПУЙФУС Л ПРТЕДЕМЕООЩН ЧЩЫЕ РЕТЕНЕООЩН, УЧПКУФЧБН JavaBeans Й РХВМЙЮОЩН НЕФПДБН.
оБЙВПМЕЕ ЧБЦОБС ДЙТЕЛФЙЧБ - ЬФП ДЙТЕЛФЙЧБ УФТБОЙГЩ. пОБ ПРТЕДЕМСЕФ ОПНЕТ УФТБОЙГЩ Ч ЪБЧЙУЙНПУФЙ ПФ БФТЙВХФПЧ Й ЧЪБЙНПДЕКУФЧЙС НЕЦДХ ЬФЙНЙ БФТЙВХФБНЙ Й JSP ЛПОФЕКОЕТПН. л ФБЛЙН БФТЙВХФБН ПФОПУСФУС: language, extends, import, session, buffer, autoFlush, isThreadSafe, info Й errorPage. оБРТЙНЕТ:
<%@ page session=”true” import=”java.util.*” %>
ьФБ УФТПЛБ ХЛБЪЩЧБЕФ, ЮФП УФТБОЙГБ ФТЕВХЕФ ХЮБУФЙС HTTP УЕУУЙЙ. фБЛ ЛБЛ НЩ ОЕ ХУФБОПЧЙМЙ ДЙТЕЛФЙЧЩ СЪЩЛБ, JSP ЛПОФЕКОЕТ РП ХНПМЮБОЙА ЙУРПМШЪХЕФ Java Й РПДТБЪХНЕЧБЕНХА РЕТЕНЕООХА СЪЩЛБ УЛТЙРФПЧ, ОБЪЩЧБЕНХА session ФЙРБ javax.servlet.http.HttpSession. еУМЙ ВЩ ДЙТЕЛФЙЧБ ВЩМБ МПЦОБ, ФП ОЕСЧОБС РЕТЕНЕООБС session ВЩМБ ВЩ ОЕДПУФХРОБ. еУМЙ РЕТЕНЕООБС session ОЕ ХЛБЪБОБ, ФП ЙУРПМШЪХЕФУС ЪОБЮЕОЙЕ РП ХНПМЮБОЙА “true”.
бФФТЙВХФ import ПРЙУЩЧБЕФ ФЙРЩ, ЛПФПТЩЕ ДПУФХРОЩ Ч ПЛТХЦЕОЙЙ УЛТЙРФПЧ. ьФПФ БФТЙВХФ ЙУРПМШЪХЕФУС ФБЛ, ЛБЛ ЕУМЙ ВЩ ПО ЙУРПМШЪПЧБМУС Ч СЪЩЛЕ РТПЗТБННЙТПЧБОЙС Java, Ф.Е. ЬФП ТБЪДЕМЕОЩК ЪБРСФЩНЙ УРЙУПЛ, ЛБЛ Й ПВЩЮОПЕ ЧЩТБЦЕОЙЕ import. ьФПФ УРЙУПЛ ЙНРПТФЙТХЕФУС ТЕБМЙЪБГЙЕК ФТБОУМЙТПЧБООПК JSP УФТБОЙГЩ Й ДПУФХРЕО ДМС УТЕДЩ УЛТЙРФБ. пРСФШ ФБЛЙ, РПЛБ ЬФП ПРТЕДЕМЕОП, ЛПЗДБ ЪОБЮЕОЙЕ ДЙТЕЛФЙЧЩ СЪЩЛБ - “java”.
рПУМЕ ФПЗП, ЛБЛ ВЩМЙ ЙУРПМШЪПЧБОЩ ДЙТЕЛФЙЧЩ ДМС ОБУФПКЛЙ УТЕДЩ УЛТЙРФПЧ, ЧЩ НПЦЕФЕ ЙУРПМШЪПЧБФШ ЬМЕНЕОФЩ СЪЩЛБ УЛТЙРФПЧ. JSP 1.1 ЙНЕЕФ ФТЙ ЬМЕНЕОФБ СЪЩЛБ УЛТЙРФПЧ — declarations, scriptlets, Й expressions. Declaration ДЕЛМБТЙТХЕФ ЬМЕНЕОФЩ, Scriptlet - ЬФП ЖТБЗНЕОФ ЙОУФТХЛГЙК, Б еxpression - ЬФП ЪБЛПОЮЕООПЕ ЧЩТБЦЕОЙЕ СЪЩЛБ. ч JSP ЛБЦДЩК ЬМЕНЕОФ УГЕОБТЙС ОБЮЙОБЕФУС У “<%”. уЙОФБЛУЙУ ДМС ЛБЦДПЗП УМЕДХАЭЙК:
<%! declaration %> <% scriptlet %> <%= expression %>
рТПВЕМЩ РПМУЕ “<%!”, “<%”, “<%=” Й РЕТЕД “%>” ОЕ ПВСЪБФЕМШОЩ.
чУЕ ЬФЙ СТМЩЛЙ ВБЪЙТХАФУС ОБ XML. чЩ ДБЦЕ НПЦЕФЕ УЛБЪБФШ, ЮФП JSP УФТБОЙГБ НПЦЕФ ВЩФШ РТЕПВТБЪПЧБОБ Ч XML ДПЛХНЕОФ. ьЛЧЙЧБМЕОФОЩК XML УЙОФБЛУЙУ ДМС ЬМЕНЕОФПЧ УЛТЙРФПЧ, РТЙЧЕДЕООЩИ ЧЩЫЕ, ДПМЦЕО ВЩФШ:
<jsp:declaration> declaration </jsp:declaration> <jsp:scriptlet> scriptlet </jsp:scriptlet> <jsp:expression> expression </jsp:expression>
лТПНЕ ФПЗП, ЕУФШ ДЧБ ФЙРБ ЛПНЕОФБТЙЕЧ:
<%-- jsp comment --%> <!-- html comment -->
рЕТЧБС ЖПТНБ РПЪЧПМСЕФ ЧБН ДПВБЧМСФШ ЛПНРПОЕОФЩ Ч ЙУИПДОЩК ФЕЛУФ JSP УФТБОЙГЩ, ЛПФПТЩК ОЕ ВХДЕФ РПСЧМСФШУС Ч МАВПК ЖПТНЕ HTML УФТБОЙГЩ, РПУЩМБЕНПК ЛМЙЕОФХ. лПОЕЮОП, ЧФПТБС ЖПТНБ ЛПНЕОФБТЙЕЧ ОЕ УРЕЮЕЖЙЮОП ДМС JSP — ЬФП РТПУФП ПВЩЮОЩК ЛПНЕОФБТЙК HTML. юФП ЙОФЕТЕУОП, ЧЩ НПЦЕФЕ ЧУФБЧЙФШ JSP ЛПД ЧОХФТШ HTML ЛПНЕОФБТЙС, Й ЛПНЕОФБТЙК ВХДЕФ ЧУФБЧМЕО Ч ТХЪХМШФЙТХАЭХА УФТБОЙГХ, ЧЛМАЮБС ТЕЪХМШФБФ ТБВПФЩ JSP ЛПДБ.
Declaration ЙУРПШЪХЕФУС ДМС ПВЯСЧМЕОЙС РЕТЕНЕООЩИ Й НЕФПДПЧ Ч СЪЩЛЕ УЛТЙРФПЧ (РПЛБ ФПМШЛП Ч Java), ЙУРПМШЪХЕНЩИ JSP УФТБОЙГЕК. дЕЛМБТБГЙС ДПМЦОБ ВЩФШ ЪБЧЕТЫЕООПК ЙОУФТХЛГЙЕК Java Й ОЕ НПЦЕФ УПЧЕТЫБФШ ЧЩЧПД Ч РПФПЛ out. ч РТЙЧЕДЕООПН ОЙЦЕ РТЙНЕТЕ Hello.jsp ДЕЛМБТБГЙС РЕТЕНЕООЩИ loadTime, loadDate Й hitCount СЧМСЕФУС ЪБЛПОЮЕООПК ЙОУФТХЛГЙЕК Java, ЛПФПТБС ПВЯСЧМСЕФ Й ЙОЙГЙБМЙЪЙТХЕФ ОПЧЩЕ РЕТЕНЕООЩЕ.
//:! c15:jsp:Hello.jsp
<%-- This JSP comment will not appear in the
generated html --%>
<%-- This is a JSP directive: --%>
<%@ page import="java.util.*" %>
<%-- These are declarations: --%>
<%!
long loadTime= System.currentTimeMillis();
Date loadDate = new Date();
int hitCount = 0;
%>
<html><body>
<%-- The next several lines are the result of a
JSP expression inserted in the generated html;
the '=' indicates a JSP expression --%>
<H1>This page was loaded at <%= loadDate %> </H1>
<H1>Hello, world! It's <%= new Date() %></H1>
<H2>Here's an object: <%= new Object() %></H2>
<H2>This page has been up
<%= (System.currentTimeMillis()-loadTime)/1000 %>
seconds</H2>
<H3>Page has been accessed <%= ++hitCount %>
times since <%= loadDate %></H3>
<%-- A "scriptlet" that writes to the server
console and to the client page.
Note that the ';' is required: --%>
<%
System.out.println("Goodbye");
out.println("Cheerio");
%>
</body></html>
///:~
лПЗДБ ЧЩ ЪБРХУФЙФЕ ЬФХ РТПЗТБННХ, ЧЩ ХЧЙДЙФЕ, ЮФП РЕТЕНЕООЩЕ loadTime, loadDate Й hitCount УПИТБОСАФ УЧПЙ ОБЮЕОЙС НЕЦДХ ПВТБЭЕОЙСНЙ Л УФТБОЙГЕ, ФБЛ ЮФП, ЛПОЕЮОП, ПОЙ СЧМСАФУС РПМСНЙ, Б ОЕ МПЛБМШОЩНЙ РЕТЕНЕООЩНЙ.
ч ЛПОГЕ РТЙНЕТБ УЛТЙРМЕФ РЙЫЕФ “Goodbye” ОБ ЛПОУПМЕ Web УЕТЧЕТБ Й “Cheerio” Ч ОЕСЧОЩК ПВЯЕЛФ out ФЙРБ JspWriter. уЛТЙРМЕФЩ НПЗХФ УПДЕТЦБФШ МАВПК ЖТБЗНЕОФ ЛПДБ, УПДЕТЦБЭЙК РТБЧЙМШОЩЕ Java ЙОУФТХЛГЙЙ. уЛТЙРМЕФЩ ЧЩРПМОСАФУС ЧП ЧТЕНС ПВТБВПФЛЙ ЪБРТПУБ. лПЗДБ ЧУЕ ЖТБЗНЕОФЩ УЛТЙРМЕФПЧ Ч ДБООПН JSP УЛПНВЙОЙТПЧБОЩ ФБЛ, ЛБЛ ПОЙ ЧЧЕДЕОЩ Ч JSP УФТБОЙГХ, ПОЙ ДПМЦОЩ РТПЙЪЧЕУФЙ ДЕУФЧЙФЕМШОПЕ ЧЩТБЦЕОЙЕ, ЛПФПТПЕ ПРТЕДЕМЕОП Ч СЪЩЛЕ РТПЗТБННЙТПЧБОЙС Java. вХДЕФ ЙМЙ ОЕФ РТПЙЪЧПДЙФШУС ЛБЛПК-МЙВП ЧЩЧПД Ч РПФПЛ out ЪБЧЙУЙФ ПФ ЛПДБ УЛТЙРМЕФБ. чЩ ДПМЦОЩ ВЩФШ ХЧЕТЕОЩ, ЮФП УЛТЙРМЕФЩ НПЗХФ РТПЙЪЧПДЙФШ ЛБЛЙЕ-МЙВП ЬЖЖЕЛФЩ РТЙ ЙЪНЕОЕОЙЙ ЧЙДЙНЩИ ДМС ОЙИ ПВЯЕЛФПЧ.
JSP ЧЩТБЦЕОЙС (expression) НПЗХФ ВЩФШ ОБКДЕОЩ УТЕДЙ HTML ЛПДБ Ч УТЕДОЕК ЮБУФЙ Hello.jsp. чЩТБЦЕОЙС ДПМЦОЩ ВЩФШ ЪБЛПОЮЕООЩНЙ Java ЙОУФТХЛГЙСНЙ, ЛПФПТЩЕ ЧЩЮЙУМСАФ, РТЙЧПДСФ Л String, Й РПУЩМБАФ Ч out. еУМЙ ТЕЪХМШФБФ ЧЩТБЦЕОЙС ОЕ НПЦЕФ ВЩФШ РТЙЧЕДЕО Л String, ЧЩВТБУЩЧБЕФУС ClassCastException.
рТЙЧЕДЕООЩК ОЙЦЕ РТЙНЕТ УПЦ У РТЙЧЕДЕООЩН ТБОЕЕ Ч ТБЪДЕМЕ, РПУЧСЭЕООПН УЕТЧМЕФБН. рТЙ РЕТЧПН ПВТБЭЕОЙЙ Л УФТБОЙГЕ ПО ПРТЕДЕМСЕФ, ЮФП Х ЧБУ ОЕФ РПМЕК Й ЧПЪЧТБЭБЕФ УФТБОЙГХ, УПДЕТЦБЭХА ЖПТНХ, ЙУРПМШЪХС ФПФ ЦЕ УБНК ЛПД, ЮФП Й Ч РТЙНЕТЕ У УЕТЧМЕФПН, ОП Ч ЖПТНБФЕ JSP. лПЗДБ ЧЩ ПФУЩМБЕФЕ ЖПТНХ У ЪБРПМОЕООЩНЙ РПМСНЙ ОБ ФПФ ЦЕ УБНЩК JSP URL, ПО ОБИПДЙФ РПМС Й ПФПВТБЦБЕФ ЙИ. ьФП ИПТПЫБС ФЕИОЙЛБ, РПУЛПМШЛХ ПОБ РПЪЧПМСЕФ ЧБН ЙНЕФШ Й УФТБОЙГХ, УПДЕТЦБЭХА ЖПТНХ ДМС ЪБРПМОЕОЙС РПМШЪПЧБФЕМЕН, Й ЛПД ПФЧЕФБ ОБ ЬФХ ЖПТНХ, ЛБЛ ЕДЙОЩК ЖБКМ, ЮФП ПВМЕЗЮБЕФ УПЪДБОЙЕ Й РПДДЕТЦЛХ.
//:! c15:jsp:DisplayFormData.jsp
<%-- Fetching the data from an HTML form. --%>
<%-- This JSP also generates the form. --%>
<%@ page import="java.util.*" %>
<html><body>
<H1>DisplayFormData</H1><H3>
<%
Enumeration flds = request.getParameterNames();
if(!flds.hasMoreElements()) { // No fields %>
<form method="POST"
action="DisplayFormData.jsp">
<% for(int i = 0; i < 10; i++) { %>
Field<%=i%>: <input type="text" size="20"
name="Field<%=i%>" value="Value<%=i%>"><br>
<% } %>
<INPUT TYPE=submit name=submit
value="Submit"></form>
<%} else {
while(flds.hasMoreElements()) {
String field = (String)flds.nextElement();
String value = request.getParameter(field);
%>
<li><%= field %> = <%= value %></li>
<% }
} %>
</H3></body></html>
///:~
оБЙВПМЕЕ ЙОФЕТЕУОБС ПУПВЕООПУФШ ЬФПЗП РТЙНЕТБ УПУФПЙФ Ч ФПН, ЮФП ПО ДЕНПОУФТЙТХЕФ, ЛБЛ ЛПД УЛТЙРМЕФБ НПЦЕФ ВЩФШ УНЕЫБО У HTML ЛПДПН, ДБЦЕ Ч ФПЮЛЕ ЗЕОЕТБГЙЙ HTML У РПНПЭША ГЙЛМБ for ЙЪ Java. ьФП ПУПВЕООП ИПТПЫП ДМС РПУФТПЕОЙС ЧУЕИ ЧЙДПЧ ЖПТН, Ч ЛПФПТЩИ РТЙУХФУФЧХЕФ РПЧФПТСАЭЙКУС HTML ЛПД.
рТПУНБФТЙЧБС HTML ДПЛХНЕОФБГЙА РП УЕТЧМЕФБН Й JSP, ЧЩ ОБКДЕФЕ ЧПЪНПЦОПУФШ РПМХЮБФШ ЙОЖПТНБГЙА ПФОПУЙФЕМШОП ЪБРХЭЕООПЗП УЕТЧМЕФБ ЙМЙ JSP. рТЙЧЕДЕООЩК ОЙЦЕ РТЙНЕТ ПФПВТБЦБЕФ ОЕЛПФПТЩЕ ЙЪ ЧПЪНПЦОЩИ ДБООЩИ.
//:! c15:jsp:PageContext.jsp
<%--Viewing the attributes in the pageContext--%>
<%-- Note that you can include any amount of code
inside the scriptlet tags --%>
<%@ page import="java.util.*" %>
<html><body>
Servlet Name: <%= config.getServletName() %><br>
Servlet container supports servlet version:
<% out.print(application.getMajorVersion() + "."
+ application.getMinorVersion()); %><br>
<%
session.setAttribute("My dog", "Ralph");
for(int scope = 1; scope <= 4; scope++) { %>
<H3>Scope: <%= scope %> </H3>
<% Enumeration e =
pageContext.getAttributeNamesInScope(scope);
while(e.hasMoreElements()) {
out.println("\t<li>" +
e.nextElement() + "</li>");
}
}
%>
</body></html>
///:~
ьФПФ РТЙНЕТ ФБЛЦЕ РПЛБЪЩЧБЕФ ЙУРПМШЪПЧБОЙЕ ЧОЕДТЕОЙС Ч HTML Й РПУЩМЛХ Ч out ДМС РПМХЮЕОЙС ТЕЪХМШФЙТХАЭЕК HTML УФТБОЙГЩ.
рЕТЧЩК ЛХУПЛ ЙОЖПТНБГЙЙ ЧЩДБЕФ ЙНС УЕТЧМЕФБ, ЛПФПТЩК, ЧЕТПСФОП, ВХДЕФ РТПУФП “JSP”, ОП ЬФП ЪБЧЙУЙФ ПФ ЧБЫЕК ТЕБМЙЪБГЙЙ. чЩ ФБЛЦЕ НПЦЕФЕ ПВОБТХЦЙФШ ФЕЛХЭХА ЧЕТУЙА ЛПОФЕКОЕТБ УЕТЧМЕФПЧ, ЙУРПМШЪХС ПВЯЕЛФ РТЙМПЦЕОЙС. оБЛПОЕГ, РПУМЕ ХУФБОПЧЛЙ БФТЙВХФПЧ УЕУУЙЙ, ПФПВТБЦБЕФУС “attribute names” Ч ПРТЕДЕМЕООЩИ РТЕДЕМБИ ЧЙДЙНПУФЙ. юБЭЕ ЧУЕЗП ЧЩ ОЕ ЙУРПМШЪХЕФЕ ЗТБОЙГЩ ЧЙДЙНПУФЙ Ч JSP РТПЗТБННЙТПЧБОЙЙ. пОЙ РТПУФП РПЛБЪБОЩ ФХФ ДМС РТЙДБОЙС РТЙНЕТХ ХЧМЕЛБФЕМШОПУФЙ еУФШ ЮЕФЩТЕ ЗТБОЙГЩ ЧЙДЙНПУФЙ БФТЙВХФБ. чПФ ПОЙ: РТЕДЕМЩ УФТБОЙГЩ (ЗТБОЙГБ 1), РТЕДЕМЩ ЪБРТПУБ (ЗТБОЙГБ 2), РТЕДЕМЩ УЕУУЙЙ (ЗТБОЙГБ — ЪДЕУШ ФПМШЛП ПДЙО ЬМЕНЕОФ ДПУФХРЕО Ч РТЕДЕМБИ УЕУУЙЙ - ЬФП “My dog”, ДПВБЧМЕООЩК РЕТЕД ГЩЛМПН for), Й РТЕДЕМЩ РТЙМПЦЕОЙС (ЗТБОЙГБ 4), ПУОПЧБООЩЕ ОБ ПВЯЕЛФЕ ServletContext. уХЭЕУФЧХЕФ ЕДЙОУФЧЕООЩК ServletContext ДМС ЛБДПЗП “Web РТЙМПЦЕОЙС” Ч ЛБЦДПК Java Virtual Machine. (“Web РТЙМПЦЕОЙЕ” - ЬФП ОБВПТ УЕТЧМЕФПЧ Й УПДЕТЦЙНПЗП УФТБОЙЮЕЛ, ПФОПУСЭЙИУС Л ПРТЕДЕМЕООПНХ РПДНОПЦЕУФЧХ РТПУФТБОУФЧБ ЙНЕО URL УЕТЧЕТБ, ФБЛЙИ ЛБЛ /ЛБФБМПЗ. пВЩЮОП ЬФП ХУФБОБЧМЙЧБЕФУС Ч ЛПОЖЙЗХТБГЙПООПН ЖБКМЕ.) ч РТЕДЕМБИ РТЙМПЦЕОЙС ЧЩ ЧЙДЙФЕ ПВЯЕЛФЩ, ЛПФПТЩЕ РТЕДУФБЧМСАФ РХФШ Л ТБВПЮЕНХ ДЙТЕЛФПТЙА Й ЧТЕНЕООПНХ ДЙТЕЛФПТЙА.
уЕУУЙЙ ВЩМЙ ЧЧЕДЕОЩ Ч РТЕДЩДХЭЕН ТБЪДЕМЕ П УЕТЧМЕФБИ Й ФБЛЦЕ ДПУФХРОЩ Ч JSP. уМЕДХАЭЙК РТЙНЕТ ЙУУМЕДХЕФ ПВЯЕЛФ session Й РПЪЧПМСЕФ ЧБН ХРТБЧМСФШ РТПНЕЦХФЛПН ЧТЕНЕОЙ РПУМЕ ЛПФПТПЗП УЕУУЙС УФБОПЧЙФУС ОЕДЕКУФЧЙФЕМШОПК.
//:! c15:jsp:SessionObject.jsp
<%--Getting and setting session object values--%>
<html><body>
<H1>Session id: <%= session.getId() %></H1>
<H3><li>This session was created at
<%= session.getCreationTime() %></li></H1>
<H3><li>Old MaxInactiveInterval =
<%= session.getMaxInactiveInterval() %></li>
<% session.setMaxInactiveInterval(5); %>
<li>New MaxInactiveInterval=
<%= session.getMaxInactiveInterval() %></li>
</H3>
<H2>If the session object "My dog" is
still around, this value will be non-null:<H2>
<H3><li>Session value for "My dog" =
<%= session.getAttribute("My dog") %></li></H3>
<%-- Now add the session object "My dog" --%>
<% session.setAttribute("My dog",
new String("Ralph")); %>
<H1>My dog's name is
<%= session.getAttribute("My dog") %></H1>
<%-- See if "My dog" wanders to another form --%>
<FORM TYPE=POST ACTION=SessionObject2.jsp>
<INPUT TYPE=submit name=submit
Value="Invalidate"></FORM>
<FORM TYPE=POST ACTION=SessionObject3.jsp>
<INPUT TYPE=submit name=submit
Value="Keep Around"></FORM>
</body></html>
///:~
пВЯЕЛФ session УХЭЕУФЧХЕФ РП ХНПМЮБОЙА, ФБЛ ЮФП ПО ДПУФХРЕО ВЕЪ ОБРЙУБОЙС ДПРПМОЙФЕМШОПЗП ЛПДБ. чЩЪПЧЩ getID( ), getCreationTime( ) Й getMaxInactiveInterval( ) ЙУРПМШЪХАФУС ДМС ПФПВТБЦЕОЙС ЙОЖПТНБГЙЙ ПВ ПВЯЕЛФЕ УЕУУЙЙ.
лПЗДБ ЧЩ Ч РЕТЧЩК РПМХЮЙФЕ ЬФХ УЕУУЙА, ЧЩ ХЧЙДЙФЕ, ЮФП MaxInactiveInterval ТБЧЕО, ОБРТЙНЕТ, 1800 УЕЛХОД (30 НЙОХФ). ьФП ЪБЧЙУЙФ ПФ УРПУПВБ ЛПОЖЙЗХТБГЙЙ ЧБЫЕЗП ЛПОФЕКОЕТБ JSP/УЕТЧМЕФПЧ. MaxInactiveInterval УПЛТБЭБЕФУС ДП 5 УЕЛХОД, ЮФПВЩ УДЕМБФШ РТЕДНЕФ ЙЪХЮЕОЙС ВПМЕЕ ЙОФЕТЕУОЩН. еУМЙ ЧЩ ПВОПЧЙФЕ УФТБОЙГХ ДП ФПЗП, ЛБЛ ЪБЛПОЮЙФУС ЙОФЕТЧБМ Ч 5 УЕЛХОД, ФП ЧЩ ХЧЙДЙФЕ:
Session value for "My dog" = Ralph
оП ЕУМЙ ЧЩ РТПНЕДМЙФЕ, “Ralph” УФБОЕФ ТБЧЕО null.
юФПВЩ РПУНПФТЕФШ ЛБЛ ЙОЖПТНБГЙС П УЕУУЙЙ НПЦЕФ ВЩФШ РЕТЕДБОБ ОБ ДТХЗЙЕ УФТБОЙГЩ, Б ФБЛЦЕ РПУНПФТЕФШ ЬЖЖЕЛФ ОЕДЕКУФЧЙФЕМШОПУФЙ ПВЯЕЛФБ УЕУУЙЙ, РТПУФП ДБКФЕ ЕНХ ХУФБТЕФШ, ВХДХФ УПЪДБОЩ ДЧБ ДТХЗЙИ JSP. рЕТЧЩК ЙЪ ОЙИ (НПЦЕФ ВЩФШ РПМХЮЕО РТЙ ОБЦБФЙЙ ЛОПРЛЙ “invalidate” Ч SessionObject.jsp) ЮЙФБЕФ ЙОЖПТНБГЙА П УЕУУЙЙ, Б ЪБФЕН СЧОП ДЕМБЕФ ЕЕ ОЕДЕКУФЧЙФЕМШОПК:
//:! c15:jsp:SessionObject2.jsp
<%--The session object carries through--%>
<html><body>
<H1>Session id: <%= session.getId() %></H1>
<H1>Session value for "My dog"
<%= session.getValue("My dog") %></H1>
<% session.invalidate(); %>
</body></html>
///:~
юФПВЩ РПЬЛУРЕТЙНЕОФЙТПЧБФШ У ЬФЙН, ПВОПЧЙФЕ SessionObject.jsp, ЪБФЕН УТБЪХ ОБЦНЙФЕ ОБ ЛОПРЛХ “invalidate”, ЮФПВЩ РПУНПФТЕФШ SessionObject2.jsp. ч ЬФПН УМХЮБЕ ЧЩ ЧУЕ ЕЭЕ ХЧЙДЙФЕ “Ralph”, Ч РТПФЙЧПН УМХЮБЕ (РПУМЕ ФПЗП, ЛБЛ РТПКДЕФ 5-ФЙ УЕЛХОДОЩК ЙОФЕТЧБМ), ПВОПЧЙФЕ SessionObject2.jsp, ЮФПВЩ ХЧЙДЕФШ, ЮФП УЕУУЙС ДЕКУФЧЙФЕМШОП УФББ ОЕДЕКУФЧЙФЕМШОПК, Б “Ralph” ЙУЮЕЪ.
еУМЙ ЧЩ ЧЕТОЕФЕУШ Л SessionObject.jsp, ПВОПЧЙФЕ УФТБОЙЮЛХ ФБЛ, ЮФПВЩ РТПЫЕМ 5-ФЙ УЕЛХОДОЩК ЙОФЕТЧБМ, ЪБФЕН ОБЦНЙФЕ ЛОПРЛХ “Keep Around”, ЧЩ РПМХЮЙФЕ УМЕДХАЭХА УФТБОЙГХ, SessionObject3.jsp, ЛПФПТБС ое ДЕМБЕФ УЕУУЙА ОЕДЕКУФЧЙФЕМШОПК:
//:! c15:jsp:SessionObject3.jsp
<%--The session object carries through--%>
<html><body>
<H1>Session id: <%= session.getId() %></H1>
<H1>Session value for "My dog"
<%= session.getValue("My dog") %></H1>
<FORM TYPE=POST ACTION=SessionObject.jsp>
<INPUT TYPE=submit name=submit Value="Return">
</FORM>
</body></html>
///:~
рПУЛПМШЛХ ЬФБ УФТБОЙГБ ОЕ ДЕМБЕФ УЕУУЙА ОЕДЕКУФЧЙФЕМШОПК, “Ralph” ВХДЕФ ПУФБЧБФШУС ДП ФЕИ РПТ, РПЛБ ЧЩ ВХДЕФЕ ЧЩРПМОСФШ ПВОПЧМЕОЙС ДП ПЛПОЮБОЙС 5 УЕЛХОДОПЗП ЙОФЕТЧБМБ. ьФП РПИПЦЕ ОБ “Tomagotchi” — РПЛБ ЧЩ ЙЗТБЕФЕ У “Ralph”, ПО ВХДЕФ ФБН, Ч РТПФЙЧОПН УМХЮБЕ ПО ЙУЮЕЪОЕФ.
Cookies ВЩМЙ ЧЧЕДЕОЩ Й РТЕДЩДХЭЕН ТБЪДЕМЕ, РПУЧСЭЕООПН УЕТЧМЕФБН. пРСФШ ФБЛЙ, ЛТБФЛПУФШ JSP ДЕМБЕФ ТБВПФХ У cookies ПЮЕОШ РТПУФПК, ЮЕН РТЙ ЙУРПМШЪПЧБОЙЙ УЕТЧМЕФПЧ. уМЕДХАЭЙК РТЙНЕТ РПЛБЪЩЧБЕФ ЬФП, РПМХЮБС cookies, ЛПФПТЩЕ РТЙИПДСФ У ЪБРТПУПН, ЮЙФБАФ Й ЙЪНЕОСАФ ЙИ НБЛУЙНБМШОЩК ЧПЪТБУФ (ДБФХ ХУФБТЕЧБОЙС) Й РТЙУПЕДЙОСАФ ОПЧЩК cookie, ДМС РПНЕЭЕОЙС Ч ПФЧЕФ:
//:! c15:jsp:Cookies.jsp
<%--This program has different behaviors under
different browsers! --%>
<html><body>
<H1>Session id: <%= session.getId() %></H1>
<%
Cookie[] cookies = request.getCookies();
for(int i = 0; i < cookies.length; i++) { %>
Cookie name: <%= cookies[i].getName() %> <br>
value: <%= cookies[i].getValue() %><br>
Old max age in seconds:
<%= cookies[i].getMaxAge() %><br>
<% cookies[i].setMaxAge(5); %>
New max age in seconds:
<%= cookies[i].getMaxAge() %><br>
<% } %>
<%! int count = 0; int dcount = 0; %>
<% response.addCookie(new Cookie(
"Bob" + count++, "Dog" + dcount++)); %>
</body></html>
///:~
фБЛ ЛБЛ ЛБЦДЩК ВТПХЪЕТ ИТБОЙФ УЧПЙ cookies РП-УЧПЕНХin, ЧЩ НПЦЕФЕ ЧЙДЕФШ ТБЪОПЕ РПЧЕДЕОЙЕ Х ТБЪОЩИ ВТПХЪЕТПЧ (ОЕ ХФЧЕТЦДБА ФПЮОП, ФП ЬФП НПЦЕФ ВЩФШ ОЕЛПФПТЩН ПЫЙВЛБН, ЛПФПТЩЕ НПЗХФ ВЩФШ ХЦЕ ХУФТБОЕОЩ Ч ПФ НПНЕОФ, ЛПЗДБ ЧЩ ЮЙФБЕФЕ ЬФП). фБЛЦЕ ЧЩ НПЦЕФЕ РПМХЮЙФШ ТБЪМЙЮОЩЕ ТЕЪХМШФБФЩ, ЕУМЙ ЧЩ ЪБЛТПЕФЕ ВТПХЪЕТ Й ЪБРХУФЙФЕ ЕЗП УОПЧБ, ЙМЙ РПУЕФЙФЕ ДТХЗПК УБКФ Й ЧЕТОЕФЕУШ Л Cookies.jsp. пВТБФЙФЕ, ЮФП ЙУРПМШЪПЧБОЙЕ ПВЯЕЛФБ УЕУУЙК МХЮЫЙК РПДИПД, ЮЕН РТСНПЕ ЙУРПМШЪПЧБОЙЕ cookies.
рПУМЕ ПФПВТБЦЕОЙС ЙДЕОФЙЖЙЛБФПТБ УЕУУЙК, ПФПВТБЦБЕФУС ЛБЦДЩК cookie ЙЪ НБУУЙЧБ cookies, РТЙЫЕДЫЙК У ПВЯЕЛФПН request, ОБТСДХ У ЕЗП НБЛУЙНБМШОЩН ЧПЪТПУФПН. нБЛУЙНБМШОЩК ЧПЪТБУФ НЕОСЕФУС Й ПФПВТБЦБЕФУС ЧОПЧШ ДМС РТПЧЕТЛЙ ОПЧПЗП ЪОБЮЕОЙС, ЪБФЕН ОПЧЩК cookie ДПВБЧМСЕФУС Ч ПФЧЕФ. пДОБЛП ЧБЫ ВТПХЪЕТ НПЦЕФ ЙЗОПТЙТПЧБФШ НБЛУЙНБМШОЩК ЧПЪТБУФ, РПЙЗТБЧЫЙУШ У ЬФПК РТПЗТБННПК Й ЙЪНЕОСС ЪОБЮЕОЙЕ ЧПЪТБУФБ НПЦОП ХЧЙДЕФШ РПЧЕДЕОЙЕ ТБЪМЙЮОЩИ ВТПХЪЕТПЧ.
ьФПФ ТБЪДЕМ МЙЫШ ЛПТПФЛП ТБУУЛБЪЩЧБЕФУС П JSP, ОП ДБЦЕ У ФЕН, ЮФП ТБУУЛБЪБОП ЪДЕУШ (ЧНЕУФЕ У ФЕНЙ ЪОБОЙСНЙ, ЛПФПТЩЕ ЧЩ РПМХЮЙМЙ П Java Ч ПУФБЧЫЕКУС ЮБУФЙ ЛОЙЗЙ, УПЧНЕУФП У ФЕН, ЮФП ЧЩ УБНЙ ЪОБЕФЕ ПВ HTML) ЧЩ НПЦЕФЕ ОБЮБФШ РЙУБФШ ДПУФБФПЮОП УМПЦОЩЕ Web УФТБОЙГЩ У РПНПЭША JSP. уЙОФБЛУЙУ JSP УРЕГЙБМШОП ОЕ УРТСФБО ЗМХВПЛП Й ОЕ УМПЦЕО, ФБЛ ЮФП ЕУМЙ ЧЩ РПОСМЙ ЮФП РПЛБЪБОП Ч ЬФПН ТБЪДЕМЕ, ЧЩ ЗПФПЧЩ Л РТПДХЛФЙЧОПК ТБВПФЕ У JSP. чЩ НПЦЕФЕ ОБКФЙ ВПМЕЕ ОПЧХА ЙОЖПТНБГЙА ЧП ЧОПЧШ ЧЩЫЕЫЙИ ЛОЙЗБИ РП УЕТЧМЕФБН ЙМЙ ОБ java.sun.com.
пУПВЕООП ИПТПЫП ЙНЕФШ РПДДЕТЦЛХ JSP ДБЦЕ ЕУМЙ ЧБЫЕК ГЕМША СЧМСЕФУС ТБЪТБВПФЛБ УЕТЧМЕФПЧ. чЩ ПВОБТХЦЙФЕ, ЮФП ЕУМЙ Х ЧБУ ЕУФШ ЧПРТПУЩ П РПЧЕДЕОЙЙ УЕТЧМЕФБ Ч ВХДХАЭЕН, ФП МЕЗЛП Й РТПУФП ОБРЙУБФШ ФЕУФПЧХА JSP РТПЗТБННХ, ПФЧЕЮБАЭХА ОБ ЬФПФ ЧПРТПУ. юБУФШ ЧЩЗПДЩ УПУФПЙФ Ч ФПН, ЮФП ОХЦОП РЙУБФШ НЕОШЫЕ ЛПДБ Й НПЦОП УНЕЫЙЧБФШ ПФПВТБЦБЕНЩК HTML ЛПД У Java ЛПДПН, ОП ТЩЮБЗЙ ХРТБЧМЕОЙС УФБОПЧСФУС ПУПВЕООП ПЮЕЧЙДОЩНЙ, ЛПЗДБ JSP ЛПОФЕКОЕТ ПВТБВБФЩЧБЕФ ЧУА РЕТЕЛПНРЙМСГЙА Й РЕТЕЪБЗТХЪЛХ JSP ЧНЕУФП ЧБУ, ЛПЗДБ ВЩ ЧЩ ОЕ ЙЪНЕОЙМЙ ЙУИПДОЩК ЛПД.
оЕДПУФБФПЛ JSP Ч ФПН, ЮФП ДМС УПЪДБОЙС JSP ФТЕВХЕФУС ВПМЕЕ ЧЩУПЛЙК ХТПЧЕОШ ХНЕОЙС, ЮЕН ХТПЧЕОШ РТПУФПЗП Java РТПЗТБННЙУФБ ЙМЙ РТПУФПЗП Web НБУФЕТБ. лТПНЕ ФПЗП, ПФМБДЛБ JSP УФТБОЙГ У ПЫЙВЛБНЙ ОЕ ФБЛ МЕЗЛБ, ЛБЛ ПФМБДЛБ Java РТПЗТБНН, ФБЛ ЛБЛ (Ч ОБУФПСЭЕЕ ЧТЕНС) УППВЭЕОЙС ПВ ПЫЙВЛБИ УМЙЫЛПН ОЕЧТБЪХНЙФЕМШОЩ. ьФП ДПМЦОП ЙЪНЕОЙФШУС РТЙ ХМХЮЫЕОЙЙ УТЕДЩ ТБЪТБВПФЛЙ, ОП НЩ НПЦЕН ФБЛЦЕ ОБКФЙ ДТХЗХА ФЕИОПМПЗЙА, ОБДУФТПЕОХА ОБД Java Й Web, ЛПФПТБС ВХДЕФ МХЮЫЕ БДБРФЙТПЧБОБ Ч ЪОБОЙСН ДЙЪБКОЕТБ Web УБКФПЧ.
фТБДЙГЙПООЩК РПДИПД Л ЧЩРПМОЕОЙА ЛПДБ ОБ МАВПК НБЫЙОЕ РП УЕФЙ УВЙЧБМ У ФПМЛХ , Б ФБЛ ЦЕ ВЩМ ХФПНЙФЕМЕО Й РПДЧЕТЦЕО ПЫЙВЛБН РТЙ ТЕБМЙЪБГЙЙ. мХЮЫЙК УРПУПВ РТЕДУФБЧЙФШ ЬФХ РТПВМЕННХ - ЬФП ДХНБФШ, ЮФП ЛБЛПК-ФП ПВЯЕЛФ ЦЙЧЕФ ОБ ДТХЗПК НБЫЙОЕ Й ЮФП ЧЩ НПЦЕФЕ РПУЩМБФШ УППВЭЕОЙС ХДБМЕООПНХ ПВЯЕЛФХ Й РПМХЮБФШ ТЕЪХМШФБФ, ВХДФП ВЩ ЬФПФ ПВЯЕЛФ ЦЙЧЕФ ОБ ЧБЫЕК НБЫЙОЕ. зПЧПТС РТПУФЩН СЪЩЛПН, ЬФП Ч ФПЮОПУФЙ ФП, ЮФП РПЪЧПМСЕФ ДЕМБФШ хДБМЕООЩК ЧЩЪПЧ НЕФПДПЧ (Remote Method Invocation (RMI) Ч Java. ьФПФ ТБЪДЕМ РПЛБЪЩЧБЕФ ЫБЗЙ, ОЕПВИПДЙНЩЕ ДМС УПЪДБОЙС ЧБЫЙИ УПВУФЧЕООЩИ RMI.
RMI ДЕМБЕФ ФЩЦЕМЩН ЙУРПМШЪПЧБОЙЕ ЙОФЕТЖЕКУПЧ. лПЗДБ ЧЩ ИПФЙФЕ УПЪДБФШ ХДБМЕООЩК ПВЯЕЛФ, ЧЩ РПНЕЮБЕФЕ, ЮФП МЕЦБЭХА Ч ПУОПЧЕ ТБЕМЙЪБГЙА ОХЦОП РЕТЕДБЧБФШ ЮЕТЕЪ ЙОФЕТЖЕКУ. фБЛЙН ПВТБЪПН, ЛПЗДБ ЛМЙЕОФ РПМХЮБЕФ УУЩМЛХ ОБ ХДБМЕООЩК ПВЯЕЛФ, ОБ УБНПН ДЕМЕ ПО РПМХЮБЕФЕ УУЩМЛХ ОБ ЙОФЕТЖЕКУ, ЛПФПТЩК ЧЩРПМОСЕФ УПЕДЙОЕОЙЕ У ПРТЕДЕМЕООЩНХ НЕУФПН ЛПДБ,ПВЭБАЭЙНУС РП УЕФЙ. оП ЧЩ ОЕ ЪБВПФЙФЕУШ ПВ ЬФПН, ЧЩ РТПУФП РПУЩМБЕФЕ УППВЭЕОЙС ЮЕТЕЪ УУЩМЛХ ОБ ЙОФЕТЖЕКУ.
лПЗДБ ЧЩ УПЪДБЕФЕ ХДБМЕООЩК ЙОФЕТЖЕКУ, ЧЩ ДПМЦОЩ УМЕДПЧБФШ УМЕДХАЭЕК ЙУОФТХЛГЙЙ:
оЙЦЕ РТЙЧЕДЕО РТПУФПК ХДБМЕООЩК ЙОФЕТЖЕКУ, РТЕДУФБЧМСАЭЙК УЕТЧЙУ ФПЮОПЗП ЧТЕНЕОЙ:
//: c15:rmi:PerfectTimeI.java
// хДБМЕООЩК ЙОФЕТЖЕКУ PerfectTime.
package c15.rmi;
import java.rmi.*;
interface PerfectTimeI extends Remote {
long getPerfectTime() throws RemoteException;
} ///:~
пО ЧЩЗМСДЙФ ЛБЛ МАВПК ДТХЗПК ЙОФЕТЖЕКУ, ЪБ ЙУЛМАЮЕОЙЕН ФПЗП, ЮФП ТБУЫЙТСЕФ Remote Й ЧУЕ ЕЗП НЕФПДЩ ЧЩВТБУЩЧБАФ RemoteException. рПНОЙФЕ, ЮФП interface Й ЧУЕ ЕЗП НЕФПДЩ БЧФПНБФЙЮЕУЛЙ УФБОПЧСФУС public.
уЕТЧЕТ ДПМЦЕО УПДЕТЦБФШ ЛМБУУ, ЛПФПТЩК ТБУЫЙТСЕФ UnicastRemoteObject Й ТЕБМЙЪХЕФ ХДБМЕООЩК ЙОФЕТЖЕКУ. ьФПФ ЛМБУУ ФБЛЦЕ НПЦЕФ ЙНЕФШ ДТХЗЙЕ НЕФПДЩ, ОП ДМС ЛМЙЕОФБ ДПУФХРОЩ ФПМШЛП НЕФПДЩ ХДБМЕООПЗП ЙОФЕТЖЕКУБ, ФБЛ ЛБЛ ЛМЙЕОФ РПМХЮБЕФ ФПШЛП УУЩМЛХ ОБ ЙОФЕТЖЕКУ, Б ОЕ ОБ ЛМБУУ, ЛПФПТЩК ЕЗП ТЕБМЙЪХЕФ.
чЩ ДПМЦОЩ СЧОП ПРТЕДЕМЙФШ ЛПОУФТХЛФПТ ДМС ХДБМЕОПЗП ПВЯЕЛФБ, ДБЦЕ ЕУМЙ ЧЩ ПРТЕДЕМСЕФЕ ФПМШЛП ЛПОУФТХЛФПТ РП ХНПМЮБОЙА, ЛПФПТЩК ЧЩЪЩЧБЕФ ЛПОУФТХЛФПТ ВБЪПЧПЗП ЛМБУУБ. чЩ ДПМЦОЩ ОБРЙУБФШ ЕЗП, ФБЛ ЛБЛ ПО ДПМЦЕО ЧЩВТБУЩЧБФШ RemoteException.
оЙЦЕ РТЙЧЕДЕОБ ТЕБМЙЪБГЙС ХДБМЕООПЗП ЙОФЕТЖЕКУБ PerfectTimeI:
//: c15:rmi:PerfectTime.java
// тЕБМЙЪБГЙС ХДБМЕООПЗП ПВЯЕЛФБ PerfectTime.
package c15.rmi;
import java.rmi.*;
import java.rmi.server.*;
import java.rmi.registry.*;
import java.net.*;
public class PerfectTime
extends UnicastRemoteObject
implements PerfectTimeI {
// тЕБМЙЪБГЙС ЙОФЕТЖЕКУБ:
public long getPerfectTime()
throws RemoteException {
return System.currentTimeMillis();
}
// дПМЦОБ ВЩФШ ТЕБМЙЪБГЙС ЛПОУФТХЛФПТБ
// ДМС ЧЩВТБУЩЧБОЙС RemoteException:
public PerfectTime() throws RemoteException {
// super(); // чЩЪЩЧБЕФУС БЧФПНБФЙЮЕУЛЙ
}
// тЕЗЙУФТБГЙС ДМС ПВУМХЦЙЧБОЙС RMI. чЩВТБУЩЧБЕФ
// ЙУЛМАЮЕОЙС ОБ ЛПОУПМШ.
public static void main(String[] args)
throws Exception {
System.setSecurityManager(
new RMISecurityManager());
PerfectTime pt = new PerfectTime();
Naming.bind(
"//peppy:2005/PerfectTime", pt);
System.out.println("Ready to do time");
}
} ///:~
ч ЬФПН РТЙНЕТЕ main( ) ПВТБВБФЩЧБЕФ ЧУЕ ДЕФБМЙ ХУФБОПЧЛЙ УЕТЧЕТБ. лПЗДБ ЧЩ ПВУМХЦЙЧБЕФЕ RMI ПВЯЕЛФ, Ч ПРТЕДЕМЕООПН НЕУФЕ ЧБЫЕК РТПЗТБННЩ ЧЩ ДПМЦОЩ:
ч ЬФПН РТЙНЕТЕ ЧЩ ЧЙДЙФЕ ЧЩЪПЧ УФБФЙЮЕУЛПЗП НЕФПДБ Naming.bind( ). пДОБЛП ЬФПФ ЧЩЪПЧ ФТЕВХЕФ, ЮФПВЩ ТЕЗЙУФТБГЙС ВЩМБ ЪБРХЭЕОБ ПФДЕМОЩН РТПГЕУУПН ОБ ЧБЫЕН ЛПНРШАФЕТЕ. йНС УЕТЧЕТБ ТЕЗЙУФТБГЙЙ - ЬФП rmiregistry, Й РПД 32-ВЙФОПК Windows ЧЩ ЗПЧПТЙФЕ:
start rmiregistry
ДМС ЪБРХУЛБ Ч ЖПОПЧПН ТЕЦЙНЕ. рПД Unix ЬФБ ЛПНБОДБ ЧЩЗМСДЙФ:
rmiregistry &
лБЛ Й НОПЗЙЕ ДТХЗЙЕ УЕФЕЧЩЕ РТПЗТБННЩ, rmiregistry ПВТБЭБЕФУС РП IP БДТЕУХ НБЫЙОЩ, ОБ ЛПФПТПК ПОБ ХУФБОПЧМЕОБ, ОП ПОБ ФБЛЦЕ УМХЫБЕФ РПТФ. еУМЙ ЧЩ ЧЩЪПЧЙФЕ rmiregistry ЛБЛ РПЛБЪБОП ЧЩЫЕ, ВЕЪ БТЗХНЕОФПЧ, ВХДЕФ ЙУРПМШЪПЧБО РПТФ РП ХНПМЮБОЙА 1099. еУМЙ ЧЩ ИПФЙФЕ ЙУРПМШЪПЧБФШ ДТХЗПК РПТФ, ЧЩ ДПВБЧМСЕФЕ БТЗХНЕОФ Ч ЛПНБОДОХА УФТПЛХ, ХЛБЪЩЧБАЭЙК РПТФ. уМЕДХАЭЙК РТЙНЕТ ХУФБОБЧМЙЧБЕФ РПТФ 2005, ФБЛ ЮФП rmiregistry РПД ХРТБЧМЕОЙЕН 32-ВЙФОПК Windows ДПМЦОБ ЪБРХУЛБФШУС ФБЛ:
start rmiregistry 2005
Б РПДUnix:
rmiregistry 2005 &
йОЖПТНБГЙ П РПТФЕ ФБЛЦЕ ДПМЦОБ РЕТЕДБЧБФШУС Ч ЛПНБОДЕ bind( ), ОБТСДХ У IP БДТЕУПН НБЫЙОЩ, ЗДЕ ТБУРПМБЗБЕФУС ТЕЗЙУФТБГЙС. оП ЬФП НПЦЕФ ЧЩСЧЙФШ ПЗПТЮЙФЕМШОХА РТПВМЕНХ, ЕУМЙ ЧЩ ИПФЙФЕ РТПЧЕТСФШ RMI РТПЗТБННЩ МПЛБМШОП, ЛБЛ РТПЧЕТСМЙУШ ЧУЕ РТПЗТБННЩ ДП ЬФПК ЗМБЧЩ. ч ЧЩРХУЛЕ JDK 1.1.1, ЕУФШ ГЕМБС УЧСЪЛБ РТПВМЕН:[76]
еУМЙ ХЮЕУФШ ЧУЕ ЬФП, ЛПНБОДБ bind( ) РТЙОЙНБЕФ ЧЙД:
Naming.bind("//peppy:2005/PerfectTime", pt);
еУМЙ ЧЩ ЙУРПМШЪХЕФЕ РПТФ РП ХНПМЮБОЙА 1099, ЧБН ОЕ ОХЦОП ХЛБЪЩЧБФШ РПТФ, ФБЛ ЮФП ЧЩ НПЦЕФЕ РТПУФП УЛБЪБФШ:
Naming.bind("//peppy/PerfectTime", pt);
чЩ НПЦЕФЕ ЧЩРПМОЙФШ МПЛБМШОХА РТПЧЕТЛХ ПУФБЧЙЧ Ч РПЛПЕ IP БДТЕУ, Б ЙУРПМШЪПЧБФШ ФПМШЛП ЙДЕОФЙЖЙЛБФПТ:
Naming.bind("PerfectTime", pt);
йНС УЕТЧЙУБ ЪДЕУШ РТПЙЪЧПМШОП. ч ДБООПН УМХЮБЕ PerfectTime ЧЩВТБОП РТПУФП ЛБЛ ЙНС ЛМБУУБ, ОП ЧЩ НПЦЕФЕ ОБЪЧБФШ ФБЛ, ЛБЛ ЪБИПЙФЕ. чБЦОП, ЮФПВЩ ЬФП ВЩМП ХОЙЛБМШОПЕ ЙНС ТЕЗЙУФТБГЙЙ, ЮФПВЩ ЛМЙЕОФ ЪОБМ, ЛПЗДБ ВХДЕФ ЙУЛБФШ ЮФП РТПЙЪЧПДЙФ ХДБМЕООЩЕ ПВЯЕЛФЩ. еУМЙ ЙНС ХЦЕ ЪБТЕЗЙУФТЙТПЧБОП, ЧЩ РПМХЮЙФЕ AlreadyBoundException. юФПВЩ РТЕДПФЧТБФЙФШ ЬФП, ЧЩ ЧУЕЗДБ НПЦЕФЕ ЙУРПМШЪПЧБФШ rebind( ) ЧНЕУФП bind( ), ФБЛ ЛБЛ rebind( ) МЙВП ДПВБЧМСЕФ ОПЧЩК ЬМЕНЕОФ, МЙВП ЪБНЕОСЕФ ХЦЕ УХЭЕУФЧХАЭЙК.
дБЦЕ РПУМЕ ЪБЧЕТЫЕОЙС ТБВПФЩ main( ), ЧБЫ ПВЯЕЛФ ВХДЕФ ПУФБЧБФШУС УПЪДБООЩН Й ЪБТЕЗЙУФТЙТПЧБООЩН, ПЦЙДБС, ЮФП РТЙКДЕФ ЛМЙЕОФ Й ЧЩРПМОЙФ ЪБРТПУ. рПЛБ rmiregistry ПУФБЕФУС ЪБРХЭЕООЩН, Й ЧЩ ОЕ ЧЩЪПЧЙФЕ Naming.unbind( ) ОБ ЧБЫЕК НБЫЙОЕ, ПВЯЕЛФ ВХДЕФ ПУФБЧБФШУС ФБН. рП ЬФПК РТЙЮЙОЕ, ЛПЗДБ ЧЩ ТБЪТБВБФЩЧБЕФЕ ЧБЫ ЛПД, ЧБН ОЕПВИПДЙНП ЧЩЗТХЦБФШ rmiregistry Й РЕТЕЪБРХУЛБФШ ЕЗП, ЛПЗДБ УЛПНРЙМЙТХЕФЕ ОПЧХА ЧЕТУЙА ЧБЫЕЗП ХДБМЕООПЗП ПВЯЕЛФБ.
чБН ОЕ ПВСЪБФЕМШОП ЪБРХУЛБФШ rmiregistry ЛБЛ ЧОЕЫОЙК РТПГЕУУ. еУМЙ ЧЩ ЪОБЕФЕ, ЮФП ФПМШЛП ЧБЫЕ РТЙМПЦЕОЙЕ ЙУРПМШЪХЕФ ТЕЗЙУФТБГЙА, ЧЩ НПЦЕФЕ ЪБЗТХЪЙФШ ЕЕ ЧОХФТЙ ЧБЫЕК РТПЗТБННЩ У РПНПЭША УФТПЛЙ:
LocateRegistry.createRegistry(2005);
лБЛ Й ТБОШЫЕ, 2005 - ЬФП ОПНЕТ РПТФБ, ЛПФПТЩК НЩ ЙУРПМШЪПЧБМЙ Ч ЬФПН РТЙНЕТЕ. ьФП ЬЛЧЙЧБМЕОФОП ЪБРХУЛХ rmiregistry 2005 ЙЪ ЛПНБОДОПК УФТПЛЙ, ОП ЮБУФП ЬФПФ УРПУПВ СЧМСЕФУС ВПМЕЕ РПДИПДСЭЙН РТЙ ТБЪТБВПФЛЕ RMI ЛПДБ, ФБЛ ЛБЛ ЬФП УОЦБЕФ ЮЙУМП ОЕПВИПДЙНЩИ ДЕКУФЧЙК РТЙ ЪБРХУЛЕ Й ПУФБОПЧЛЕ ТЕЗЙУФТБГЙЙ рПУМЕ ФПЗП, ЛБЛ ЧЩ ЧЩРПМОЙФЕ ЬФПФ ЛПД, ЧЩ НПЦЕФЕ ЧЩЪЧБФШ bind( ), ЙУРПМШЪХС Naming, ЛБЛ Й ТБОЕЕ.
еУМЙ ЧЩ ПФЛПНРЙМЙТПЧБМЙ Й ЪБРХУФЙМЙ PerfectTime.java, ПОП ОЕ ВХДЕФ ТБВПФБФШ, ДБЦЕ ЕУМЙ ЧЩ РТБЧЙМШОП ЪБРХУФЙМЙ rmiregistry. ьФП РТПЙУИПДЙФ РПФПНХ, ЮФП ТБВПЮЕЕ РТПУФТБОУФЧП ДМС RMI ЕЭЕ ОЕ УПЪДБОП. чЩ ДПМЦОЩ УОБЮБМБ УПЪДБФШ СЛПТС Й УЛЕМЕФЩ, ЛПФПТЩЕ ПВЕУРЕЮБФ ТБВПФХ УЕФЕЧПЗП УПЕДЙОЕОЙС Й РПЪЧПМЙФ ЧБН ДЕМБФШ ЧЙД, ЮФП ХДБМЕООЩК - ЬФП РТПУФП ДПЛБМШОЩК ПВЯЕЛФ ОБ ЧБЫЕК НБЫЙОЕ.
фП, ЮФП РТПЙУИПДЙФ ЪБ УГЕОПК - ПЮЕОШ УМПЦОП. мАВПК ПВЯЕЛФ, ЛПФПТЩК ЧЩ РЕТЕДБЕФЕ ЙМЙ РПМХЮБЕФЕ ЙЪ ХДБМЕОПЗП ПВЯЕЛФБ ДПМЦЕО ТЕБМЙЪПЧЩЧБФШ(implement) Serializable (ЕУМЙ ЧЩ ИПФЙФЕ РЕТЕДБЧБФШ ХДБМЕООЩЕ УУЩМЛЙ ЧНЕУФП ГЕМЩИ ПВЯЕЛФПЧ, БТЗХНЕОФЩ ПВЯЕЛФПЧ НПЗХФ ТЕБМЙЪПЧЩЧБФШ (implement) Remote), ФБЛ ЮФП ЧЩ НПЦЕФЕ РТЕДУФБЧЙФШ, ЮФП СЛПТС Й УЛЕМЕФЩ БЧФПНБФЙЮЕУЛЙ ЧЩРПМОСАФ УЕТЙБМЙЪБГЙА Й ДЕУЕТЙБМЙЪБГЙА, Б ФБЛ ЦЕ “РЕТЕДБАФ РП ПЮЕТЕДЙ” ЧУЕ БТЗХНЕОФЩ РП УЕФЙ Й ЧПЪЧТБЭБАФ ТЕЪХМШФБФ. л УЮБУФША, ЧБН ОЕ ОХЦОП ЪОБФШ ЧУЕЗП ЬФПЗП, ОП ЧЩ ДПМЦОЩ ДЕМБФШ СЛПТС Й УЛЕМЕФЩ. ьФП РТПУФПК РТПГЕУУ: ЧЩ ЧЩЪЩЧБЕФЕ ЙОУФТХНЕОФ rmic ДМС ЧБЫЕЗП ПФЛПНРЙМЙТПЧБООПЗП ЛПДБ, Б ПО УПЪДБЕФ ОЕПВИПДЙНЩЕ ЖБКМЩ. фБЛ ЮФП ПФ ЧБУ ФТЕВХЕФУС ЧЛМАЮЙФШ ЕЭЕ ПДЙО ЫБЗ Ч РТПГЕУУ ЛПНРЙМСГЙЙ.
пДОБЛП ЙОУФТХНЕОФ rmic УРЕГЕЖЙЮЕО ПФОПУЙФЕМШОП packages classpath. PerfectTime.java ОБИПДЙФУС Ч РБЛЕФЕ c15.rmi, Й ДБЦЕ ЕУМЙ ЧЩ ЧЩЪПЧЙФЕ rmic Ч ФПН ЦЕ УБНПН ДЙТЕЛФПТЙ, Ч ЛПФПТПН ОБИПДЙФУС PerfectTime.class, rmic ОЕ ОБКДЕФ ЖБКМ, ФБЛ ЛБЛ ПО ЙЭЕФ classpath. фБЛ ЮФП ЧЩ ДПМЦОЩ ХЛБЪБФШ РХФШ Л ЛМБУУХ РТЙНЕТОП ФБЛ:
rmic c15.rmi.PerfectTime
чБН ОЕ ОХЦОП ВЩФШ Ч ДЙТЕЛФПТЙЙ, УПДЕТЦБЭЙН PerfectTime.class, ЛПЗДБ ЧЩ ЙУРПМОСЕФЕ ЬФХ ЛПНБОДХ, ОП ТЕЪХМШФБФ ВХДЕФ РПНЕЭЕО Ч ФЕЛХЭЙК ДЙТЕЛФПЙК.
еУМЙ ЪБРХУ rmic ЪБЧЕТЫЙФУС ХУРЕЫОП, ЧЩ ОБКДЕФЕ ДЧБ ОПЧЩИ ЛМБУУБ Ч ДТЕЛФПТЙЙ:
PerfectTime_Stub.class PerfectTime_Skel.class
УППФЧЕФУФЧХАЭЙИ СЛПТА Й УЛЕМЕФХ. фЕРЕТШ ЧЩ ЗПФПЧЩ ЪБРХУФЙФШ ПВЭЕОЙЕ ЛМЙЕОФБ У УЕТЧЕТПН.
зМБЧОБС ГЕМШ RMI УПУФПЙФ Ч ХРТБЭЕОЙЙ ЙУРПМШЪПЧБОЙС ХДБМЕООЩИ ПВЯЕЛФПЧ. чЩ ДПМЦОЩ УДЕМБФШ ФПМШЛП УБНХА ЧБЦОХА ЧЕЭШ Ч ЧБЫЕК ЛМЙЕОФУЛПК РТПЗТБННЕ: ЬФП РПЙУЛ Й РПМХЮЕОЙЕ ХДБМЕООПЗП ЙОФЕТЖЕКУБ У УЕТЧЕТБ. чП ЧУЕН ПУФБМШОПН - ЬФП ПВЩЮОПЕ РТПЗТБННЙТПЧБОЙЕ ОБ Java: РПУЩМЛБ УППВЭЕОЙК ПВЯЕЛФХ. оЙЦЕ РТЙЧЕДЕОБ РТПЗТБННБ, ЙУРПМШЪХАЭБС PerfectTime:
//: c15:rmi:DisplayPerfectTime.java
// йУРПМШПЧБОЙЕ ХДБМЕООПЗП ПВЯЕЛФБ PerfectTime.
package c15.rmi;
import java.rmi.*;
import java.rmi.registry.*;
public class DisplayPerfectTime {
public static void main(String[] args)
throws Exception {
System.setSecurityManager(
new RMISecurityManager());
PerfectTimeI t =
(PerfectTimeI)Naming.lookup(
"//peppy:2005/PerfectTime");
for(int i = 0; i < 10; i++)
System.out.println("Perfect time = " +
t.getPerfectTime());
}
} ///:~
уФТПЛБ ЙДЕОФЙЖЙЛБФПТБ ФБЛБС ЦЕ, ЛБЛ Й ФБ, ЮФП ЙУРПМШЪПЧБМБУШ РТЙ ТЕЗЙУФТБГЙЙ ПВЯЕЛФБ У РПНПЭША Naming, Б РЕТЧБС ЮБУФШ РТЕДУФБЧМСЕФ URL Й ОПНЕТ РПТФБ. фБЛ ЛБЛ ЧЩ ЙУРПМШЪХЕФЕ URL, ЧЩ НПЦЕФЕ ФБЛЦЕ ХЛБЪБФШ НБЫЙОХ Ч Internet.
фП, ЮФП ЧПЪЧТБЭБЕФУС ЙЪ Naming.lookup( ) ДПМЦОП ВЩФШ РТЕПВТБЪПЧБОП Л ХДБМЕООПНХ ЙОФЕТЖЕКУХ, Б ОЕ Л ЛМБУУХ. еУМЙ ЧЩ ВХДЙФЕ ЙУРПМШЪПЧБФШ ЛМБУУ, ЧЩ РПМХЮЙФЕ ЙУЛМАЮЕОЙЕ.
чЩ ЧЙЙФЕ ЧЩЪПЧ НЕФПДБ
t.getPerfectTime()
ФБЛ ЛБЛ ЧЩ ЙНЕЕФЕ УУЩМЛХ ОБ ХДБМЕООЩК ПВЯЕЛФ, ФП У ФПЮЛЙ ЪТЕОЙС РТПЗТБННЙТПЧБОЙС, ЬФП ОЕ ПФМЙЮБЕФУС ПФ ТБВПФЩ У МПЛБМШОЩН ПВЯЕЛФПН (У ПДОЙН ПФМЙЮЙЕН: ХДБМЕООЩЕ НЕФПДЩ ЧЩВТБУЩЧБАФ RemoteException).
ч ПЗТПНОЩИ ТБУРТЕДЕМЕООЩИ РТЙМПЦЕОЙСИ ЧЩ НПЦЕФЕ ВЩФШ ОЕХДПЧМЕФЧПТЕОЩ ЙЪМПЦЕООЩНЙ ЧЩЫЕ РПДИПДБНЙ. оБРТЙНЕТ, ЧБН НПЦЕФ РПОБДПВЙФШУС ЙОФЕТЖЕКУ У ХОБУМЕДПЧБООЩН ИТБОЙМЙЭЕН ДБООЩИ, ЙМЙ ЧБН НПЦЕФ РПОБДПВЙФШУС ХУМХЗБ ПФ УЕТЧЕТБ ПВЯЕЛФПЧ ОЕ ЪБЧЙУЙНП ПФ ЕЗП ЖЙЪЙЮЕУЛПЗП ТБУРПМПЦЕОЙС. фБЛЙЕ УЙФХБГЙЙ ФТЕВХАФ ОЕЛПФПТПЗП ТПДБ рТПГЕДХТЩ хДБМЕООПЗП чЩЪПЧБ (RPC), Й, ЧПЪНПЦОП, ОЕЪБЧЙУЙНПУФЙ ПФ СЪЩЛБ. ъДЕУШ НПЦЕФ РПНПЮШ CORBA.
CORBA - ЬФП ОЕ ПУПВЕООПУФШ СЪЩЛБ, ЬФП ФЕИОПМПЗЙС ЙОФЕЗТБГЙЙ. ьФП УРЕГЙЖЙЛБГЙС, ЛПФПТПК НПЗХФ УМЕДПЧБФШ РТПЙЪЧПДЙФЕМЙ ДМС ТЕБМЙЪБГЙЙ CORBA-УПЧНЕУФЙНЩИ ЙОФЕЗТЙТПЧБООЩИ РТПДХЛФПЧ. CORBA - ЬФП ПДОБ ЙЪ РПРЩФПЛ OMG ПРТЕДЕМЙФШ ТБВПЮЕЕ РТПУФТБОУФЧП ДМС ТБУРТЕДЕМЕООЩИ, ОЕЪБЧЙУСЭЙИ ПФ СЪЩЛБ УРПУПВОПУФЕК ПВЯЕЛФБ.
CORBA РТЕДМБЗБЕФ ЧПЪНПЦОПУФШ УПЪДБОЙС РТПГЕДХТЩ ХДБМЕООПЗП ЧЩЪПЧБ Java ПВЯЕЛФПЧ Й ОЕ Java ПВЯЕЛФПЧ ДМС ЧЪБЙНПДЕКУФЧЙС У УЙУФЕНПК ОБУМЕДПЧБОЙС ОЕЪБЧЙУСЭЙН ПФ ТБУРПМПЦЕОЙС УРПУПВПН. Java ДПВБЧМСЕФ РПДДЕТЦЛХ УЕФЙ Й ЧЕМЙЛПМЕРОЩК ПВЯЕЛФОП-ПЙЕОФЙТПЧБООЩК СЪЩЛ ДМС РПУФТПЕОЙС ЗТБЖЙЮЕУЛЙИ Й ОЕ ЗТБЖЙЮЕУЛЙИ РТЙМПЦЕОЙК. нПДЕМШОЩЕ ЛБТФЩ ПВЯЕЛФПЧ Java Й OMG ДПРПМОСАФ ДТХЗ ДТХЗБ, ОБРТЙНЕТ, Й Java, Й CORBA ТЕБМЙЪХАФ ЛПОГЕРГЙА ЙОФЕТЖЕКУПЧ Й НПДЕМШ УУЩМПЛ ОБ ПВЯЕЛФЩ.
уРЕГЙЖЙЛБГЙС ЧЪБЙНПДЕКУФЧЙС ПВЯЕЛФПЧ, ТБЪТБВПФБООБС OMG, ЮБУФП ОБЪЩЧБЕФУС, ЛБЛ Object Management Architecture (OMA). OMA ПРТЕДЕМСЕФ ДЧБ ЛПНРПОЕОФБ: нПДЕМШ сДТБ пВЯЕЛФБ (Core Object Model) Й бТИЙФЕЛФХТБ уУЩМПЛ OMA (OMA Reference Architecture). нПДЕМШ сДТБ пВЯЕЛФБ ХУФБОБЧМЙЧБЕФ ПУОПЧОХА ЛПОГЕРГЙА ПВЯЕЛФБ, ЙОФЕТЖЕКУБ, ПРЕТБГЙЙ Й Ф.Р. (CORBA СЧМСЕФУС ХМХЮЫЕОЙЕН Core Object Model.) бТИЙФЕЛФХТБ уУЩМПЛ OMA ПРТЕДЕМСЕФ МЕЦБЭХА Ч ПУОПЧЕ ЙЖТБУФТХЛФХТХ УЕТЧЙУПЧ Й НЕИБОЙЪНБ, ЛПФПТЩК РПЪЧПМСЕФ ПВЯЕЛФБН ЧЪБЙНПЦЕКУФЧПЧБФШ. бТИЙФЕЛФХТБ уУЩМПЛ OMA ЧЛМАЮБЕФ Object Request Broker (ORB), Object Services (ФБЛЦЕ ЙЪЧЕУФОЩК, ЛБЛ CORBA УЕТЧЙУ), Й ПВЭЙЕ УТЕДУФЧБ ПВУМХЦЙЧБОЙС.
ORB - ЬФП ЫЙОБ ЧЪБЙНПДЕКУФЧЙС, У РПНПЫША ЛПФПТПК ПВЯЕЛФЩ НПЗХФ ЧЩРПМОСФШ ЪБРТПУЩ ОБ ПВУМХЦЙЧБОЙС Л ДТХЗЙН ПВЯЕЛФБН, ОЕ ЪБЧЙУЙНП ПФ ЙИ ЖЙЪЙЮЕУЛПЗП РПМПЦЕОЙС. ьФП ЪОБЮЙФ, ЮФП ФП, ЮФП ЧЩЗМСДЙФ ЛБЛ ЧЩЪПЧ НЕФПДБ Ч ЛПДЕ ЛМЙЕОФБ ОБ УБНПН ДЕМЕ СЧМСЕФУС УМПЦОПК ПРЕТБГЙЕК. чП-РЕТЧЩИ, ДПМЦОП УХЭЕУФЧПЧБФШ УПЕДЙОЕОЙЕ У ПВЯЕЛФПН УЕТЧЕТБ, БДМС УПЪДБОЙС УПЕДЙОЕОЙС ORB ДПМЦЕО ЪОБФШ ЗДЕ ТБУРПМБЗБЕФУС ЛПД ТЕБМЙЪБГЙЙ УЕТЧЕТБ. рПУМЕ ХУФБОПЧМЕОЙС УПЕДЙОЕОЙС ДПМЦОЩ РЕТЕДБФШУС РП РПТСДЛХ БТЗХНЕОФЩ НЕФПДБ, Ф.Е. ЛПОЧЕТФЙТПЧБФШУС Ч ВЙОБТОЩК РПФПЛ Й РПУМБФШУС РП УЕФЙ. дТХЗБС ЙОЖПТНБГЙС, ЛПФПТБС ДПМЦОБ ВЩФШ РПУМБОБ УЕТЧЕТХ - ЬФП ЙНС НБЫЙОЩ, РТПГЕУУ УЕТЧЕТБ Й ЙДЕОФЙЖЙЛБФПТ УЕТЧЕТОПЗП ПВЯЕЛФБ ЧОХФТЙ РТПГЕУУБ. й ОБЛПОЕГ, ЬФБ ЙОЖПТНБГЙС РПУЩМБЕФУС У ЙУРПМШЪПЧБОЙЕН РТПФПЛПМБ ОЙЦОЕЗП ХТПЧОС, ЙОЖПТНБГЙС ДЕЛПДЙТХЕФУС ОБ УФПТПОЕ УЕТЧЕТБ Й ЧЩРПМОСЕФУС ЧЩЪПЧ РТПГЕДХТЩ. ORB РТСЮЕФ ЧУА ЬФХ УМПЦОПУФШ ПФ РТПЗТБННЙУФБ Й ДЕМБЕФ ТБВПФХ РПЮФЙ ФБЛПК ЦЕ РТПУФПК, ЛБЛ Й ЧЩЪПЧ НЕФПДБ МПЛБМШОПЗП ПВЯЕЛФБ.
оЕФ УРЕГЙЖЙЛБГЙЙ П ФПН, ЛБЛ ДПМЦОП ТЕБМЙЪПЧЩЧБФШУС СДТП ORB, ОП ДМС ПВЕУРЕЮЕОЙС УПЧНЕУФЙНПУФЙ У ТБЪМЙЮОЩНЙ РТПЙЪЧПДЙФЕМСНЙ ORB, OMG ПРТЕДЕМСЕФ ОБВПТ УЕТЧЙУПЧ, ЛПФПТЩЕ ДПУФХРОЩ ЮЕТЕЪ УФБОДБТФОЩЕ ЙОФЕТЖЕКУЩ.
CORBA РТЕДОБЪОБЮЕОБ ДМС ОЕЪБЧЙУЙНПУФЙ ПФ СЪЩЛПЧ: ПВЯЕЛФ ЛМЙЕОФБ НПЦЕФ ЧЩЪЩЧБФШ НЕФПДЩ УЕТЧЕТОПЗП ПВЯЕЛФБ ТБЪМЙЮОЩИ ЛМБУУПЧ, ОЕ ЪБЧЙУЙНП ПФ СЪЩЛБ ТЕБМЙЪБГЙЙ ЬФЙИ ПВЯЕЛФПЧ. лПОЕЮОП, ЛМЙЕОФУЛЙК ПВЯЕЛФ ДПМЦЕО ЪОБФШ ЙНЕОБ Й УЙЗОБФХТХ НЕФПДПЧ, РТБДПУФБЧМСЕНЩИ УЕТЧЕТОЩН ПВЯЕЛПН. дМС ЬФПЗП УДЕМБО IDL. CORBA IDL - ЬФП ОЕ ЪБЧЙУЙНЩК ПФ СЪЩЛПЧ УРПУПВ ХЛБЪБОЙС ФЙРПЧ ДБООЩИ, БФТЙВХФПЧ, ПРЕТБГЙК, ЙОФЕТЖЕКУПЧ Й НОПЗПЗП ДТХЗПЗП. уЙОФБЛУЙУ IDL УИПЦ У УЙОФБЛУЙУПН C++ ЙМЙ Java. уМЕДХАЭБС ФБВМЙГБ РПЛБЪЩЧБЕФ УППФЧЕФУФЧЙС НЕЦДХ ОЕЛПФПТЩНЙ ПВЭЙНЙ ЛПОГЕРГЙСНЙ ЬФЙИ ФТЕИ СЪЩЛПЧ, ЛПФПТЩЕ НПЦОП ХЛБЪБФШ Ч CORBA IDL:
|
CORBA IDL |
Java |
C++ |
|
Module |
Package |
Namespace |
|
Interface |
Interface |
Pure abstract class |
|
Method |
Method |
Member function |
лПОГЕРГЙС ОБУМЕДПЧБОЙС РПДДЕТЦЙЧБЕФУС ФБЛ ЦЕ, ЛБЛ ЙУРПШЪПЧБОЙЕ ПРЕТБФПТБ ДЧПЕФПЮЙЕ Ч C++. рТПЗБННЙУФ УПЪДБЕФ IDL ПРЙУБОЙЕ БФТЙВХФПЧ, НЕФПДПЧ Й ЙОФЕТЖЕКУПЧ, ЛПФПТЩЕ ТЕБМЙЪХАФУС Й ЙУРПМШЪХАФУС УЕТЧЕТПН Й ЛМЙЕОФПН. ъБФЕН IDL ЛПНРЙМЙТХЕФУС РТЕДПУФБЧМСЕНЩН РТПЙЪЧПДЙФЕМЕН IDL/Java ЛПНРЙМСФПТПН, ЮЙФБАЭЙН ЙУИПДОЩК IDL ЛПД Й ЗЕОЕТЙТХАЭЙН Java ЛПД.
IDL ЛПНРЙМСФПТ ПЮЕОШ РПМЕЪОЩК ЙОУФТХНЕОФ: ПО ОЕ РТПУФП ЗЕОЕТЙТХЕФ Java ЛПД, ЬЛЧЙЧБМЕОФОЩК IDL, ПО ФБЛЦЕ ЗЕОЕТЙТХЕФ ЛПД, ЛПФПТЩК ВХДЕФ ЙУРПМШЪПЧБФШУС РТЙ РЕТЕДБЮЕ БТЗХНЕОФПЧ НЕФПДПЧ Й РТЙ РТПЙЪЧЕДЕОЙЙ ХДБМЕООЩИ ЧЩЪПЧПЧ. ьПФ ЛПД, ОБЪЩЧБЕНЩК ЛПДПН СЛПТЕК Й УЛЕМЕФПЧ, ТБЪВЙФ ОБ ОЕУЛПМШЛП ЖБКМПЧ Java РТПЗТБННЩ, Й ПВЩЮОП СЧМСЕФУС ЮБУФША ПДОПЗП Java РБЛЕФБ.
уМХЦВБ ХЛБЪБОЙС ЙНЕО СЧМСЕФУС ПДОПК ЙЪ ЖХОДБНЕОФБМШОЩИ УМХЦВ CORBA. пВЯЕЛФЩ CORBA БУУПГЙЙТХАФУС РП УУЩМЛЕ, ЬФБ ЮБУФШ ЙОЖПТНБГЙЙ ОЙЮЕЗП ОЕ ЪОБЮЙФ ДМС ЮЕМПЧЕЛБ. оП УУЩМЛБН НПЦОП ОБЪОБЮБФШ ПРТЕДЕМЕООЩЕ РТПЗТБННПК УФТПЛПЧЩЕ ЙНЕОБ. ьФБ ПРЕТБГЙС ЙЪЧЕУФБ ЛБЛ ЙНЕОПЧБОЙЕ УУЩМПЛ (stringifying the reference) Й ПДЙО ЙЪ OMA ЛПНРПОЕОФ, уМХЦВБ хЛБЪБОЙС йНЕО (Naming Service), РТЕДОБЪОБЮЕОБ ДМС ЧЩРПМОЕОЙС РТЕПВТБЪПЧБОЙС УФТПЛЙ Ч ПВЯЕЛФ Й ПВЯЕЛФБ Ч УФТПЛХ. фБЛ ЛБЛ уМХЦВБ хЛБЪБОЙС йНЕО ДЕКУФЧХЕФ ЛБЛ ФЕМЕЖПООБС ЛОЙЗБ, Ч ЛПФПТПК Й ЛМЙЕОФ Й УЕТЧЕТ НПЗХФ РПМХЮЙФ ЛПОУХМФБГЙА, ПОБ ТБВПФБЕФ ЛБЛ ПФДЕМШОЩК РТПГЕУУ. уПЪДБОЙЕ РТЕПВТБЪПЧБОЙС ПВЯЕЛФБ Ч УФТПЛХ ОБЪЩЧБЕФУС РТЙЧСЪЩЧБОЙЕН ПВЯЕЛФБ (binding an object), Б ХДБМЕОЙС РТЕПВТБЪПЧБОЙС ОБЪЩЧБЕФУС ПФЧСЪЩЧБОЙЕН (unbinding). рПМХЮЕОЙЕ УУЩМЛЙ ОБ ПВЯЕЛФ РП РЕТЕДБООПК УФТПЛЕ ОБЪЩЧБЕФУС ТБЪТЕЫЕОЙЕН ЙНЕОЙ (resolving the name).
оБРТЙНЕТ, РТЙ ЪБРХУЛЕ УЕТЧЕТ РТЙМПЦЕОЙК ДПМЦЕО УПЪДБФШ УЕТЧЕТОЩК ПВЯЕЛФ, УЧСЪБФШ ПВЯЕЛФ У ЙНЕОЕН УЕТЧЙУБ, Б ЪБФЕН РПДПЦДБФШ РПЛБ ЛМЙЕОФ ЧЩРПМОЙФ ЪБРТПУ. лМЙЕОФ УОБЮБМБ РПМХЮБЕФ УУЩМЛХ ОБ УЕТЧЕТОЩК ПВЯЕЛФ, ТБЪТЕЫБЕФ УФТПЛПЧПЕ ЙНС, Б ЪБФЕН НПЦЕФ ЧЩРПМОЙФШ ПВТБЭЕОЙЕ Л УЕТЧЕТХ, ЙУРПМШЪХС УУЩМЛХ.
уРЕГЙЖЙЛБГЙС уЕТЧЙУБ хЛБЪБОЙС йНЕО СЧМСЕФУС ЮБУФША CORBA, ОП РТЙМПЦЕОЙС, ЛПФПТЩЕ ТЕБМЙЪХАФ ЕЗП ПВЕУРЕЮЙЧБАФУС РТПЙЪЧПДЙФЕМЕН ORB. уРПУПВ РПМХЮЕОЙС ДПУФХРБ Л уЕТЧЙУХ хЛБЪБОЙС йНЕО ЖХОЛГЙПОБМШОП НПЦЕФ ТБЪМЙЮБФШУС Ч ЪБЧЙУЙНПУФЙ ПФ РТПЙЪЧПДЙФЕМС.
рТЙЧЕДЕООЩЕ ЪДЕУШ ЛПД ОЕ РТПДХНБО ДП ЛПОГБ, РПФПНХ ЮФП ТБЪМЙЮОЩЕ ORB ЙНЕАФ ТБЪМЙЮОЩЕ УРПУПВЩ ДПУФХРБ Л УЕТЧЙУХ CORBA, ФБЛ ЮФП РТЙНЕТЩ УРЕГЙЖЙЮОЩ ДМС РТПЙЪЧПДЙФЕМС. (рТЙЧПДЙНЩЕ ОЙЦЕ РТЙНЕТЩ ЙУРПМШЪХАФ JavaIDL - ЬФП ВЕУРМБФОЩК РТПДХЛФ ПФ Sun, РПУФБЧМСЕНЩК У ПВМЕЗЮЕООПК ЧЕТУЙЕК ORB, УМХЦВПК ХЛaИЪБОЙС ЙНЕО Й ЛПНРЙМСФПТПН IDL-to-Java.) лТПНЕ ФПЗП, ФБЛ ЛБЛ Java ЕЭЕ ПЮЕОШ НПМПД Й РТПДПМЦБЕФ ТБЪЧЙЧБФШУС, ОЕ ЧУЕ ПУПВЕООПУФЙ CORBA РТЕДУФБЧМЕОЩ Ч ТБЪМЙЮОЩИ Java/CORBA РТПДХЛФБИ.
нЩ ИПФЙН ТЕБМЙЪПЧБФШ УЕТЧЕТ, ТБВПФБАЭЙК ОБ ФПК ЦЕ НБЫЙОЕ, Х ЛПФПТПЗП НПЦОП ПРТПУЙФШ ФПЮОПЕ ЧТЕНС. нЩ ФБЛ ЦЕ ИПФЙН ТЕБМЙЪПЧБФШ ЛМЙЕОФБ, ПРТБЫЙЧБАЭЕЗП ФПЮОПЕ ЧТЕНС. ч ЬФПН УМХЮБЕ НЩ ВХДЕН ТЕБМЙЪПЧЩЧБФШ ПВЕ РТПЗТБННЩ ОБ Java, ОП НЩ ФБЛЦЕ НПЦЕН ЙУРПМШЪПЧБФШ ДЧБ ТБЪОЩИ СЪЩЛБ (ЮФП ЮБЭЕ ЧУЕЗП УМХЮБЕФУС Ч ТЕБМШОЩИ УЙФХБГЙСИ).
рЕТЧЩК ЫБЗ УПУФПЙФ Ч ОБРЙУБОЙЙ IDL ПРЙУБОЙС ТБЪТБВБФЩЧБЕНПЗП УЕТЧЙУБ. ьФП ПВЩЮОП ДЕМБЕФ РТПЗТБННЙУФ УЕТЧЕТБ, ЛПФПТЩК РПУМЕ ЬФПЗП УЧПВПДЕО ТЕБМЙЪПЧЩЧБФШ УЕТЧЕТ ОБ МАВПН СЪЩЛЕ, ДМС ЛПФПТЗП УХЭЕУФЧХЕФ CORBA IDL ЛПНРЙМСФПТ. IDL ЖБКМ РЕТЕДБЕФУС РТПЗТБННЙУФХ ЛМЙЕОФУЛПК УФПТПОЩ Й УФБОПЧЙФУС НПУФПН НЕЦДХ СЪЩЛБНЙ.
рТЙЧЕДЕООЩК ОЙЦЕ РТЙНЕТ РПЛБЪЩЧБЕФ IDL ПРЙУБОЙЕ ДМС ОБЫЕЗП УЕТЧЕТБ ExactTime:
//: c15:corba:ExactTime.idl
//# чЩ ДПМЦОЩ ХУФБОПЧЙФШ idltojava.exe У
//# java.sun.com Й ПФТЕЗХМЙТПЧБФШ ХУФБОПЧЛЙ ДМС
//# ЙУРПМШЪПЧБОЙС ЧБЫЕЗП МПЛБМШОПЗП C РТЕРТПГЕУУПТБ
//# ЮФПВЩ ПФЛПНРЙМЙТПЧБФШ ЬФПФ.
//# уНПФТЙФЕ ДПЛХНЕФБГЙА ОБ java.sun.com.
module remotetime {
interface ExactTime {
string getTime();
};
}; ///:~
ьФП ДЕЛМБТБГЙС ЙОФЕТЖЕКУБ ExactTime ЧОХФТЙ РТПУТБОУФЧБ ЙНЕО remotetime. йОФЕТЖЕКУ УПУФПЙФ ЙЪ ЕДЙОУФЧЕООПЗП НЕФПДБ, ЛПФПТЩК ЧПЪЧТБЭБЕФ ФЕЛХЭЕЕ ЧТЕНС Ч ЖПТНБФЕ string.
чФПТПК ЫБЗ УПУФПЙФ Ч ЛПНРЙМСГЙЙ IDL ДМС УПЪДБОЙС ЛПДБ СЛПТЕК Й УЛЕМЕФПЧ Java, ЛПФПТЩК ВХДЕФ ЙУРПМШЪПЧБФШУС ДМС ТЕБМЙЪБГЙЙ ЛМЙЕОФБ Й УЕТЧЕТБ. йОУФТХНЕОФ, РПУФБЧМСЕНЩК У JavaIDL ОБЭЩЧБЕФУС idltojava:
idltojava remotetime.idl
ьФП БЧФПНБФЙЮЕУЛЙ УЗЕОЕТЙТХЕФ ЛПД Й ДМС СЛПТЕК Й ДМС УЛЕМЕФПЧ. Idltojava УЗЕОЕТЙТХЕФ Java package У ОБЪЧБОЙЕН IDL НПДХМС: remotetime, Й УЗЕОЕТЙТХЕФ Java ЖБКМЩ, РПНЕУФЙЧ ЙИ Ч РПДДЙТЕЛФПТЙК remotetime. _ExactTimeImplBase.java - ЬФП УЛЕМЕФ, ЛПФПТЩК НЩ ВХДЕН ЙУРПМШЪПЧБФШ ДМС ТЕБМЙЪБГЙЙ ПВЯЕЛФБ УЕТЧЕТБ, Б _ExactTimeStub.java ВХДЕФ ЙУРПМШЪПЧБО ДМС ЛМЙЕОФБ. уХЭЕУФЧХЕФ Java РТЕДУФБЧМЕОЙЕ IDL ЙОФЕТЖЕКУБ Ч ExactTime.java Й ОБВПТ ДТХЗЙИ ЖБКМПЧ РПДДЕТЦЛЙ, ОБРТЙНЕТ, ДМС ПВМЕЗЮЕОЙС ДПУФХРБ Л ПРЕТБГЙЙ УЕТЧЙУБ ХЛБЪБОЙС ЙНЕО.
оЙЦЕ ЧЩ НПЦЕФЕ ЧЙДЕФШ ЛПД УЕТЧЕТОПК УФПТПОЩ. тЕБМЙЪБГЙС УЕТЧЕТОПЗП ПВЯЕЛФБ ЧЩРПМОЕОБ Ч ЛМБУУЕ ExactTimeServer. RemoteTimeServer СЧМСЕФУС РТЙМПЦЕОЙЕН, ЛПФПТПЕ УПЪДБЕФ ПВЯЕЛФ УЕТЧЕТБ, ТЕЗЙУФТЙТХЕФ ЕЗП У РПНПЫША ORB, ДБЕФ ЙНС УУЩМЛЕ ОБ ПВЯЕЛФ, Б ЪБФЕН НЙТОП ПЦЙДБЕФ ЛМЙЕОФУЛПЗП ЪБРТПУБ.
//: c15:corba:RemoteTimeServer.java
import remotetime.*;
import org.omg.CosNaming.*;
import org.omg.CosNaming.NamingContextPackage.*;
import org.omg.CORBA.*;
import java.util.*;
import java.text.*;
// тЕБМЙЪБГЙС УЕТЧЕТОПЗП ПВЯЕЛФБ
class ExactTimeServer extends _ExactTimeImplBase {
public String getTime(){
return DateFormat.
getTimeInstance(DateFormat.FULL).
format(new Date(
System.currentTimeMillis()));
}
}
// тЕБМЙЪБГЙС ХДБМЕООПЗП РТЙМПЦЕОЙС
public class RemoteTimeServer {
// чЩВТПУ ЙУЛМАЮЕОЙК ОБ ЛПОУПМШ
public static void main(String[] args)
throws Exception {
// уПЪДБОЙЕ Й ТЕБМЙЪБГЙС ORB:
ORB orb = ORB.init(args, null);
// уПЪДБОЙЕ УЕТЧЕТОПЗП ПВЯЕЛФБ Й ТЕЗЙУФТГЙС:
ExactTimeServer timeServerObjRef =
new ExactTimeServer();
orb.connect(timeServerObjRef);
// рПМХЮЕОЙЕ ЛПТОЕЧПЗП ЛПОФЕЛУФБ ЙНЕО:
org.omg.CORBA.Object objRef =
orb.resolve_initial_references(
"NameService");
NamingContext ncRef =
NamingContextHelper.narrow(objRef);
// рТЙУЧПЕОЙЕ УФТПЛПЧПЗП ЙНЕОЙ
// ДМС УУЩМЛЙ ОБ ПВЯЕЛФ (УЧСЪЩЧБОЙЕ):
NameComponent nc =
new NameComponent("ExactTime", "");
NameComponent[] path = { nc };
ncRef.rebind(path, timeServerObjRef);
// пЦЙДБОЙЕ ЪБРТПУБ ЛМЙЕОФБ:
java.lang.Object sync =
new java.lang.Object();
synchronized(sync){
sync.wait();
}
}
} ///:~
лБЛ ЧЩ НПЦЕФЕ ЧЙДЕФШ, ТЕБМЙЪБГЙС УЕТЧЕТОПЗП ПВЯЕЛФБ ДПУФБФПЮОП РТПУФБ. ьФП ПВЩЮОЩК Java ЛМБУУ, ХОБУМЕДПЧБООЩК ПФ ЛПДБ УЛЕМЕФБ, УЗЕОЕТЙТПЧБООПЗП IDL ЛПНРЙМСФПТПН. чЕЭЙ УФБОПЧСФУС НОПЗП УМПЦОЕЕ, ЛПЗДБ РТПЙУИПДЙФ ЧЪБЙНПДЕКУФЧЙЕ У ORB Й ДТХЗЙНЙ УМХЦВБНЙ CORBA.
ьФП ЛПТПФЛПЕ ПРЙУБОЙЕ ФПЗП, ЮФП ДЕМБЕФ JavaIDL ЛПД (Ч ПУОПЧОПН ЙЗОПТЙТХЕФУС ЮБУФШ CORBA ЛПДБ, ЪБЧЙУСЭБС ПФ РТПЙЪЧПДЙФЕМС). рЕТЧБС УФТПЛБ main( ) ЪБРХУЛБЕФ ORB, ЬФП ОЕПВИПДЙНП РПФПНХ, ЮФП ОБЫЕНХ УЕТЧЕТХ ОЕПВИПДЙНП ЧЪБЙНПДЕКУФЧПЧБФШ У ОЙН. уТБЪХ РПУМЕ ЙОЙГЙБМЙЪБГЙЙ ORB УПЪДБЕФУС УЕТЧЕТОЩК ПВЯЕЛФ. оБ УБНПН ДЕМЕ РТБЧЙМШОЕЕ ОБЪЩЧБФШ ЧТЕНЕООЩК ПВУМХЦЙЧБАЭЙК ПВЯЕЛФ (transient servant object): ПВЯЕЛФ, ЛПФПТЩК РТЙОЙНБЕФ ЪБРТПУЩ ПФ ЛМЙЕОФПЧ, Й ЮШЕ ЧТЕНС ЦЙЪОЙ ТБЧОП УПЧРБДБЕФ У ЧТЕНЕОЕН ЦЙЪОЙ РПТПДЙЧЫЕЗП РТПГЕУУБ. лБЛ ФПМШЛП ЧТЕНЕООЩК ВУМХЦЙЧБАЭЙК ПВЯЕЛФ УПЪДБО, ПО ТЕЗЙУФТЙТХЕФУС У РПНПЫШ ORB, ЮФП ПЪОБЮБЕФ, ЮФП ORB ЪОБЕФ П ЕЗП ОБМЙЮЙ Й ФЕРЕТШ НПЦЕФ РЕТЕОБРТБЧМСФШ Л ОЕНХ ЪБРТПУЩ.
дП ЬФПЗП НПНЕОФБ ЧУЕ, ЮФП НЩ ЙНЕМЙ - ЬФП timeServerObjRef - ХЛБЪБФЕМШ ОБ ПВЯЕЛФ, ЛПФПТЩК ЙЪЧЕУФЕО ФПМШЛП ЧОХФТЙ ФЕЛХЭЕЗП УЕТЧЕТОПЗП РТПГЕУУБ. уМЕДХАЭЙК ЫБЗ УПУФПЙФ Ч РТЙУЧПЕОЙЙ УФТПЛПЧПЗП ЙНЕОЙ ЬПНХ ПВУМХЦЙЧБАЭЕНХ ПВЯЕЛФХ. лМЙЕОФ ВХДЕФ ЙУРПМШЪПЧБФШ ЙНС ДМС ОБИПЦДЕОЙС ПВУМХЦЙЧБАЭЕЗП ПВЯЕЛФБ. нЩ УПЧЕТЫЙМЙ ЬФХ ПРЕТБГЙА, ЙУРПМШЪХС уЕТЧЙУ хЛБЪБОЙС йНЕО. чП-РЕТЧЩИ, ОБН ОЕПВИПДЙНБ УУЩМЛБ ОБ уМХЦВХ хЛБЪБОЙС йНЕО. нЕФПД resolve_initial_references( ) РТЙОЙНБЕФ ЪОБЮЙНХА УУЩМЛХ ОБ ПВЯЕЛФ уМХЦВЩ хЛБЪБОЙС йНЕО, Ч УМХЮБЕ JavaIDL “NameService”, Й ЧПЪЧТБЭБЕФ УУЩМЛХ ОБ ПВЯЕЛФ. пО РТЙЧПДЙФ УЩМЛХ Л УРЕГЙЖЙЮОПНХ ФЙРХ NamingContext, ЙУРПМШЪХС НЕФПД narrow( ). фЕРЕТШ НЩ НПЦЕН ЙУРПМШЪПЧБФШ УМХЦВХ ХЛБЪБОЙС ЙНЕО.
дМС УЧСЪЩЧБОЙС ПВУМХЦЙЧБАЭЙИ ПВЯЕЛФПЧ УП УУЩМЛБНЙ ОБ УФТПЛПЧЩЕ ПВЯЕЛФЩ, НЩ УОБЮБМБ УПЪДБЕН ПВЯЕЛФ NameComponent, ЙОЙГЙБМЙЪЙТХЕФ ЕЗП ЪОБЮЕОЙЕН “ExactTime” - УФТПЛБ ЙНЕОЙ, ЛПФПТХА НЩ ИПФЙН УЧСЪБФШ У ПВУМХЦЙЧБАЭЙН ПВЯЕЛФПН. ъБФЕН, ЙУРПМШЪХС НЕФПД rebind( ), УФТПЛПЧБС УУЩМЛБ УЧСЪЩЧБЕФУС УП УУЩМЛПК ОБ ПВЯЕЛФ. нЩ ЙУРПШЪХЕН rebind( ) ДМС РТЙУЧПЕОЙС УУЩМЛЙ, ДБЦЕ ЕУМЙ ПОБ ХЦЕ УХЭЕУФЧХЕФ, ФПЗДБ ЛБЛ bind( ) ЧЩВТБУЩЧБЕФ ЙУЛМАЮЕОЙЕ, ЕУМЙ УУЩМЛБ ХЦЕ УХЭЕУФЧХЕФ. йНС УПУФПЙФ Ч CORBA ЙЪ РПУМЕДПЧБФЕМШОПУФЙ NameContexts — РПЬФПНХ НЩ ЙУРПМШЪХЕН НБУУЙЧ ДМС УЧСЪЩЧБОЙС ЙНЕОЙ УП УУЩМЛПК ОБ ПВЯЕЛФ.
оБЛПОЕГ, ПВУМХЦЙЧБАЭЙК ПВЯЕЛФ ЗПФПЧ Л ЙУРПМШЪПЧБОЙА ЛМЙЕОФБНЙ. рПУМЕ ЬФПЗП УЕТЧЕТОЩК РТПГЕУУ ЧИПДЙФ Ч УПУФПСОЙЕ ПЦЙДБОЙС. пРСФШ ФБЛЙ, ЙЪ-ЪБ ФПЗП, ЮФП ЬФП ЧТЕНЕООПЕ ПВУМХЦЙЧБОЙЕ, РПЬФПНХ ЧТЕНС ЦЙЪОЙ ПЗТБОЙЮЕОП УЕТЧЕТОЩН РТПГЕУУПН. JavaIDL Ч ОБУФПСЭЕЕ ЧТЕНС ОЕ РПДДЕТЦЙЧБЕФ РПУФПСОЩЕ ПВЯЕЛФЩ — ПВЯЕЛФЩ, ЛПФПТЩЕ РТПДПМЦБАФ УХЭЕУФЧПЧБФШ ЧОЕ РПТПДЙЧЫЕЗП ЕЗП РТПГЕУУБ.
фЕРЕТШ, ЛПЗДБ НЩ ЙНЕЕН РТЕДУФБЧМЕОЙЕ П ФПН, ЮФП ДЕМБЕФ УЕТЧЕТОЩК ЛПД, ДБЧБКФЕ ЧЪЗМСОЕН ОБ ЛПД ЛМЙЕОФБ:
//: c15:corba:RemoteTimeClient.java
import remotetime.*;
import org.omg.CosNaming.*;
import org.omg.CORBA.*;
public class RemoteTimeClient {
// чЩВТБУЩЧБЕН ЙУЛМАЮЕОЙЕ ОБ ЛПОУПМШ:
public static void main(String[] args)
throws Exception {
// уПЪДБОЙЕ Й ЙОЙГЙБМЙЪБГЙС ORB:
ORB orb = ORB.init(args, null);
// рПМХЮЕОЙЕ ЛПОФЕЛУФБ ОБЙНЕОПЧБОЙС:
org.omg.CORBA.Object objRef =
orb.resolve_initial_references(
"NameService");
NamingContext ncRef =
NamingContextHelper.narrow(objRef);
// рПМХЮЕОЙЕ (ТБЪТЕЫЕОЙЕ) УУЩМЛЙ ОБ УФТПЛПЧЩК
// ПВЯЕЛФ ДМС УЕТЧЕТБ ЧТЕНЕОЙ:
NameComponent nc =
new NameComponent("ExactTime", "");
NameComponent[] path = { nc };
ExactTime timeObjRef =
ExactTimeHelper.narrow(
ncRef.resolve(path));
// чЩРПМОЕОЙЕ ЪБРТПУБ Л УЕТЧЕТХ:
String exactTime = timeObjRef.getTime();
System.out.println(exactTime);
}
} ///:~
рЕТЧЩЕ ОЕУЛПМШЛП УФТПЛ ДЕМБАФ ФП ЦЕ, ЮФП ПОЙ ДЕМБМЙ Ч УЕТЧЕТОПН РТПГЕУУЕ: ЙОЙГЙБМЙЪЙТХАФ ORB Й ТБЪТЕЫБАФ ХЛБЪБФЕМШ ОБ УЕТЧЙУ ХЛБЪБОЙС ЙНЕО. дБМЕЕ, ОБН ОХЦОБ УУЩМЛБ ОБ ПВЯЕЛФ ДМС ПВУМХЦЙЧБАЭЕЗП ПВЯЕЛФБ, РПЬФПНХ НЩ РЕТЕДБЕН УУЩМЛХ ОБ УФТПЛПЧЩК ПВЯЕЛФ Ч НЕФПД resolve( ), Й РТЙЧПДЙН ТЕЪХМШФБФ Л УУЩМЛЕ ОБ ЙОФЕТЖЕКУ ExactTime, ЙУРПМШЪХС НЕФПД narrow( ). ч ЛПОГЕ НЩ ЧЩЪЩЧБЕН getTime( ).
фЕРЕТШ Н ЩЙНЕЕН УЕТЧЕТОПЕ Й ЛМЙЕОФУЛПЕ РТЙМПЦЕОЙС, ЗПФПЧЩЕ Л ЧЪБЙНПДЕКУФЧЙА. чЩ ЧЙДЕМЙ, ЮФП ПВБ ПОЙ ОХЦДБАФУС Ч УМХЦВЕ ХЛБЪБОЙС ЙНЕО ДМС УЧСЪЩЧБОЙС Й ТБЪТЕЫЕОЙС ХЛБЪБФЕМС ОБ УФТПЛПЧЩК ПВЯЕЛФ. чЩ ДПМЦОЩ ЪБРХУФЙФШ РТПГЕУУ ХЛБЪБОЙС ЙНЕО ДП ЪБРХУЛБ УЕТЧЕТБ Й ЛМЙЕОФБ. ч JavaIDL УМХЦВБ ХЛБЪБОЙС ЙНЕО СЧМСЕФУС Java РТЙМПЦЕОЙЕН, ЛПФПТПЕ РПУФБЧМСЕФУС Ч РБЛЕФЕ У РТПДХЛФПН, ОП ДМС ДТХЗЙИ РТПДХЛФПЧ ЬФП НПЦЕФ ВЩФШ ОЕ ФБЛ. уМХЦВБ ХЛБЪБОЙС ЙНЕО JavaIDL ЪБРХУЛБЕФУС ЧОХФТЙ ЬЛЪЕНРМСТБ JVM Й УМХЫБЕФ РП ХНПМЮБОЙА УЕФЕЧПК РПТФ 900.
фЕРЕТШ ЧЩ ЗПФПЧЩ ЪБРХУФЙФШ ЧБЫЕ УЕТЧЕТОПЕ Й ЛМЙЕОФУЛПЕ РТЙМПЦЕОЙЕ (Ч ЬФПН РПТСДЛЕ, ФБЛ ЛБЛ ОБЫ УЕТЧЕТ ЧТЕНЕООЩК). еУМЙ ЧЩ ЧУЕ ХУФБОПЧЙМЙ РТБЧЙМШОП, ФП, ЮФП ЧЩ РПМХЮЙФЕ - ЬФП ЕДЙОУФЧЕООБС УФТПЛБ ЧЩЧПДБ Ч ЛМЙЕОФУЛПК ЛПОУПМЙ, УППВЭБАЭБС ЧБН ФЕЛХЭЕЕ ЧТЕНС. лПОЕЮОП ЬФП ОЕ ПЮЕОШ ЧПМОХАЭЕ УБНП РП УЕВЕ, ОП ЧЩ ДПМЦОЩ РТЙОСФШ ЧП ЧОЙНБОЙЕ ПДОХ ЧЕЭШ: ДБЦЕ ЕУМЙ ПОЙ ТБУРПМБЗБАФУС ОБ ПДОПК Й ФПК ДЕ НБЫЙОЕ, ЛМЙЕОФУЛПЕ Й УЕТЧЕТОПЕ РТЙМПЦЕОЙС ЪБРХУЛБАФУС ЧОХФТЙ ТБЪОЩИ ЧЙТФХБМШОЩИ НБЫЙО Й ПОЙ НПЗХФ ПВЭБФШУС ЮЕТЕЪ МЕЦБЭЙК Ч ПУОПЧЕ ЙОФЕЗТЙТХАЭЙК ХТПЧЕОШ, ORB Й уЕТЧЙУ хЛБЪБОЙС йНЕО.
ьФПФ РТПУФПК РТЙНЕТ РТЕДОБЪОБЮЕО МС ТБВПФЩ ВЕЪ УЕФЙ, ОП ORB ПВЩЮОП ЛПОЖЙЗХТЙТХЕФУС ДМС ОЕЪБЧЙУЙНПУФЙ ПФ НЕУФПРПМПЦЕОЙС. лПЗДБ УЕТЧЕТ Й ЛМЙЕОФ ОБИПДСФУС ОБ ТБЪОЩИ НБЫЙОБИ, ORB НПЦЕФ ТБЪТЕЫБФШ ХДБМЕООЩЕ УФТПЛПЧЩЕ УУЩМЛЙ, ЙУРПМШЪХС ЛПНРПОЕОФ, ЙЪЧЕУФОЩК ЛБЛ Implementation Repository. иПФС Implementation Repository СЧМСЕФУС ЮБУФША CORBA, ДМС ОЕЗП ОЕФ УРЕГЙЖЙЛБГЙЙ, ФБЛ ЮФП ПО ТБЪМЙЮЕО Х ТБЪОЩИ РТПЙЪЧПДЙФЕМЕК.
лБЛ ЧЩ НПЦЕФЕ ЧЙДЕФШ, П CORBA ЕУФШ НОПЗП ВПМШЫЕ ЙОЖПТНБГЙЙ, ЮЕН ВЩМП ТБУУНПФТЕОП ФХФ, ОП ЧЩ ДПМЦОЩ РПМХЮЙФШ ПУОПЧОХА ЙДЕА. еУМЙ ЧЩ ИПФЙФЕ РПМХЮЙФШ ВПМЕЕ РПДТПВОХА ЙОЖПТНБГЙА ПФОПУЙФЕМШОП CORBA, ОБЮОЙФЕ У Web УФТБОЙГЩ OMG, ОБ www.omg.org. фБН ЧЩ ОБКДЕФЕ ДПЛХНЕОФБГЙА, ВЕМЩЕ УФТБОЙГЩ, ТБВПФЩ Й УУЩМЛЙ ОБ ДТХЗЙЕ ЙУИПДОЩЕ ФЕЛУФЩ Й РТПДХЛФЩ CORBA.
Java БРРМЕФЩ НПЗХФ ЧЩУФХРБФШ Ч ТПМЙ CORBA ЛМЙЕОФПЧ. фБЛЙН ПВТБЪПН БРРМЕФЩ НПЗХФ РПМХЮБФШ ДПУФХР Л ХДБМЕООПК ЙОЖПТНБГЙЙ Й УМХЦВБН, УХЭЕУФЧХАЭЙН, ЛБЛ CORBA ПВЯЕЛФЩ. оП БРРМЕФЩ НПЗХФ УПЕДЙОСФШУС ФПМШЛП У ФЕН УЕТЧЕТПН, У ЛПФПТПЗП ЙИ ЪБЗТХЪЙМЙ, ФБЛ ЮФП ЧУЕ CORBA ПВЯЕЛФЩ, У ЛПФПТЩНЙ ЧЪБЙНПДЕКУФЧХЕФ БРРМЕФ, ДПМЦОЩ ВЩФШ РПНЕЭЕОЩ ОБ УЕТЧЕТЕ. ьФП РТПФЙЧПТЕЮЙФ ФПНХ, ДМС ЮЕЗП РТЕДОБЪОБЮЕО CORBA: ДБФШ ЧБН РПМОХА ОЕЪБЧЙУЙНПУФШ ПФ НЕУФПРПМПЦЕОЙС.
ьФП ПУПВЕООПУФШ УЕФЕЧПК ВЕЪПРБУОПУФЙ. еУМЙ ЧЩ Ч йОФТБОЕФЕ, ПДОЙН ЙЪ ТЕЫЕОЙК СЧМСЕФУС ПФЛБЪ ПФ УЙУФЕНЩ ВЕЪПРБУОПУФЙ ВТПХЪЕТБ. йМЙ Ч ХУФБОПЧЛЙ firewall ОБ УПЕДЙОЕОЙС УП ЧОЕЫОЙИ УЕТЧЕТПЧ.
оЕЛПФПТЩЕ ЙЪ РТПДХЛФПЧ Java ORB РТЕДМБЗБАФ РПФЕОГЙБМШОПЕ ТЕЫЕОЙЕ ЬФПК РТПМЕНЩ. оБРТЙНЕТ, ОЕЛПФПТЩЕ ТЕБМЙЪХАФ ФП, ЮФП ОБЪЩЧБЕФУС ФХОЕМЙТПЧБОЙЕН HTTP Tunneling, Б ДТХЗЙЕ ЙНЕАФ УЧПЙ УПВУФЧЕООЩЕ ПУПВЕООПУФЙ ДМС firewall.
ьФП УМЙЫЛПН УМПЦОЩК ЧПРТПУ, ЮФПВЩ ПО ВЩМ ПУЧЕЭЕО Ч РТЙМПЦЕОЙЙ, ОП ЬФП ФП, Ч ЮЕН ЧЩ ДПМЦОЩ ВЩФШ ХЧЕТЕОЩ.
чЩ ЧЙДЕМЙ, ЮФП ПДОПК ЙЪ ЗМБЧОЩИ ПУПВЕООПУФЕК CORBA СЧМСФУС РПДДЕТЦЛБ RPC, ЛПФПТБС РПЪЧПМСЕФ ЧБЫЙН МПЛБМШОЩН ПВЯЕЛФБН ЧЩЪЩЧБФШ НЕФПДЩ ХДБМЕООПЗП ПВЯЕЛФБ. лПОЕЮОП, ЕУФШ ТПДОПЕ УЧПКУФЧП Java, ЛПФПТПЕ ДЕМБЕФ ФП ЦЕ УБНПЕ: RMI (УНПФТЙФЕ зМБЧХ 15). рТЙ ЙУРПМШЪПЧБОЙЙ RMI ЧПЪНПЦОЩН RPC НЕЦДХ ПВЯЕЛФБНЙ Java, CORBA ДЕМБЕФ ЧПЪНПЦОЩН RPC НЕЦДХ ПВЯЕЛФБНЙ, ТЕБМЙЪПЧБООЩНЙ ОБ МАВПН СЪЩЛЕ. ч ЬФПН ПЗТПНОПЕ ТБЪМЙЮЙЕ.
пДОБЛП RMI НПЦЕФ ВЩФШ ЙУРПМШЪПЧБОП ДМС ЧЩЪПЧБ УЕТЧЙУПЧ ХДБМЕООПЗП ОЕ Java ЛПДБ. чУЕ, ЮФП ЧБН ОХЦОП - ЬФП ОЕЛПФПТЩК Java ПВЯЕЛФ-ПВПМПЮЛБ, ЧЛМАЮБАЭЙК Ч УЕВС ОЕ Java ЛПД ОБ УФПТПОЕ УЕТЧЕТБ. пВЯЕЛФ-ПВПМПЮЛБ РТЙУПЕДЙОСЕФУС ЧОЕЫОЙН ПВТБЪПН Л Java ЛМЙЕОФХ РП RMI, Й ЧОХФТЕООЙН ПВТБЪПН УПЕДЙОСЕФУС У ОЕ Java ЛПДПН, ЙУРПМШЪХС ПДОХ ЙЪ ФЕИОПМПЗЙК, ФБЛЙИ ЛБЛ JNI ЙМЙ J/Direct.
фБЛПК РПДИПД ФТЕВХЕФ ПФ ЧБУ ОБРЙУБОЙС ОЕЛПФПТПЗП ТПДБ ЙОФЕЗТБГЙПООПЗП ХТПЧОС, ЛПФПТЩК СЧОП ДЕМБЕФ ФП, ЮФП CORBA ДЕМБЕФ ЪБ ЧБУ, ОП Ч ЬФПН УМХЮБЕ Х ЧБУ ОЕФ ОЕПИПДЙНПУФЙ ЙУРПМШЪПЧБФШ ORB УФПТПООЙИ ТБЪТБВПФЮЙЛПЧ.
рТЕДРПМПЦЙН, [77] ЧБН ОХЦОП ТБЪТБВПФБФШ НОПЗПСТХУОПЕ РТЙМПЦЕОЙЕ ДМС РТПУНПФТБ Й ПВОПЧМЕОЙС ЪБРЙУЕК Ч ВБЪЕ ДБООЩИ ЮЕТЕЪ Web ЙОФЕТЖЕКУ. чЩ НПЦЕФЕ ОБРЙУБФШ РТЙМПЦЕОЙЕ ДМС ВБЪ ДБООЩИ, ЙУРПМШЪХС JDBC, Б Web ЙОФЕТЖЕКУ ЙУРПМШЪХЕФ JSP/УЕТЧМЕФЩ, Б ТБУРТЕДЕМЕООБС УЙУФЕНБ ЙУРПМШЪХЕФ CORBA/RMI. оП ЛБЛЙЕ ДПРПМОЙФЕМШОЩЕ УППВТБЦЕОЙС ЧЩ ДПМЦОЩ РТЙОСФШ ЧП ЧОЙНБОЙЕ РТЙ ТБЪТБВПФЛЕ УЙУФЕНЩ ТБУРТЕДЕМЕООЩИ ПВЯЕЛФПЧ ЛТПНЕ ХЦЕ ЙЪЧЕУФОПЗП API? чПФ ПУОПЧОЩЕ УППВТБЦЕОЙС:
рТПЙЪЧПДЙФЕМШОПУФШ: тБУРТЕДЕМЕООЩЕ ПВЯЕЛФЩ, ЛПФПТЩЕ ЧЩ УПЪДБЕФЕ, ДПМЦОЩ ИПТПЫП ТБВПФБФШ, ФБЛ ЛБЛ РПФЕОГЙБМШОП ПОЙ ДПМЦОЩ ПВУМХЦЙЧБФШ НОПЗП ЛМЙЕОФПЧ ПДОПЧТЕНЕООП. чБН ОБДП ЙУРПМШЪПЧБФШ ПРФЙНЙЪБГЙПООЩЕ ФЕИОПМПЗЙЙ, ФБЛЙЕ ЛБЛ ЛЕЫЙТПЧБОЙЕ Й ПВЯЕДЙОЕОЙЕ ФБЛЙИ ТЕУХТУПЧ, ЛБЛ УПЕДЙОЕОЙЕ У ВБЪПК ДБООЩИ. чБН ФБЛЦЕ РПОБДПВЙФУС ХРТБЧМСФШ РТПДПМЦЙФЕМШОПУФША ЦЙЪОЙ ЧБЫЙИ ТБУРТЕДЕМЕООЩИ ПВЯЕЛФПЧ.
нБУЫФБВЙТХЕНПУФШ: ТБУРТЕДЕМЕООЩЕ ПВЯЕЛФЩ ДПМЦОЩ ВЩФШ НБУЫФБВЙТХЕНЩНЙ. нБУЫФБВЙТХЕНПУФШ Ч ТБУРТЕДЕМЕООЩИ РТЙМПЦЕОЙСИ ПЪОБЮБЕФ, ЮФП ЮЙУМП ЬЛЪЕНРМСТПЧ ЧБЫЙИ ТБУРТЕДЕМЕООЩИ ПВЯЕЛФПЧ НПЦЕФ ХЧЕМЙЮЙЧБФШУС Й ПОЙ НПЗХФ РЕТЕНЕЭБФШУС ОБ ДПРПМОЙФЕМШОЩЕ НБЫЙОЩ ВЕЪ ЙЪНЕОЕОЙС ЛБЛПЗП-МЙВП ЛПДБ.
вЕЪПРБУОПУФШ: тБУРТЕДЕМЕООЩК ПВЯЕЛФ ЮБУФП ДПМЦЕО ХРТБЧМСФШ БЧФПТЙЪБГЙЕК ДПУФХРБ ЛМЙЕОФБ. ч ЙДЕБМЕ ЧЩ ДПВБЧМСЕФЕ ОПЧЩИ РПМШЪПЧБФЕМЕК Й РПМЙФЙЛЙ ВЕЪ РЕТЕЛПНРЙМСГЙЙ.
тБУРТЕДЕМЕООЩЕ фТБОЪБЛГЙЙ: тБУРТЕДЕМЕООЩЕ ПВЯЕЛФЩ ДПМЦОЩ ВЩФШ УРПУПВОЩ РТПЪТБЮОП УУЩМБФШУС ОБ ТБУРТЕДЕМЕООЩЕ ФТБОЪБЛГЙЙ. оБРТЙНЕТ, ЕУМЙ ЧЩ ТБВПФБЕФЕ У ДЧХНС ТБЪОЩНЙ ВБЪБНЙ ДБООЩИ, ЧЩ ДПМЦОЩ ВЩФШ УРПУПВОЩ ПВОПЧЙФШ ЙИ ПДОПЧТЕНЕООП Ч ПДОПК ФТЕОЪБЛГЙЙ Й ПФНЕОЙФШ ЙЪНЕОЕОЙС, ЕУМЙ ОЕ ВЩМ ЧЩРПМОЕО ПРТЕДЕМЕООЩК ЛТЙФЕТЙК.
рПЧФПТОБС ЙУРПМШЪХЕНПУФШ:йДЕБМШОЩК ТБУРТЕДЕМЕООЩК ПВЯЕЛФ НПЦЕФ ВЕЪ ХУЙМЙК РЕТЕОПУЙФУС ОБ УЕТЧЕТ РТЙМПЦЕОЙК ДТХЗПЗП РТПЙЪЧПДЙФЕМС. вЩМП ВЩ ИПТПЫП, ЕУМЙ ВЩ ЧЩ НПЗМЙ РЕТЕРТПДБФШ ЛПНРПОЕОФ ТБУРТЕДЕМЕООПЗП ПВЯЕЛФБ ОЕ ДЕМБС РТЙ ЬФПН УРЕГЙБМШОЩИ ЙЪНЕОЕОЙК, ЙМЙ ЛХРЙФШ ЮЕК-ФП ЮХЦПК ЛПНРПОЕОФ Й ЙУРПМШЪПЧБФШ ЕЗП РЕЪ РЕТЕЛПНРЙМСГЙЙ Й РЕТЕРЙУЩЧБОЙС.
дПУФХРОПУФШ:еУМЙ ПДОБ ЙЪ НБЫЙО ЧБЫЕК УЙУФЕНЩ ЧЩЛМАЮБЕФУС, ЛМЙЕОФЩ ДПМЦОЩ БЧФПНБФЙЮЕУЛЙ РЕТЕКФЙ Л ТЕЪЕТЧОПК ЛПРЙЙ ПВЯЕЛФПЧ, ТБВПФБАЭЙИ ОБ ДТХЗПК НБЫЙОЕ.
ьФЙ УППВТБЦЕОЙС, ОБТСДХ У РТПВМЕНБНЙ ВЙЪОЕУБ, ЛПФПТЩЕ ЧЩ УПВЙТБЕФЕУШ ТЕЫЙФШ, НПЗХФ ЪБУФПРПТЙФШ ЧЕУШ РТПГЕУУ ТБЪТБВПФЛЙ. пДОБЛП ЧУЕ ЬФЙ РТПВМЕНЩ, ЙУЛМАЮБС РТПВМЕНЩ ЧБЫЕЗП ВЙЪОЕУБ, ЙЪМЙЫОЙ — ТЕЫЕОЙС ДПМЦОЩ ВЩФШ РТЙДХНБОЩ ДМС ЛБЦДПЗП ТБУРТЕДЕМЕООПЗП ВЙЪОЕУ-РТЙМПЦЕОЙС.
Sun, ОБТСДХ У ДТХЗЙНЙ МЙДЙТХАЭЙНЙ РТПЙЪЧПДЙФЕМСНЙ ТБУРТЕДЕМЕООЩИ ПВЯЕЛФПЧ, ПРТЕДЕМЙМБ, ЮФП ТБОП ЙМЙ РПЪДОП ЛБЦДБС ЛПНБОДБ ТБЪТБВПФЮЙЛПЧ ОБКДЕФ ПВЮОЩЕ ТЕЫЕОЙС, РПЬФПНХ ПОБ УПЪДБМБ УРЕГЙЖЙЛБГЙА Enterprise JavaBeans (EJB). EJB ПРЙУЩЧБЕФ НПДЕМШ ЛПНРПОЕОФ УФПТПОЩ УЕТЧЕТБ, РТЙОЙНБАЭХА ЧП ЧОЙНБОЙЕ ЧУЕ ХРПНСОХФЩЕ ЧЩЫЕ УППВТБЦЕОЙС Й УФБОДБТФОЩЕ РПДИПДЩ, ЛПФПТЩЕ РПЪЧПМСФ ТБЪТБВПФЮЙЛБН УПЪДБЧБФШ ВЙЪОЕУ-ЛПНРПОЕОФЩ, ОБЪЩЧБЕНЩЕ EJB, ЛПФПТЩЕ ВХДХФ ЙЪПМЙТПЧБОЩ ПФ ОЙЪЛПХТПЧОЕЧПЗП “УМХЦЕВОПЗП” ЛПДБ, Б ВХДХФ РПМОПУФША УЖПЛХУЙТПЧБОЩ ОБ ПВЕУРЕЮЕОЙЙ ВЙЪОЕУУ-МПЗЙЛЙ. рПУЛПМШЛХ EJB ПРТЕДЕМЕОЩ УФБОДБТФОЩН УРПУПВПН, ПОЙ НПЗХФ ВЩФШ ОЕ ЪБЧЙУЙНЩ ПФ РТПЙЪЧПДЙФЕМС.
йЪ-ЪБ УИПЦЕУФЙ ЙНЕО ЮБУФП РХФБАФУС НЕЦДХ НПДЕМША ЛПНРПОЕОФ JavaBeans Й УРЕГЙЖЙЛБГЙЕК Enterprise JavaBeans. JavaBeans Й УРЕГЙЖЙЛБГЙС Enterprise JavaBeans ТБЪДЕМСАФ ПДЙОБЛПЧЩЕ ГЕМЙ: РТПДЧЙЦЕОЙС РПЧФПТОПЗП ЙУРПМШЪПЧБОЙС, ЛПНРБЛФОПУФШ Java ЛПДБ РТЙ ТБЪТБВПФЛЕ Й ЙОУФТХНЕОФЩ ТБЪТБВПФЛЙ У ЙУРПМШЪПЧБОЙЕН УФБОДБТФОЩИ ЫБВМПОПЧ, ОП НПФЙЧЩ УРЕГЙЖЙЛБГЙЙ ВПМШЫЕ РПДИПДСФ ДМС ТЕЫЕОЙС ТБЪМЙЮОЩИ РТПВМЕН.
уФБОДБТФ, ПРТЕДЕМЕООЩК Ч НПДЕМЙ ЛПНРПОЕОФ JavaBeans РТЕДОБЪОБЮЕО ДМС УПЪДБОЙС РПЧФПТОПЗП ЙУРПМШЪПЧБОЙС ЛПНРПОЕОФ, ЛПФПТЩЕ ПВЩЮОП ЙУРПМШЪХАФУС Ч ЙОФЕЗТЙТПЧБООПК УТЕДЕ ТБЪТБВПФЛЙ Й ЮБУФП, ОП ОЕ ЧУЕЗДБ, СЧМСАФУС ЧЙЪХБМШОЩНЙ ЛПНРПОЕОФБНЙ.
уРЕГЙЖЙЛБГЙС Enterprise JavaBeans ПРТЕДЕМСЕФ НПДЕМШ ЛПНРПОЕОФПЧ ДМС ТБЪТБВПФЛЙ Java ЛПДБ УФПТПОЩ УЕТЧЕТБ. рПУЛПМШЛХ EJB НПЗХФ РПФЕОГЙБМШОП ЪБРХУЛБФШУС ОБ ТБЪМЙЮОЩИ УЕТЧЕТОЩИ РМБФЖПТНБИ — ЧЛМАЮБС ГЕОФТБМШОЩЕ НБЫЙОЩ, ЛПФПТЩЕ ОЕ ЙНЕАФ ЧЙЪХБМШОЩИ ДЙУРМЕЕЧ — EJB ОЕ НПЦЕФ ЙУРПМШЪПЧБФШ ЗТБЖЙЮЕУЛЙЕ ВЙВМЙПФЕЛЙ, ФЙРБ AWT ЙМЙ Swing.
уРЕГЙЖЙЛБГЙС Enterprise JavaBeans ПРЙУЩЧБЕФ НПДЕМШ ЛПНРПОЕОФПЧ УФПТПОЩ УЕТЧЕТБ. пОБ ПРТЕДЕМСЕФ ЫЕУФШ ТПМЕК, ЛПФПТЩЕ ЙУРПМШЪХАФУС ДМС ЧЩРПМОЕОЙС ЪБДБЮ РТЙ ТБЪТБВПФЛЕ Й ТБЪЧЕТФЩЧБОЙЙ, ФБЛ ЦЕ ПРТЕДЕМСЕФ ЛПНРПОЕОФЩ УЙУФЕНЩ. ьФЙ ТПМЙ ЙУРПМШЪХАФУС Ч ТБЪТБВПФЛЕ, ТБЪЧЕТФЩЧБОЙЙ Й ЪБРХУЛЕ ТБУРТЕДЕМЕООЩИ УЙУФЕН. рТПЙЪЧПДЙФЕМЙ, БДНЙОЙУФТБФПТЩ Й ТБЪТБВПФЮЙЛЙ ЙЗТБАФ ТБЪОЩЕ ТПМЙ, РПЪЧПМСС ТБЪДЕМСФШ ФЕИОПМПЗЙА Й ПВМБУФШ ЪОБОЙК. рТПДБЧЕГ ПВЕУРЕЮЙЧБЕФ ФЕИОЙЮЕУЛПЕ ТБВПЮЕЕ РТПУФТБОУФЧП, Б ТБЪТБВПФЮЙЛ УПЪДБЕФ УРЕГЙЖЙЮОЩЕ ДМС ДБООПК ПВМБУФЙ ЛПНРПОЕОФЩ, ОБРТЙНЕТ, ЛПНРПОЕОФ “УЮЕФ”. фБ ЦЕ УБНБ ЛПНРБОЙС НПЦЕФ ЧЩРПМОСФШ ПДОХ ЙМЙ ОЕУЛПМШЛП ТПМЕК. тПМЙ, ПРТЕДЕМЕООЩЕ Ч УРЕГЙЖЙЛБГЙЙ EJB УЧЕДЕОЩ Ч УМЕДХАЭХА ФБВМЙГХ:
|
тПМШ |
пФЧЕУФЧЕООПУФШ |
|---|---|
|
рПУФБЧЭЙЛ Enterprise Bean |
тБЪТБВПФЮЙЛ ПФЧЕЮБЕФ ЪБ УПЪДБОЙЕ EJB ЛПНРПОЕОФ РПЧФПТОПЗП ЙУРПМШЪПЧБОЙС. ьФЙ ЛПНРПОЕОФЩ ХРБЛПЧБОЩ Ч УРЕГЙБМШОЩК jar ЖБКМ (ejb-jar ЖБКМ). |
|
уВПТЭЙЛ РТЙМПЦЕОЙС |
уПЪДБЕФ Й УПВЙТБЕФ РТЙМПЦЕОЙЕ ЙЪ ОБВПТБ ejb-jar ЖБКМПЧ. ьФП ЧЛМАЮБЕФ ОБРЙУБОЙЕ РТЙМПЦЕОЙК, ЛПФПТЩЕ ХФЙМЙЪЙТХАФ ОБВПТ EJB (ОБРЙНЕТ, УЕТЧМЕФПЧ, JSP, Swing Й Ф.Д., Й Ф.Р.). |
|
хУФБОПЧЭЙЛ |
вЕТЕФ ОБВПТ ejb-jar ЖБКМПЧ ПФ УВПТЭЙЛБ Й/ЙМЙ рПУФБЧЭЙЛБ Bean Й ТБЪЧПТБЮЙЧБЕФ ЙИ Ч УТЕДЕ ЧТЕНЕОЙ ЧЩРМОЕОЙС: ПДЙО ЙМЙ ОЕУЛПМШЛП EJB лПОФЕКОЕТПЧ. |
|
EJB лПОФЕКОЕТ/рПУФБЧЭЙЛ УЕТЧЕТБ |
рТЕДПУФБЧМСЕФ УТЕДХ ЧТЕНЕОЙ ЧЩРПМОЕОЙС Й ЙОУФТХНЕОФЩ, ЙУРПМШЪХЕНЩЕ ДМС ТБЪЧЕТФЩЧБОЙС, БДНЙОЙУФТЙТПЧБОЙС Й ЪБРХУЛБ EJB ЛПНРПОЕОФ. |
|
уЙУФЕНОЩК БДНЙОЙУФТБФПТ |
хРТБЧМСЕФ ТБЪМЙЮОЩНЙ ЛПНРПОЕОФБНЙ Й УМХЦВБНЙ, ЮФПВЩ ПОЙ ВЩМЙ УЛПОЖЙЗХТЙТПЧБОЩ Й РТБЧЙМШОП ЧЪБЙНПДЕКУФЧПЧБМЙ, ФБЛЦЕ УМЕДЙФ, ЮФПВЩ УЙУФЕНБ ТБВПФБМБ ЛПТТЕЛФОП. |
EJB ЛПНРПОЕОФЩ СЧМСАФУС НОПЗПЛТБФОП ЙУРПМШЪХЕНЩНЙ ЬМЕНЕОФБНЙ ВЙЪОЕУ-МПЗЙЛЙ, ЛПФПТЩЕ ЦЕУФЛП УМЕДХАФ УФБОДБТФБН Й ЫБВМПОБН ТБЪТБВПФЛЙ, ПРТЕДЕМЕООЩН Ч УРЕГЙЖЙЛБГЙЙ EJB. ьФП РПЪЧПМСЕФ ЛПНРПОЕОФБН ВЩФШ РЕТЕОПУЙНЩНЙ. ьФП ФБЛЦЕ РПЪЧПМСЕФ ДТХЗЙН УМХЦВБН — ФБЛЙН ЛБЛ ВЕЪПРБУОПУФШ, ЛЬЫЙТПЧБОЙЕ Й ТБУРТЕДЕМЕООЩЕ ФТБОЪБЛГЙЙ — ТБВПФБФШ У РПМШЪП ДМС ЛПНРПОЕОФ. рПУФБЧЭЙЛ Enterprise Bean ПФЧЕЮБЕФ ЪБ ТБЪТБВПФЛХ EJB ЛПНРПОЕОФ.
EJB лПОФЕКОЕТ РТЕДУФБЧМСЕФ ЙЪ УЕВС УТЕДХ ЧТЕНЕОЙ ЧЩРПМОЕОЙС, ЛПФПТБС УПДЕТЦЙФ Й ЪБРХУЛБЕФ EJB ЛПНРПОЕОФЩ Й РТЕДПУФБЧМСЕФ ОБВПТ УФБОДБТФОЩИ УМХЦВ ДМС ЬФЙИ ЛПНРПОЕОФ. пВСЪБООПУФЙ EJB лПОФЕКОЕТБ ЮЕФЛП ПРТЕДЕМЕОЩ Ч УРЕГЙЖЙЛБГЙЙ, ЮФПВЩ ПВЕУРЕЮЙФШ ОЕКФТБМЙФЕФ РТПЙЪЧПДЙФЕМС. EJB ЛПОФЕКОЕТ РТЕДПУФБЧМСЕФ ОЙЪЛПХТПЧОЕЧПЕ “ПВУМХЦЙЧБОЙЕ” EJB, ЧЛМАЮБС ТБУРТЕДЕМЕООЩЕ ФТБОЪБЛГЙЙ, ВЕЪПРБУОПУФШ, ХРТБЧМЕОЙЕ ГЙЛМПН ЦЙЪОЙ ЛПНРПОЕОФБ, ЛЬЫЙТПЧБОЙЕ, ОЙФЙ РТПГЕУУПЧ Й ХРТБЧМЕОЙЕ УЕУУЙСНЙ. рПУФБЧЭЙЛ EJB лПОЕФКОЕТБ ПФЧЕЮБЕФ ЪБ РТЕДПУФБЧМЕОЙЕ EJB лПОФЕКОЕТБ.
EJB уЕТЧЕТ ПРТЕДЕМСЕФУС ЛБЛ уЕТЧЕТ рТЙМПЦЕОЙК, ЛПФПТЩК УПДЕТЦЙФ Й ЪБРХУЛБЕФ ПДЙО ЙМЙ ОЕУЛПМШЛП EJB лПОФЕКОЕТПЧ. рПУФБЧЭЙЛ EJB уЕТЧЕТБ ПФЧЕЮБЕФ ЪБ РТЕДПУФБЧМЕОЙЕ EJB уЕТЧЕТБ. чЩ НПЦЕФЕ РПМБЗБФШ, ЮФП EJB лПОФЕКОЕТ Й EJB уЕТЧЕТ ЬФП ПДОП Й ФП ЦЕ.
Java Naming and Directory Interface (JNDI) ЙУРПМШЪХЕФУС Ч Enterprise JavaBeans Ч ЛБЮЕУФЧЕ УМХЦВЩ ХЛБЪБОЙС ЙНЕО ДМС EJB ЛПНРПОЕОФ Ч УЕФЙ Й ДТХЗЙИ УМХЦВБИ ЛПОФЕКОЕТБ, ФБЛЙИ ЛБЛ ФТБОЪБЛГЙЙ. JNDI ТБВПФБЕФ ПЮЕОШ РПИПЦЕ У ДТХЗЙНЙ УФБОДБТФБНЙ, ФБЛЙНЙ ЛБЛ CORBA CosNaming, Й НПЦЕФ ОБ УБНПН ДЕМЕ ВЩФШ ТЕБМЙЪПЧБО Ч ЧЙДЕ ОБДУФТПКЛЙ ОБД ОЙН.
JTA/JTS ЙУРПМШЪХАФУС Ч Enterprise JavaBeans Ч ЛБЮЕУФЧЕ API ФТБОЪБЛГЙЙ. рПУФБЧЭЙЛ Enterprise Bean НПЦЕФ ЙУРПМШЪПЧБФШ JTS ДМС УПЪДБОЙС ЛПДБ ФТБОЪБЛГЙЙ, ИПФС EJB лПОФЕКОЕТ ЮБЭЕ ЧУЕЗП ТЕБМЙЪХЕФ ФТБОЪБЛГЙА Ч EJB ОБ РПМЕЪОЩИ EJB ЛПНРПОЕОФБИ. хУФБОПЧЭЙЛ НПЦЕФ ПРТЕДЕМЙФШ БФТВХФЩ ФТБОЪБЛГЙЙ EJB ЛПНРПОЕОФБ ЧП ЧТЕНС ТБЪЧЕТФЩЧБОЙС. EJB лПОФЕКОЕТ ПФЧЕЮБЕФ ЪБ ПВТБВПФЛХ ФТБЪБЛГЙЙ ОЕ ЪБЧЙУЙНП ПФ ФПЗП, СЧМСЕФУС МЙ ПОБ МПЛБМШОПК ЙМЙ ТБУРТЕДЕМЕООПК. уРЕГЙЖЙЛБГЙС JTS СЧМСЕФУС Java ПФПВТБЦЕОЙЕН ОБ CORBA OTS (Object Transaction Service).
уРЕГЙЖЙЛБГЙС EJB ПРТЕДЕМСЕФ ЧЪБЙНПДЕКУФЧЙЕ У CORBA ЮЕТЕЪ УПЧНЕУФЙНПУФШ У CORBA РТПФПЛПМБНЙ. ьФП ДПУФЙЗОХФП РХФЕН УПЧНЕЭЕОЙС EJB УМХЦВ, ФБЛЙИ ЛБЛ JTS Й JNDI, У УППФЧЕУФЧХАЭЙНЙ УМХЦВБНЙ CORBA Й ТЕБМЙЪБГЙЕК RMI РПЧЕТИ IIOP РТПФПЛПМБ CORBA.
йУРПМШЪПЧБОЙЕ CORBA Й RMI/IIOP Ч Enterprise JavaBeans ТЕБМЙЪПЧБОП Ч EJB лПОФЕКОЕТЕ Й ЪБ ЬФП ПФЧЕЮБЕФ РПУФБЧЭЙЛ EJB лПФЕКОЕТБ. йУРПМШЪПЧБОЙЕ CORBA Й RMI/IIOP Ч EJB лПОФЕКОЕТЕ УРТСФБОП ПФ УБНПЗП EJB лПОФЕКОЕТБ. ьФП ПЪОБЮБЕФ, ЮФП рПУФБЧЭЙЛ Enterprise Bean НПЦЕФ ОБРЙУБФШ УЧПК EJB лПНРПОЕОФ Й ТБЪЧЕТОХФШ ЕЗП Ч МАВПН EJB лПОФЕКОЕТЕ ОЕ ЪБВПФСУШ П ФПН, ЛБЛЙЕ ЛПННХОЙЛБГЙПООЩЕ РТППЛПМЩ ПО ЙУРПМШЪХЕФ.
EJB УПУФПЙФ ЙЪ ОЕУЛПМШЛЙИ ЮБУФЕК, ЧЛМАЮБС УБН ЛПНРПОЕОФ, ТЕБМЙЪБГЙА ОЕЛПФПТЩИ ЙОФЕТЖЕКУПЧ Й ЙОЖПТНБГЙПООЩК ЖБКМ. чУЕ ЬФП РБЛХЕФУС ЧНЕУФЕ Ч УРЕГЙБМШОЩК jar ЖБКМ.
Enterprise Bean СЧМСЕФУС Java ЛМБУУПН, ТБЪТБВПФБООЩН рПУФБЧЭЙЛПН Enterprise Bean. пО ТЕБМЙЪХЕФ ЙОФЕТЖЕКУ Enterprise Bean Й ПВЕУРЕЮЙЧБЕФ ТЕБМЙЪБГЙА ВЙЪОЕУ-НЕФПДПЧ, ЛПФПТЩЕ ЧЩРПМОСЕФ ЛПНРПОЕОФ. лМБУУ ОЕ ТЕБМЙЪХЕФ ОЙЛБЛХА БЧФПТЙЪБГЙА, НОПЗПРПФПЮОПУФШ ЙМЙ ЛПД ФТБОЪБЛГЙЙ.
лБЦДЩК УПДБАЭЙКУС Enterprise Bean ДПМЦЕО ЙНЕФШ БУУПГЙЙТПЧБООЩК ДПНБЫОЙК ЙОФЕТЖЕКУ. дПНБЫОЙК ЙОФЕТЖЕКУ ЙУРПМШЪХЕФУС ЛБЛ ЖБВТЙЛБ ДМС ЧБЫЕЗП EJB. лМЙЕОФ ЙУРПМШЪХЕФ дПНБЫОЙК ЙОФЕТЖЕКУ ДМС ОБИПЦДЕОЙС ЬЛЪЕНРМСТБ ЧБЫЕЗП EJB ЙМЙ УПЪДБОЙС ОПЧПЗП ЬЛЪЕНРМСТБ ЧБЫЕЗП EJB.
хДБМЕООЩК ЙОФЕТЖЕКУ СЧМСЕФУС Java йОФЕТЖЕКУПН, ЛПФПТЩК ПФПВТБЦБЕФ ЮЕТЕЪ ТЕЖМЕЛУЙА ФЕ НЕФПДЩ ЧБЫЕЗП Enterprise Bean, ЛПФПТЩЕ ЧЩ ИПФЙФЕ РПЛБЪЩЧБФШ ЧОЕЫОЕНХ НЙТХ. хДБМЕООЩК ЙОФТЖЕКУ ЙЗТБЕФ ФХ ЦЕ ТПМШ, ЮФП Й IDL ЙОФЕТЖЕКУ Ч CORBA.
пРЙУБФЕМШ ТБЪЧЕТФЩЧБЙС СЧМСЕФУС XML ЖБКМПН, ЛПФПТЩК УПДЕТЦЙФ ЙОЖПТНБГЙА ПФОПУЙФЕМШОП ЧБЫЕЗП EJB. йУРПМЪПЧБОЙЕ XML РПЪЧПМСЕФ ХУФБОПЧЭЙЛХ МЕЗЛП НЕОСФШ БФТЙВХФЩ ЧБЫЕЗП EJB. лПОЖЙЗХТБГЙПООЩЕ БФТЙВХФЩ, ПРТЕДЕМЕОЩЕ Ч ПРЙУБФЕМЕ ТБЪЧЕТФЩЧБОЙС, ЧЛМАЮБАФ:
EJB-Jar ЖБКМ - ЬФП ПВЩЮОЩК java jar ЖБКМ, ЛПФПТЩК УПДЕТЦЙФ
ЧБЫ EJB, дПНБЫОЙК Й хДБМЕООЩК ЙОФЕТЖЕКУЩ ОБТСДХ У ПРЙУБФЕМЕН ТБЪЧЕТФЩЧБОЙС.
рПУМЕ ФПЗП, ЛБЛ ЧЩ РПМХЮЙМЙ EJB-Jar ЖБКМ, УПДЕТЦБЭЙК ЛПНРПОЕОФ, дПНБЫОЙК Й хДБМЕООЩК ЙОФЕТЖЕКУЩ Й ПРЙУБФЕШ ТБЪЧЕТФЩЧБОЙС, ЧЩ НПЦЕФЕ УМПЦЙФШ ЧУЕ ЮБУФЙ ЧНЕУФЕ Й Ч РТПГЕУУЕ РПОСФШ, ДМС ЮЕЗП ОХЦОЩ дПНБЫОЙК Й хДБМЕООЩК ЙОФЕТЖЕКУЩ Й ЛБЛ EJB лПОФЕКОЕТ ЙУРПМШЪХЕФ ЙИ.
EJB лПОФЕКОЕТ ТЕБМЙЪХЕФ дПНБЫОЙК Й хДБМЕООЩК ЙОФЕТЖЕКУЩ, ЛПФПТЩЕ ЕУФШ Ч EJB-Jar ЖБКМЕ. лБЛ ХРПНЙОБМПУШ ТБОЕЕ, дПНБЫОЙК ЙОФЕТЖЕКУ ПВЕУРЕЮЙЧБЕФ НЕФПДЩ ДМС УПЪДБОЙС Й ОБИПЦДЕОЙС ЧБЫЕЗП EJB. ьФП ПЪОБЮБЕФ, ЮФП EJB лПОФЕКОЕТ ПФЧЕЮБЕФ ЪБ ХТБЧМЕОЙЕ ЦЙЪОЕООЩН ГЙЛМПН ЧБЫЕЗП EJB. ьФПФ ХТПЧЕОШ ОЕОБРТБЧМЕООПУФЙ РПЪЧПМСЕФ ХЮЙФЩЧБФШ РТПЙУИПДСЭХА ПРФЙНЙЪБГЙА. оБРТЙНЕТ, 5 ЛМЙЕОФПЧ НПЗХФ ПДОПЧТЕНЕООП ЪБРТПУЙФШ ПРТЕДЕМЕООЩК EJB ЮЕТЕЪ дПНБЫОЙК ЙОФЕТЖЕКУ, Б EJB лПОФЕКОЕТ ДПМЦЕО ПФЧЕФЙФШ УПЪДБОЙЕН ФПМШЛП ПДПЗП EJB Й ТБУРТЕДЕМЕОЙЕН ЕЗП НЕЦДХ 5 ЛМЙЕОФБНЙ. ьФП ДПУФЙЗБЕФУС ЮЕТЕЪ хДБМЕООЩК ЙОФЕТЖЕКУ, ЛПФПТЩК ФБЛ ЦЕ ТЕБМЙЪХЕФУС ЮЕТЕЪ EJB лПОФЕКОЕТ. тЕБМЙЪПЧБООЩК хДБМЕООЩК ПВЯЕЛФ ЙЗТБЕФ ТПМШ ДПЧЕТФЕМШОПЗП ПВЯЕЛФБ ДМС EJB.
чУЕ ЧЩЪПЧЩ EJB ‘РТПЛУЙТХВФУС(proxied)’ ЮЕТЕЪ EJB лПОФЕКОЕТ РПУТЕДУФЧПН дПНБЫОЕЗП Й хДБМЕООПЗП ЙОФЕТЖЕКУБ. ьФПФ ПВИПДОПК РХФШ СЧМСЕФУС РТЙЮЙОПК ФПЗП, ЮФП EJB ЛПОФЕКОЕТ НПЦЕФ ХРТБЧМСФШ ВЕЪПРБУОПУФША Й РПЧЕДЕОЙЕН ФТБОЪБЛГЙК.
уРЕГЙЖЙЛБГЙС Enterprise JavaBeans ПРТЕДЕМСЕФ ТБЪМЙЮОЩЕ ФЙРЩ EJB, ЛПФПТЩЕ ЙНЕАФ ТБЪЙЮОЩЕ ИБТБЛФЕТЙУФЙЛЙ Й РПЧЕДЕОЙЕ. ч УРЕГЙЖЙЛБГЙЙ ПРТЕДЕМЕОЩ ДЧЕ ЛБФЕЗПТЙЙ EJB: уЕУУЙПООЩК лПНРПОЕОФ Й уХЭОПУФОЩК лПНРПОЕОФ. лБЦДБС ЛБФЕЗПТЙС ЙНЕЕФ УЧПЙ ЧБТЙБОФЩ.
уЕУУЙПООЩК ЛПНРПОЕОФ ЙУРПМШЪХЕФУС ДМС РТЕДУФБЧМЕОЙС УМХЮБЕЧ ЙУРПМШЪПЧБОЙС ЙМЙ РПТСДПЛБ ЧЩРПМОСЕЩИ ДЕКУФЧЙК У РПШЪПК ДМС ЛМЙЕОФБ. пОЙ РТЕДУФБЧМСАФ ПРЕТБГЙЙ У РПУФПСООЩНЙ ДБООЩНЙ, ОП ОЕ УБНЙ РПУФПСООЩЕ ДБООЩЕ. еУФШ ДЧБ ФЙРБ уЕУУЙПООЩИ лПНРПОЕОФПЧ: вЕЪ уПУФПСОЙС(Stateless) Й рПМОПЗП уПУФПСОЙС(Stateful). чУЕ уЕУУЙПООЩЕ лПНРПОЕОФЩ ДПМЦОЩ ТЕБМЙЪПЧЩЧБФШ ЙОФЕТЖЕКУ javax.ejb.SessionBean. EJB лПОФЕКОЕТ ХРТБЧМСЕФ ЦЙЪОША уЕУУЙПООПЗП лПНРПОЕОФБ.
уЕУУЙПООЩК лПНРПОЕОФ вЕЪ уПУФПСОЙС - ЬФП УБНЩК РТПУФПК Ч ТЕБМЙЪБГЙЙ ФЙР EJB ЛПНРПОЕОФБ . пО ОЕ УПДЕТЦЙФ ОЙЛБЛЙИ ЪОБЮЙНЩИ УПУФПСОЙК ДМС ЛМЙЕОФБ НЕЦДХ ЧЩЪПЧБНЙ НЕФПДПЧ, ФБЛ ЮФП ПОЙ МЕЗЛП ЙУРПМШЪХАФУС РПЧФПТОП ОБ УФПТПОЕ УЕТЧЕТБ Й РПЬФПНХ ПОЙ НПЗХФ ЛЬЫЙТПЧБФШУС, ПОЙ МЕЗЛП НБУЫФБВЙТХАФУС РТЙ ОЕПВИПДЙНПУФЙ. лПЗДБ ЙУРПМШЪХЕФЕ уЕУУЙПООЩЕ лПНРПОЕОФЩ вЕЪ уПУФПСОЙС, ЧУЕ УПУФПСОЙС НПЦОП ИТБОЙФШ ЧОЕ EJB.
уЕУУЙПООЩК лПНРПОЕОФ рПМОПЗП уПУФПСОЙС УПДЕТЦЙФ УПУФПСОЙЕ НЕЦДХ ЧЩЪПЧБНЙ. пОЙ ЙНЕАФ МПЗЙЛХ ПДЙО Л ПДОПНХ ДМС ЛМЙЕОФПЧ Й НПЗХФ УПДЕТЦБФШ УПУФПСОЙС Ч УЕВЕ. EJB лМОФЕКОЕТ ПФЧЕФУФЧЕОЕО ЪБ ПВЯЕДЙОЕОЙЕ Й ЛЬЫЙТПЧБОЙЕ уЕУУЙПООЩИ лПНРПОЕОФПЧ рПМОПЗП уПУФПСОЙС, ЮФП ДПУФЙЗБЕФУС ЮЕТЕЪ оЕБЛФЙЧОПУФШ Й бЛФЙЧОПУФШ. еУМЙ EJB лПОФЕКОЕТ ТХЫЙФШУС, ДБООЩЕ ЧУЕИ EJB уЕУУЙПООЩИ лПНРПОЕОФПЧ рПМОПЗП уПУФПСОЙС НПЗХФ ВЩФШ РПФЕТСОЩ. оЕЛПФПТЩЕ ЧЩУПЛПХТПЧОЕЧЩЕ EJB лПОФЕКОЕТЩ ПВЕУРЕЮЙЧБАФ ЧПУУФБОПЧМЕОЙЕ уЕУУЙПООЩИ лПНРПОЕОФПЧ рПМОПЗП уПУФПСОЙС.
уХЭОПУФОЩЕ ЛПНРПОЕОФЩ СЧМСАФУС ЛПНРПОЕОФБНЙ, РТЕДУФБЧМСАЭЙЕ РПУФПСООЩЕ ДБОЩЕ Й ЙИ РПЧЕДЕОЙЕ. уХЭОПУФОЩЕ ЛПНРПОЕОФЩ НПЗХФ ВЩФШ ТБЪДЕМЕОЩ НЕЦДХ НОПЗПНЙ ЛМЙЕОФБНЙ, ФПЮОП ФБЛ ЦЕ ЛБЛ НПЗХФ ТБЪДЕМСФШУС ДБООЩЕ Ч ВБЪЕ ДБООЩИ. EJB лПОФЕКОЕТ ПФЧЕЮБЕФ ЪБ ЛЬЫЙТПЧБОЙЕ уХЭОПУФОЩИ пВЯЕЛФПЧ Й ЪБ РПДДЕТЦЛПК ЙОФЕЗТЙТПЧБОЙС уХЭОПУФОЩИ лПНРПОЕОФПЧ. уХЭЕУФЧПЧБОЙЕ уХЭОПУФОЩИ лПНРПОЕОФПЧ ПРТЕДЕМСЕФУС EJB лПОФЕКОЕТПН, ФБЛ ЮФП ЕУМЙ EJB лПОФЕКОЕТ ТХЫЙФУС, уХЭОПУФОЩЕ лПНРПОЕОФЩ ВХДХФ ДПУФХРОЩ ФПМШЛП ФПЗДБ, ЛПЗДБ ВХДЕФ ДПУФХРЕО EJB лПОФЕКОЕТ.
еУФШ ДЧБ ФЙРБ уХЭОПУФОЩИ лПНРПОЕОФ: УХЭЕУФЧХАЭЙЕ У хРТБЧМЕОЙЕН
лПОФЕКОЕТБ (Container Managed persistence) Й УХЭЕУФЧХАЭЙЕ У хРТБЧМЕОЙЕН лПНРПОЕОФБНЙ
(Bean-Managed persistence).
Container Managed Persistence (CMP). CMP уХЭОПУФОЩЕ лПНРПОЕОФЩ ТЕБМЙЪПЧБОЩ У ЧЩЗПДПК ДМС EJB лПОФЕКОЕТБ. юЕТЕЪ ХЛБЪБООЩЕ Ч ПРЙУБОЙЙ ТБЪЧЕТФЩЧБОЙС УРЕГЙЖЙЛБГЙЙ, EJB лПОФЕКОЕТ УЧСЪЩЧБЕФ БФТЙВХФЩ уХЭОПУФОЩИ лПНРПОЕОФ У ОЕЛПФПТЩН РПУФПСООЩН ИТБОЙМЙЭЕН (ПВЩЮОП — ОП ОЕ ЧУЕЗДБ — ЬФП ВБЪБ ДБООЩИ). CMP УОЙЦБЕФ ЧТЕНС ТБЪТБВПФЛЙ ДМС EJB, ФБЛ ЦЕ, ЛБЛ Й ЪОБЮЙФЕМШОП УОЙЦБЕФ ЮЙУМП ФТЕВХЕНПЗП ЛПДБ.
Bean Managed Persistence (BMP). BMP уХЭОПУФОЩЕ лПНРПОЕОФЩ ТЕБМЙЪПЧЩЧБАФУС рПУФБЧЭЙЛПН Enterprise Bean. рПУФБЧЭЙЛ Enterprise Bean ПФЧЕЮБЕФ ЪБ ТЕБМЙЪБГЙА МПЗЙЛЙ, ФТЕВХЕНПК ДМС УПЪДБОЙС ОПЧЩИ EJB, ЙЪНЕОЕОЙС ОЕЛПФПТЩИ БФТЙВХФПЧ EJB, ХДБМЕОЙЕ EJB Й ОБИПЦДЕОЙЕ EJB Ч РПУФПСООПН ИТБОЙМЙЭЕ. пВЩЮОП ДМС ЬФПЗП ФТЕВХЕФУС ОБРЙУБОЙЕ JDBC ЛПДБ ДМС ЧЪБЙНПДЕКУФЧЙС У ВБЪПК ДБООЩИ ЙМЙ ДТХЗЙН РПУФПСООЩН ИТБОЙМЙЭЕН. у РПНПЭША BMP ТБЪТБВПФЮЙЛ ЙНЕЕФ РПМОЩК ЛПОФТПМШ ОБД ХРТБЧМЕОЙЕН УХЭЕУФЧПЧБОЙС уХЭОПУФОПЗП пВЯЕЛФБ.
BMP ФБЛЦЕ ДБЕФ ЗЙВЛПУФШ Ч ФЕИ НЕУФБИ, ЗДЕ ТЕБМЙЪБГЙС CMP ОЕ НПЦЕФ ВЩФШ ЙУРПМШЪПЧБОБ. оБРТЙНЕТ, ЕУМЙ ЧЩ ИПФЙФЕ УПЪДБФШ EJB, ЛПФПТЩК ЧЛМАЮБЕФ Ч УЕВС ОЕЛЙК ЛПД УХЭЕУФЧХАЭЕК ЗМБЧОПК УЙУФЕНЩ, ЧЩ ДПМЦОЩ ОБРЙУБФШ ЧБЫХ ХУФПКЮЙЧПУШ, ЙУРПМШЪХС CORBA.
ч ЛБЮЕУФЧЕ РТЙНЕТБ ВХДЕФ ТЕБМЙЪПЧБО EJB ЛПНРПОЕОФ “Perfect Time” ЙЪ РТЕДЩДХЭЕЗП ТБЪДЕМБ, РПУЧСЭЕООПЗП RMI. рТЙНЕТ ВХДЕФ ЧЩРПМОЕО ЛБЛ уЕУУЙПООЩК лПНРПОЕОФ ВЕЪ уПУФПСОЙС.
лБЛ ХРПНЙОБМПУШ ТБОЕЕ, EJB ЛПНРПОЕОФЩ УПДЕТЦБФ ОЕ НЕОЕЕ ПДОПЗП ЛМБУУБ (EJB) Й ДЧХИ ЙОФЕТЖЕКУПЧ: хДБМЕООЩК Й дПНБЫОЙК ЙОФЕТЖЕКУЩ. лПЗДБ ЧЩ УПЪДБЕФЕ хДБМЕООЩК ЙОФЕТЖЕКУ ДМС EJB, ЧЩ ДПМЦОЩ УМЕДПЧБФШ УМЕДХАЭЙН РТЙОГЙРБН:
чПФ РТПУФПК ХДБМЕООЩК ЙОФЕТЖЕКУ ДМС PerfectTime EJB:
//: c15:ejb:PerfectTime.java
//# чЩ ДПМЦОЩ ХУФБОПЧЙФШ J2EE Java Enterprise
//# Edition У java.sun.com Й ДПВБЧЙФШ j2ee.jar
//# Ч ЧБЫХ РЕТЕНЕООХА CLASSPATH, ЮФПВЩ УЛПНРЙМЙТПЧБФШ
//# ЬФПФ ЖБКМ. рПДТПВОПУФЙ УНПФТЙФЕ ОБ java.sun.com.
// хДБМЕООЩК ЙОФЕТЖЕКУ ДМС PerfectTimeBean
import java.rmi.*;
import javax.ejb.*;
public interface PerfectTime extends EJBObject {
public long getPerfectTime()
throws RemoteException;
} ///:~
дПНБЫОЙК ЙОФЕТЖЕКУ СЧМСЕФУС ЖБВТЙЛПК ДМС УПЪДБОЙС ЛПНРПОЕОФБ. пО НПЦЕФ ПРТЕДЕМЙФШ НЕФПД create, ДМС УПЪДБОЙС ЬЛЪЕНРМСТБ EJB, ЙМЙ НЕФПД finder, ЛПФПТЩК ОБИПДЙФ УХЭЕУФЧХАЭЙК EJB Й ЙУРПМШЪХЕФУС ПМШЛП ДМС уХЭОПУФОЩИ лПНРПОЕОФ. лПЗДБ ЧЩ УПЪДБЕФЕ дПНБЫОЙК ЙОФЕТЖЕКУ ДМС EJB, ЧЩ ДПМЦОЩ УМЕДПЧБФШ УМЕДХАЭЙН РТЙОГЙРБН:
уФБОДБТФОПЕ УПЗМБЫЕОЙЕ ПВ ЙНЕОБИ дПНБЫОЙИ ЙОФЕТЖЕКУПЧ УПУФПЙФ Ч РТЙВБЧМЕОЙЙ УМПЧБ “Home” Ч ЛПОЕГ ЙНЕОЙ хДБМЕООПЗП ЙОФЕТЖЕКУБ. чПФ дПНБЫОЙК ЙОФЕТЖЕКУ ДМС PerfectTime EJB:
//: c15:ejb:PerfectTimeHome.java
// дПНБЫОЙК ЙОФЕТЖЕКУ PerfectTimeBean.
import java.rmi.*;
import javax.ejb.*;
public interface PerfectTimeHome extends EJBHome {
public PerfectTime create()
throws CreateException, RemoteException;
} ///:~
фЕРЕТШ ЧЩ НПЦЕФЕ ТЕБМЙЪПЧБФШ ВЙЪОЕУ МПЗЙЛХ. лПЗДБ ЧЩ УПЪДБЕФЕ ЧЩЫХ ТЕБМЙЪБГЙА EJB ЛМБУУБ, ЧЩ ДПМЦОЩ УМЕДПЧБФШ ЬФЙН ФТЕВПЧБОЙСН (ПВТБФЙФЕ ЧОЙНБОЙЕ, ЮФП ЧЩ ДПМЦОЩ ПВТБФЙФШУС Л УРЕГЙЖЙЛБГЙЙ EJB, ЮФПВЩ РПМХЮЙФШ РПМОЩК УРЙУПЛ ФТЕВПЧБОЙК РТЙ ТБЪТБВПФЛЕ Enterprise JavaBeans):
//: c15:ejb:PerfectTimeBean.java
// рТПУФПК Stateless Session Bean,
// ЧПЪЧТБЭБАЭЙК ФЕЛХЭЕЕ УЙУФЕНОПЕ ЧТЕНС.
import java.rmi.*;
import javax.ejb.*;
public class PerfectTimeBean
implements SessionBean {
private SessionContext sessionContext;
//ЧПЪЧТБЭБЕ ФЕЛХЭЕЕ ЧТЕНС
public long getPerfectTime() {
return System.currentTimeMillis();
}
// EJB НЕФПДЩ
public void ejbCreate()
throws CreateException {}
public void ejbRemove() {}
public void ejbActivate() {}
public void ejbPassivate() {}
public void
setSessionContext(SessionContext ctx) {
sessionContext = ctx;
}
}///:~
йЪ-ЪБ РТПУФПФЩ ЬФПЗП РТЙНЕТБ EJB НЕФПДЩ (ejbCreate( ), ejbRemove( ), ejbActivate( ), ejbPassivate( )) ПУФБЧМЕОЩ РХУФЩНЙ. ьФЙНЕФПДЩ ЧЩЪЩЧБАФУС EJB лПОФЕКОЕТПН Й ЙУРПМШЪХАФУС ДМС ХРТБЧМЕОЙС УПУФПСОЙЕН ЛПНРПОЕОФБ. нЕФПД setSessionContext( ) РЕТЕДБЕФ ПВЯЕЛФ javax.ejb.SessionContext, ЛПФПТЩК УПДЕТЦЙФ ЙОЖПТНБГЙА ПФОПУЙФЕМШОП ЛПОФЕЛУФБ ЛПНРПОЕОФБ, ФБЛХА ЛБЛ ФЕЛХЭБС ФТБОЪБЛГЙС Й ЙОЖПТНБГЙС ВЕЪПРБУОПУФЙ.
рПУМЕ ФПЗП, ЛБЛ НЩ УПЪДБМЙ Enterprise JavaBean, ОБН ОХЦОП УПЪДБФШ ПРЙУБФЕМШ ТБЪЧЕТФЩЧБОЙС. пРЙУБФЕМШ ТБЪЧЕТФЩЧБОЙС - ЬФП XML ЖБКМ, ЛПФТЩК ПРЙУЩЧБЕФ EJB ЛПНРПОЕОФ. пРЙУБФЕМШ ТБЪЧЕТФЩЧБОЙС ДПМЦЕО ИТБОЙФУС Ч ЖБКМЕ, ОБЪЩЧБЕНПН ejb-jar.xml.
//:! c15:ejb:ejb-jar.xml
<?xml version="1.0" encoding="Cp1252"?>
<!DOCTYPE ejb-jar PUBLIC '-
//Sun Microsystems, Inc.
//DTD Enterprise JavaBeans 1.1
//EN' 'http://java.sun.com/j2ee/dtds/ejb-jar_1_1.dtd'>
<ejb-jar>
<description>Example for Chapter 15</description>
<display-name></display-name>
<small-icon></small-icon>
<large-icon></large-icon>
<enterprise-beans>
<session>
<ejb-name>PerfectTime</ejb-name>
<home>PerfectTimeHome</home>
<remote>PerfectTime</remote>
<ejb-class>PerfectTimeBean</ejb-class>
<session-type>Stateless</session-type>
<transaction-type>Container</transaction-type>
</session>
</enterprise-beans>
<ejb-client-jar></ejb-client-jar>
</ejb-jar>
///:~
чЩ НПЦЕФЕ ЧЙДЕФШ, ЮФП лПНРПОЕОФ, хДБМЕООЩК ЙОФЕТЖЕКУ Й дПНБЫОЙК ЙОФЕТЖЕКУ ПРТЕДЕМЕОЩ ЧОХТЙ СТМЩЛБ <session> ЬФПЗП ПРЙУБФЕМС ТБЪЧЕТФЩЧБОЙС. пРЙУБФЕМШ ТБЪЧЕТФЩЧБОЙС НПЦЕФ ВЩФШ УЗЕОЕТЙТПЧБО БЧФПНБФЙЮЕУЛЙ РТЙ ЙУРПМШЪПЧБОЙЙ ЙОУФТХНЕОФПЧ ТБЪТБВПФЛЙ EJB.
оБТСДХ УП УФБОДБТФОЩН ПРЙУБФЕМЕН ТБЪЧЕТФЩЧБОЙС ejb-jar.xml, УРЕГЙЖЙЛБГЙС EJB ХУФБОБЧМЙЧБЕФ, ЮФП МАВЩЕ СТМЩЛЙ, УРЕГЙЖЙЮОЩЕ ДМС РТПЙЪЧПДЙФЕС, ДПМЦОЩ ИТБОЙФУС Ч ПФДЕМШОПН ЖБКМЕ. ьФП ПВЕУРЕЮЙЧБЕФ ЧЩУПЛХА УПЧНЕУФЙНПУФШ НЕЦДХ ЛПНРПОЕОФБНЙ Й EJB ЛПОФЕКОЕТБНЙ ТБЪМЙЮОЩИ НБТПЛ.
жБКМЩ ДПМЦОЩ ВЩФШ ЪББТИЙЧЙТПЧБОЩ ЧОХФТЙ УФБОДБТФОПЗП Java Archive (JAR) ЖБКМБ. пРЙУБФЕМШ ТБЪЧЕТФЩЧБОЙС ДПМЦЕО РПНЕЭБФШУС ЧОХФТЙ РПДДЙТЕЛФПТЙЙ /META-INF Jar.
рПУМЕ ФПЗП, ЛБЛ EJB ЛПНРПОЕОФ ПРТЕДЕМЕО Ч ПРЙУБФЕМЕ ТБЪЧЕТФЩЧБОЙС, ХУФБОПЧЭЙЛ НПЦЕФ ТБЪЧЕТОХФШ EJB ЛПНРПОЕОФ Ч EJB лПОФЕКОЕТЕ. ч ФП ЧТЕНС ,ЛПЗДБ ЬФП РЙУБМПУШ, РТПГЕУУ ХУФБОПЧЛЙ ВЩМ ДПУФБФПЮОП “GUI ЧЙЪХБМЙЪЙТПЧБООЩН” Й УРЕГЙЖЙЮОЩН ДМС ЛБЦДПЗП ЙОДЙЧЙДХБМШОПЗП EJB лПОФЕКОЕТБ, ФБЛ ЮФП ЬФПФ ПВЪПТ ОЕ ДПЛХНЕОФЙТХЕФ ЬФПФ РТПГЕУУ. пДОБЛП ЛБЦДЩК EJB лПОФЕКОЕТ ЙНЕЕФ ИПТПЫХА ДПЛХНЕОФБГЙА ДМС ТБЧЪЕТФЩЧБОЙС EJB.
рПУЛПМШЛХ EJB ЛПНРПОЕОФЩ СЧМСАФУС ТБУРТЕДЕМЕООЩНЙ ЛПНРПОЕОФБНЙ, РТПГЕУУ ХУФБОПЧЛЙ ДПМЦЕО ФБЛЦЕ УПЪДБЧБФШ ОЕЛПФЩЕ ЛМЙЕОФУЛЙЕ СЛПТС ДМС ЧЩЪПЧБ EJB ЛПНРПОЕОФ. ьФЙ ЛМБУУЩ ДПМЦОЩ РПНЕЭБФШУС Ч classpath ЛМЙЕОФУЛПЗП РТЙМПЦЕОЙС. рПУЛПМШЛХ EJB ЛПНРПОЕОФЩ НПЗХФ ТЕБМЙЪПЧЩЧБФШУС РПЧЕТИ RMI-IIOP (CORBA) ЙМЙ RMI-JRMP, ЗЕОЕТЙТХЕНЩЕ СЛПТС НПЗХФ ТБЪМЙЮБФШУС Ч ЪБЧЙУЙНПУФЙ ПФ EJB лПОФЕКОЕТБ, ФЕН ОЕ НЕОЕЕ, ПОЙ СЧМСАФУС ЗЕОЕТЙТХЕНЩНЙ ЛМБУУБНЙ.
лПЗДБ ЛМЙЕОФНЛБС РТПЗТБННБ ИПЮЕФ ЧЩЪЧБФШ EJB, ПОБ ДПМЦОБ ОБКФЙ EJB ЛПНРПОЕОФ ЧОХФТЙ JNDI Й РПМХЮЙФШ УУЩМЛХ ОБ ДПНБЫОЙК ЙОФЕТЖЕКУ EJB ЛПНРПОЕОФБ. дПНБЫОЙК ЙОФЕТЖЕКУ ЙУРПМШЪХЕФУС ДМС УПЪДБОЙС ЬЛЪЕНРМСТБ EJB.
ч ЬФПН РТЙНЕТЕ ЛМЙЕОФУЛБС РТПЗТБННБ - ЬФП РТПУФБС Java РТПЗТБННБ, ОП ЧЩ ДПМЦОЩ РПНОЙФШ, ЮФП ПОБ ФБЛ ЦЕ МЕЗЛП НПЦЕФ ВЩФШ УЕТЧМЕФПН, JSP ЙМЙ ДБЦЕ ТБУРТЕДЕМЕООЩН ПВЯЕЛФПН CORBA ЙМЙ RMI.
//: c15:ejb:PerfectTimeClient.java
// лМЙЕОФУЛБС РТПЗТБННБ ДМС PerfectTimeBean
public class PerfectTimeClient {
public static void main(String[] args)
throws Exception {
// рПМХЮЕОЙЕ ЛПОФЕЛУФБ JNDI У РПНПЭША
// JNDI УМХЦВЩ хЛБЪБОЙС йНЕО:
javax.naming.Context context =
new javax.naming.InitialContext();
// рПЙУЛ дПНБЫОЕЗП ЙОФЕТЖЕКУБ Ч
// УМХЦВЕ JNDI Naming:
Object ref = context.lookup("perfectTime");
// рТЙЧЕДЕОЙЕ ХДБМЕООПЗП ПВЯЕЛФБ Л ДПНБЫОЕНХ ЙФЕТЖЕКУХ:
PerfectTimeHome home = (PerfectTimeHome)
javax.rmi.PortableRemoteObject.narrow(
ref, PerfectTimeHome.class);
// уПЪДБОЙЕ ХДБМЕООПЗП ПВЯЕЛФБ ЙЪ ДПНБЫОЕЗП ЙОФЕТЖЕКУБ:
PerfectTime pt = home.create();
// чЩЪПЧ getPerfectTime()
System.out.println(
"Perfect Time EJB invoked, time is: " +
pt.getPerfectTime() );
}
} ///:~
рПУМЕДПЧБФЕМШОПУФШ ЧЩРПМОСЕНЩИ ДЕКУФЧЙК РПСУОСЕФУС ЛПННЕОФБТЙСНЙ. пВТБФЙФЕ ЧОЙНБОЙЕ ОБ ЙУРПМШЪПЧБОЙЕ НЕФПДБ narrow( ) ДМС УПЧЕТЫЕОЙС РТЙЧЕДЕОЙС ПВЯЕЛФБ РЕТЕД ЧЩРПМОЕОЙЕН Java РТЙЧЕДЕОЙС. ьФП ПЮЕОШ РПИПЦЕ ОБ ФП, ЮФП РТПЙУИПДЙФ Ч CORBA. фБЛЦЕ ПВТБФЙФЕ ЧОЙНБОЙЕ, ЮФП дПНБЫОЙК ПВЯЕЛФ УФБОПЧЙФУС ЖБВТЙЛПК ДМС ПВЯЕЛФБ PerfectTime.
уРЕГЙЖЙЛБГЙС Enterprise JavaBeans ЬФП ЛПТДЙОБМШОЩК ЫБЗ Л УФБОДБТФЙЪБГЙЙ ТБУРТЕДЕМЕООЩИ ПВЯЕЛФПЧ Й ХРТПЭЕОЙА ТБУРТЕДЕМЕООЩИ ЧЩЮЙУМЕОЙК. ьФП ПУОПЧОПК ЬМЕНЕОФ РМБФЖПТНЩ Java 2 Enterprise Edition (J2EE), ЛПФПТЩК РЙОЙНБЕФ ОБ УВС ПУОПЧОХА РПДДЕТЦЛХ ПВЭЕОЙС ТБУРТЕДЕМЕООЩИ ПВЯЕЛФПЧ. ч ОБУФПСЭЕЕ ЧТЕНС УХЭЕУФЧХАФ ЙМЙ РПСЧСФУС Ч ВЙЦБКЫЕН ВХДХЭЕН НОПЗЙЕ ЙОУФТХНЕОФЩ, РПНПЗБАЭЙЕ ХУЛПТЙФШ ТБЪТБВПФЛХ EJB ЛПНРПОЕОФПЧ.
ьФПФ ПВЪПТ СЧМСЕФУС ФПМШЛП ЛПТПФЛЙН ФХТПН РП EJB. вПМЕЕ РПТПВОП П УРЕГЙЖЙЛБГЙЙ EJB ЧЩ НПЦЕФЕ РПУНПФТЕФШ ОБ ПЖЙГЙБМШОПК УФТБОЙГЕ Enterprise JavaBeans РП БДТЕУХ java.sun.com/products/ejb/, ЗДЕ ЧЩ НПЦЕФЕ ЪБЗТХЪЙШ РПУМЕДОАА УРЕГЙЖЙЛБГЙА Й УУЩМЛХ ОБ ТЕБМЙЪБГЙА J2EE. пОЙ НПЗХФ ВЩФШ ЙУРПМШЪПЧБОЩ ДМС ТБЪТБВПФЛЙ Й ТБЪЧЕТФЩЧБОЙС ЧБЫЙИ УПВУФЧЕООЩИ EJB.
ьФПФ ТБЪДЕМ [78] ДБЕФ ЧБН ПВЪПТ ФЕИОПМПЗЙЙ Jini ПФ Sun Microsystems. ъДЕУШ ПРЙУБОЩ ОЕЛПФПТЩЕ ЬМЕНЕОФЩ Jini Й РПЛБЪБОП ЛБЛ Jini БТИЙФЕЛФХТБ РПНПЗБЕФ ХЧЕМЙЮЙФШ ХТПЧЕОШ БВУФТБЛГЙЙ Ч ТБУРТЕДЕМЕООПК УЙУФЕНЕ РТПЗТБННЙТПЧБОЙС, ЬЖЖЕЛФЙЧОП ЧЛМАЮБС УЕФЕЧПЕ РТПЗТБНЙТПЧБОЙЕ Ч ПВЯЕЛФОП-ПТЙЕОФЙТПЧБООПЕ РТПЗТБННЙТПЧБОЙЕ.
фТБДЙГЙПООП ПРЕТБГЙПООЩЕ УЙУФЕНЩ ВЩМЙ ТБЪТБВПФБОЩ Ч ФПН РТЙВМЙЦЕОЙЙ, ЮФП ЛПНРШАФЕТ ЙНЕЕФ РТПГЕУУПТ, ОЕЛПФПТХА РБНСФШ Й ДЙУЛ. лПЗДБ ЧЩ ЪБЗТХЦБЕФЕ ЛПНРШАФЕТ, РЕТЧПЕ, ЮФП ПО ДЕМБЕФ, ЬФП ЙЭЕФ ДЙУЛ. еУМЙ ПО ОЕ ОБИПДЙФ ДЙУЛ, ПО ОЕ НПЦЕФ ТБВПФБФШ, БЛ ЛПНРШАФЕТ. пДОБЛП ЛПНРШАФЕТЩ ЧУЕ ЮБЭЕ Й ЮБЭЕ РПСЧМСАФУС Ч ТБЪМЙЮОПН ПВМЙЛЕ: ЛБЛ ЧУФТПЕООЩЕ ХУФТПКУФЧБ У РТПГЕУУПТПН, РБНСФША, УЕФЕЧЩН УПЕДЙОЕОЙЕН — ОП ВЕЪ ДЙУЛБ. ОБРТЙНЕТ, РЕТЧПЕ, ЮФП ДЕМБЕФ ФЕМЕЖПО РТЙ РПДОСФЙЙ ФТХВЛЙ - ЬФП РПЙУЛ ФЕМЕЖПООПК УЕФЙ. еУМЙ ПО ОЕ ОБИПДЙФ УЕФЙ, ПО ОЕ НПЦЕФ ЖХОЛГЙПОЙТПЧБФШ ЛБЛ ФЕМЕЖПО. фБЛЙН ПВТБЪПН РТПЙУИПДЙФ ПФЛМПОЕОЙЕ Ч БРРБТБФОПН ХУФТПКУФЧЕ ПФ ЖЙЛУБГЙЙ ОБ ДЙУЛЕ Л ЖЙЛУБГЙЙ ОБ УЕФЙ, ЮФП УЛБЪЩЧБЕФУС ОБ ФПН, ЛБЛ ПТЗБОЙЪХЕФУС РТПЗТБНОПЕ ПВЕУРЕЮЕОЙЕ — Й ДМС ЬФПЗП ВЩМ УПЪДБО Jini.
Jini - ЬФП РПРЩФЛБ РЕТЕУФТПКЛЙ ЛПНРШАФЕТОПК БТИЙФЕЛФХТЩ, ДБАЭБС ХЧЙМЙЮЕОЙЕ ЧБЦОПУФЙ УЕФЙ Й ХЧЙМЙЮЕОЙЕ ЮЙУМБ РТПГЕУУПТПЧ Ч ХУФТПКУФЧЕ, ОЕ ЙНЕАЭЕН ДЙУЛПЧПДБ. фБЛЙН ХУФТПКУФЧБН, РПУФБЧМСЕНЩН НОПЗПНЙ РТПЙЪЧПДЙФЕМСНЙ, ОЕПВИПДЙНП ЧЪБЙНПЕКУФЧЙЕ РП УЕФЙ. уБНБ УЕФШ НПЦЕФ ВЩФШ ПЮЕОШ ДЙОБНЙЮОПК — ХУФТПКУФЧБ Й УМХЦВЩ ВХДХФ ТЕЗХМСТОП ДПВБЧМСФШУС Й ХДБМСФШУС. Jini ПВЕУРЕЮЙЧБЕФ НЕИБОЙЪН, РПЪЧПМСАЭЙК УЗМБЦЙЧБФШ ДПВБЧМЕОЙЕ, ХДБМЕОЙС Й ОБИПЦДЕОЙС ХУФТПКУФЧ Й УМХЦВ Ч УЕФЙ. лТПНЕ ФПЗП, Jini ПВЕУРЕЮЙЧБЕФ НПДЕМШ РТПЗТБННЙТПЧБОЙС, Ч ЛПФПТПК РТПЗТБННЙУФБН МЕЗЮЕ ЪБУФБЧЙФШ ЙИ ХУФТПКУФЧБ ПВЭБФШУС У ДТХЗЙНЙ.
рПУФТПЕООБС ОБ Java, УЕТЙБМЙЪБГЙЙ ПВЯЕЛФПЧ Й RMI (ЧУЕ ЧНЕУФЕ ЬФП РПЪЧПМСЕФ РЕТЕНЕЭБФШ ПВЯЕЛФЩ РП УЕФЙ ПФ ПДОПК ЧЙТФХБМШОПК НБЫЙОЩ Л ДТХЗПК) Jini РТПВХЕФ ТБУЫЙТСФШ ЧЩЗПДЩ ПВЯЕЛФОП-ПТЙЕОФЙТПЧБООПЗП РТПЗТБННЙТПЧБОЙС Ч УЕФЙ. чНЕУФП ФПЗП, ЮФПВЩ ФТЕВПЧБФШ ПФ РТПЙЪЧПДЙФЕМЕК УПЗМБУЙС ОБ РПДДЕТЦЛХ УЕФЕЧЩИ РТПФПЛПМПЧ, ЮЕТЕЪ ЛПФПТЩЕ ЙИ ХУФТПКУФЧБ НПЗМЙ ВЩ ЧЪБЙНПЦЕКУФЧПЧБФШ, Jini РПЪЧПМСЕФ ХУФТПКУЧФБН ЗПЧПТЙФШ ДТХЗ У ДТХЗПН ЮЕТЕЪ ЙОФЕТЖЕКУЩ ПВЯЕЛФПЧ.
Jini - ЬФП ОБВПТ API Й УЕФЕЧЩИ РТПФПЛПМПЧ, ЛПФПТЩЕ НПЗХФ РПНПЮШ ЧБН РПУФТПЙФШ Й ТБЪЧЕТОХФШ ТБУРТЕДЕМЕООХА УЙУФЕНХ, ПТЗБОЙЪПЧБООХА, ЛБЛ ЖЕДЕТБГЙС УЕТЧЙУПЧ. уЕТЧЙУЩ НПЗХФ ВЩФШ ЧУЕН, ЮФП УЙДЙФ Ч УЕФЙ Й ЗПФПЧП ЧЩРПМОЙФШ РПМЕЪОХА ЖХОЛГЙА. бРРБТБФОЩЕ ХУФТПКУФЧБ, РТПЗТБННЩ, ЛБОБМЩ УЧСЪЙ — ДБЦЕ УБНЙ РПМШЪПЧБФЕМЙ - МАДЙ — НПЗХФ ВЩФШ УЕТЧЙУБНЙ. оБРТЙНЕТ Jini-УПЧНЕУФЙНЩЕ ДЙУЛПЧПДЩ НПЗХФ РТЕДМБЗБФШ УЕТЧЙУ “ИТБОЕОЙС”. Jini-УПЧНЕУФЙНЩЕ РТЙОФЕТЩ НПЗХФ РТЕМБЗБФШ УЕТЧЙУ “ТБУРЕЮБФЛЙ”. фБЛЙН ПВТБЪПН, ЖЕДЕТБГЙС УМХЦВ СЧМСЕФУС ОБВПТПН УЕТЧЙУПЧ, ДПУФХРОЩИ Ч УЕФЙ Ч ДБООЩК НПНЕОФ, ЛПФПТЩНЙ НПЗХФ ЧПУРПМШЪЩЧБФШУС ЛМЙЕОФЩ (РПД ЛМЙЕОФБНЙ РПДТБЪХНЕЧБЕФУС РТПЗТБННЩ, УМХЦВЩ ЙМЙ РПМШЪПЧБФЕМЙ) ДМС ДПУФЙЦЕОЙС ОЕЛПФПТПК ГЕМЙ.
дМС ЧЩРПМОЕОЙС ЪБДБЮЙ ЛМЙЕОФЩ РТЙЧМЕЛБАФ ОБ РПНПЭШ УЕТЧЙУЩ. оБРТЙНЕТ, ЛМЙЕОФУЛЙЕ РТПЗТБННЩ НПЗХФ ЪБЗТХЦБФШ ЛТФЙОЛЙ ЙЪ ИТБОЙМЙЭБ ЙЪПВТБЦЕОЙК ГЙЖТПЧПК ЛБНЕТЩ, РЕТЕДБЧБФШ ЛБТФЙОЛЙ УМХЦВЕ РПУФПСООПЗП ИТБОЕОЙС, РТЕДБУФБЧМСЕНПК ДЙУЛПЧПДПН, Й РПУЩМБФШ УФТБОЙГХ ЬУЛЙЪПЧ ЖПФПЗТБЖЙК ТБЪМЙЮОЩИ ТБЪНЕТПЧ ДМС ТБУРЕЮБФЛЙ ОБ ГЧЕФОПН РТЙОФЕТЕ. ч ЬФПН РТЙНЕТЕ ЛМЙЕОФУЛБС РТПЗТБННБ РПУФТПЕОБ, ЛБЛ ТБУРТЕДЕМЕООБС УЙУФЕНБ, УПДЕТЦБЭБС Ч УЕВЕ УЕТЧЙУ ИТБОЕОЙС ЙЪПВТБЦЕОЙК, УЕТЧЙУ РПУФПСООПЗП ИТБОЕОЙС Й УЕТЧЙУ ГЧЕФОПК РЕЮБФЙ. лМЙЕОФЩ Й УЕТЧЙУЩ ЬФПК ТБУРТЕДЕМЕОПК УЙУФЕНЩ ТБВПФБАФ УПЧНЕУФОП ДМС ЧЩРПМОЕОЙС ЪБДБЮ: ЧЩЗТХЪЛЙ ИТБОЙНЩИ ЙЪПВТБЦЕОЙК ЙЪ ГЙЖТПЧПК ЛБНЕТЩ Й ТБУРЕЮБФЛБ УФТБОЙГ ЬУЛЙЪПЧ.
йДЕС, УФПСЭБС ЪБ НЙТПН ЖЕДЕТБГЙЙ, УПУФПЙФ Ч ФПН, ЮФП Jini РТПУНБФТЙЧБЕФ УЕФШ Й ОЕ ЧПЧМЕЛБЕФ ГЕОФТ ХРТБЧМЕОЙС. рПУЛПМШЛХ ОЕ ПДЙО ЙЪ УЕТЧЙУПЧ ОЕ ЪБЗТХЦБЕФУС, ОБВПТ ЧУЕИ УЕТЧЙУПЧ ДПУФХРЕО Ч УЕФЙ ЙЪ ЖЕДЕТБГЙЙ — ЗТХРРЩ, УПУФПСЭЕК ЙЪ ТБЧОЩИ ЬМЕНЕОФПЧ. чНЕУФП ГЕОФТБМОПК ЧМБУФЙ, ЙОЖТБУФТХЛФХТБ Jini ЧТЕНЕОЙ ЧЩРПМОЕОЙС РТПУФП ПВЕУРЕЮЙЧБЕФ УРПУПВ ДМС ЛМЙЕОФПЧ Й УЕТЧЙУПЧ ОБИПДЙФШ ДТХЗ ДТХЗБ (ЮЕТЕЪ УМХЦВХ РПЙУЛБ, ЛПФПТБС ИТБОЙФ УРТБЧПЮОЙЛ РПДДЕТЦЙЧБЕНЩИ Ч ОБУФПСЭЕЕ ЧТЕНС УЕТЧЙУПЧ). рПУМЕ ФПЗП, ЛБЛ ХУМХЗЙ ОБКДХФ ДТХЗ ДТХЗБ, ПОЙ УФБОПЧСФУС УПВУФЧЕООЩНЙ. лМЙЕОФ Й РТЙЧМЕЮЕООЩЕ ЙН УЕТЧЙУЩ ЧЩРПМОСАФ УЧПА ЪБДБЮХ ОЕЪБЧЙУЙНП ПФ ЙОЖТБУФТХЛФХТЩ Jini ЧТЕНЕОЙ ЧЩРПМОЕОЙС. еУМЙ УМХЦВБ РПЙУЛБ Jini РПФЕТРЙФ ЛТХЫЕОЙЕ, МАВБС ТБУРТЕДЕМЕООБС УЙУФЕНБ, УПВТБООБС ЮЕТЕЪ УЕТЧЙУ РПЙУЛБ ДП ЕЗП РБДЕОЙС, РТПДПМЦЙФ УЧПА ТБВПФХ. Jini ДБЦЕ ЧЛМАЮБЕФ УЕФЕЧПК РТПФПЛПМ, ЛПФПТЩК НПЗХФ ЙУРПМШЪПЧБФШ ЛМЙЕОФЩ ДМС ОБИПЦДЕОЙС УМХЦВ РТЙ ПФУХФУФЧЙЙ УМХЦВЩ РПЙУЛБ.
Jini ПРТЕДЕМСЕФ ЙЖТБУФТХЛФХТХ ЧТЕНЕОЙ ЧЩРПМОЕОЙС, ЛПФПТБС ТБУРПМБЗБЕФУС Ч УЕФЙ Й ПВЕУРЕЮЙЧБЕФ НЕИБОЙЪН, РПЪЧПМСАЭЙК ЧБН ДПВБЧМСФШ, ХДБМСФШ, ОБИПДЙФШ Й РПМХЮБФШ ДПУФХР Л УЕТЧЙУБН. йОЖТБУФТХЛФХТБ ЧТЕНЕОЙ ЧЩРПМОЕОЙС ТБУРПМБЗБЕФУС Ч ФТЕИ НЕУФБИ: Ч УЕТЧЙУЕ РПЙУЛБ, ЛПФПТБС ОБИПДЙФУС Ч УЕФЙ, Ч РПУФБЧЭЙЛБИ ХУМХЗ (ФБЛЙИ ЛБЛ Jini-УПЧНЕУФЙНЩЕ ХУФТПКУФЧБ) Й Ч ЛМЙЕОФБИ. уМХЦВБ РПЙУЛБ СЧМСЕФУС НЕИБОЙЪНПН ГЕОФТБМШОПК ПТЗБОЙЪБГЙЙ ДМС УЙУФЕН, ВБЪЙТХАЭЙИУС ОБ Jini. лПЗДБ Ч УЕФЙ УФБОПЧЙФУС ДПУФХРОЩН ОПЧЩК УЕТЧЙУ, ПО ТЕЗЙУФТЙТХЕФУС Ч УМХЦВЕ РПЙУЛБ. лПЗДБ ЛМЙЕОФ ИПЮЕФ ОБКЙ УМХЦВХ ДМС ЧЩРПМОЕОЙС ЛБЛПК-МЙВП ТБВПФЩ, ПО ЛПОУХМШФЙТХЕФУС Х УМХЦВЩ РПЙУЛБ.
йОЖТПУФТХЛФХТБ ЧТЕНЕОЙ ЧЩРПМОЕОЙС ЙУРПМШЪХЕФ ПДЙО РТПФПЛПМ УЕФЕЧПЗП ХТПЧОС, ОБЪЩЧБЕНЩК ПВОБТХЦЕОЙЕ(discovery) Й ДЧБ РТПФПЛПМБ ПВЯЕЛФОПЗП ХТПЧОС, ОБЪЩЧБЕНЩЕ ПВЯЕДЙОЕОЙЕ(join) Й РПЙУЛ(lookup). пВОБТХЦЕОЙЕ РПЪЧПМСЕФ ЛМЙЕОФБН Й УМХЦВБН ПВОБТХЦЙФШ УМХЦВХ РПЙУЛБ. пВЯЕДЙОЕОЙЕ РПЪЧПМСЕФ УМХЦВБН ТЕЗЙУФТЙТПЧБФШУС Ч УМХЦВЕ РПЙУЛБ. рПЙУЛ РПЪЧПМСЕФ ЛМЙЕОФХ ПРТБЫЙЧБФШ УЕТЧЙУЩ, Ч РПЙУЛБИ ФЕИ, ЛПФПТЩЕ НПЗХФ РПНПЮШ Ч ДПУФЙЦЕОЙЙ ГЕМЙ.
пВОБТХЦЕОЙЕ ТБВПФБЕФ УМЕДХАЭЙН ПВТБЪПН: РТЕДРПМПЦЙН Х ЧБУ ЕУФШ Jini-УПЧНЕУФЙНЩК ДЙУЛПЧПД, ЛПФПТЩК РТЕДПУФБЧМСЕФ ХУМХЗХ РПУФПСООПЗП ИТБОЕОЙС. лБЛ ФПМШЛП ЧЩ РПДЛМАЮЙФЕ ДЙУЛПЧПД Л УЕФЙ, ПО РПЫМЕФ ПРПЧЕЭЕОЙЕ РТЙУХФУФЧЙС РП УТЕДУФЧПН ЗТХРРПЧПЗП РБЛЕФБ ЮЕТЕЪ ИПТПЫП ЪОБЛПНЩК РПТФ. ч ПРПЧЕЭЕОЙЕ РТЙУХФУФЧЙС ЧЛМАЮБЕФУС IP БДТЕУ Й ОПНЕТ РПТФБ, ЮЕТЕЪ ЛПФПТЩК ДЙУЛПЧПД НПЦЕФ ПВЭБФШУС УП УМХЦВПК РПЙУЛБ.
уЕТЧЙУ РПЙУЛБ УМЕДЙФ ИПТПЫП ЪОБЛПНЩК РПТФ Ч ПЦЙДБОЙЙ РБЛЕФПЧ ПРПЧЕЭЕОЙС РТЙУХФУФЧЙС. лПЗДБ УМХЦВБ РПЙУЛБ РПМХЮБЕФ ПРПЧЕЭЕОЙЕ РТЙУХФУФЧЙС, ПОБ ПФЛТЩЧБЕФ Й ЙОУРЕЛФЙТХЕФ РБЛЕФ. рБЛЕФ УПДЕТЦЙФ ЙОЖПТНБГЙА, ЛПФПТБС РПЪЧПМСЕФ УМХЦВЕ РПЙУЛБ ПРТЕДЕМЙФШ ДПМЦОБ МЙ ПОБ УЧСЪБФШУС У ПФРТБЧЙФЕМЕН РБЛЕФБ. еУМЙ ЬФП ФБЛ, ПОБ УПЕДЙОСЕФУС У ПФРТБЧЙФЕМЕН ОБРТСНХА, УПЪДБЧБС TCP УПЕДЙОЕОЙЕ РП IP БДТЕУХ Й ОПНЕТХ РПТФБ, РПМХЮЕООПНХ ЙЪ РБЛЕФБ. йУРПМШЪХС RMI, УЕТЧЙУ РПЙУЛБ РПУЩМБЕФ Л ЙУФПЮОЙЛХ РБЛЕФБ ПВЯЕЛФ, ОБЪЩЧБЕНЩК ТЕЗЙУФТБФПТПН. оБЪОБЮЕОЙЕ ПВЯЕЛФБ-ТЕЗЙУФТБФПТБ ЪБЛМАЮБЕФУС Ч УПДЕКУФЧЙЙ ВХДХАЭЕНХ ЧЪБЙНПДЕКУФЧЙА УП УМХЦВПК РПЙУЛБ. чЩЪЩЧБС НЕФПДЩ ЬФПЗП ПВЯЕЛФБ ПФРТБЧЙФЕМШ ПРПЧЕЭБАЭЕЗП РБЛЕФБ НПЦЕФ ЧЩРПМОЙФШ ПВЯЕДЙОЕОЙЕ Й РПЙУЛ УМХЦВЩ РПЙУЛБ. ч УМХЮБЕ ДЙУЛПЧПДБ, УМХЦВБ РПЙУЛБ ДПМЦОБ УПЪДБФШ TCP УПЕДЙОЕОЙЕ У ДЙУЛПЧПДПН Й РПУМБФШ ЕНХ ПВЯЕЛФ-ТЕЗЙУФТБФПТ, ЮЕТЕЪ ЛПФПТЩК ДЙУЛПЧПД УНПЗ ВЩ ЪБТЕЗЙУФТЙТПЧБФШ УЧПА УМХЦВХ РПУФПСООПЗП ИТБОЕОЙС ЮЕТЕЪ РТПГЕУ ПВЯЕДЙОЕЙС.
лБЛ ФПМШЛП РПУФБЧЭЙЛ УЕТЧЙУБ РПМХЮБЕФ ПВЯЕЛФ-ТЕЗЙУФТБФПТ - ЛПОЕЮОЩК РТПДХЛФ ТЕЗЙУФТБГЙЙ - ПО ЗПФПЧ ЧЩРПМОЙФШ ПВЯЕДЙОЕОЙЕ — УФБФШ ЮБУФША ЖЕДЕТБГЙЙ УЕТЧЙУПЧ, ЪБТЕЗЙУФТЙТПЧБООЩИ Ч УМХЦВЕ РПЙУЛБ. юФПВЩ ЧЩРПМОЙФШ ПВЯЕДЙОЕОЙЕ, РПУФБЧЭЙЛ УЕТЧЙУБ ЧЩЪЩЧБЕФ НЕФПД register( ), РТЙОБДМЕЦБЭЙК ПВЯЕЛФХ-ТЕЗЙУФТБФПТХ, РЕТЕДБЧБС Ч ЛБЮЕУФЧЕ РБТБНЕФТБ ПВЯЕЛФ, ОБЪЧБЕНЩК ЬМЕНЕОФ УМХЦВЩ, СЧМСАЭЙКУС РБЛЕФПН ПВЯЕЛФПЧ, ПРЙУЩЧБАЭЙИ УМХЦВХ. нЕФПД register( ) РПУЩМБЕФ ЛПРЙА ЬМЕНЕОФБ УМХЦВЩ УЕТЧЙУХ РПЙУЛБ, ЗДЕ ИТБОЙФУС ЬПМЕНЕОФ УМХЦВЩ. лПЗДБ ЬФП ВХДЕФ ЧЩРПМОЕОП, РПУФБЧЭЙЛ УЕТЧЙУБ ЪБЧЕТЫБЕФ РТПГЕУУ ПВЯЕДЙОЕОЙС: ЕЗП УМХЦВБ УФБОПЧЙФУС ЪБТЕЗЙУФТЙТПЧБООПК Ч УМХЦВЕ РПЙУЛБ.
ьМЕНЕОФ УМХЦВЩ СЧМСЕФУС ЛПОФЕОЕТПН ДМС ОЕУЛПМШЛЙИ ПВЯЕЛФПЧ, ЧЛМАЮБС ПВЯЕЛФ, ОБЪЩЧБЕНЩК ПВЯЕЛФПН УЕТЧЙУБ, ЛПФПТЩК НПЦЕФ ВЩФШ ЙУРПМШЪПЧБО ЛМЙЕОФПН ДМС ЧЪБЙНПДЕКУФЧЙС УП УМХЦВПК. ьМЕНЕОФ УМХЦВЩ ФБЛЦЕ НПЦЕФ ЧЛМАЮБФШ МАВПЕ ЮЙУМП БФТЙВХФПЧ, ЛПФПТЩЕ НПЗХФ ВЩФШ МАВЩН ПВЯЕЛФПН. оЕЛПФТЩЕ ЙЪ РПФЕОГЙБМШОЩИ БФТЙВХФПЧ - ЬФП ЙЛПОЛЙ, ЛМБУУЩ, ПВЕУРЕЮЙЧБАЭЙЕ GUI ДМС УМХЦВЩ Й ПВЯЕЛФЩ, ЛПФПТЩЕ ДБАФ ВПМЕЕ РПДТПВОХА ЙОЖПТНБГЙА П УМХЦВЕ.
пВЯЕЛФЩ УМХЦВЩ ПВЩЮОП ТЕБМЙЪПЧБОЩ ПДОЙН ЙМЙ ОЕУЛПМШЛЙНЙ ЙОФЕТЖЕКУБНЙ, ЮЕТЕЪ ЛПФПТЩЕ ЛМЙЕОФЩ ЧЪБЙНПДЕКУФЧХАФ УП УМХЦВПК. оБРЙНЕТ, УМХЦВБ РПЙУЛБ СЧМСЕФУС Jini УМХЦВПК, Б УППФЧЕФУФЧХАЭЙК ПВЯЕЛФ УМХЦВЩ - ЬФП ПВЯЕЛФ-ТЕЗЙУФТБФПТ. нЕФПД register( ), ЧЩЪЩЧБЕНЩК РПУФБЧЭЙЛПН УМХЦВЩ ЧП ЧТЕНС ПВЯЕДЙОЕОЙС, ПВЯСЧМСЕФУС Ч ЙОФЕТЖЕКУЕ ServiceRegistrar (ЮМЕО РБЛЕФБ net.jini.core.lookup), ЛПФПТЩК ТЕБМЙЪХАФ ЧУЕ ПВЯЕЛФЩ-ТЕЗЙУФТБФПТЩ. лМЙЕОФЩ Й РПУФБЧЭЙЛЙ ХУМХЗ ПВЭБАФУС УП УМХЦВПК РПЙУЛБ ЮЕТЕЪ ПВЯЕЛФ-ТЕЗЙУФТБФПТ, ЧЩЪЩЧБС НЕФПДЩ, ПВЯСЧМЕООЩЕ Ч ЙОФЕТЖЕКУЕ ServiceRegistrar. фПЮОП ФБЛ ЦЕ, ДЙУЛПЧПД ВХДЕФ РТЕДПУФБЧМСФШ ПВЯЕЛФ УМХЦВЩ, ЛПФПТЩК ТЕБМЙЪХЕФ ОЕЛПФПТЩК ИПТПЫП ЙЪЧЕУФОЩК ЙОФЕТЖЕКУ УМХЦВЩ ИТБОЕОЙС. лМЙЕОФЩ ВХДХФ ЙУЛБФШ Й ЧЪБЙНПДЕКУФЧПЧБФШ У ДЙУЛПЧПДПН РПУТЕДУФЧПН ЙОФЕТЖЕКУБ УМХЦВЩ ИТБОЕОЙС.
рПУМЕ ФПЗП, ЛБЛ УМХЦВБ ЪБТЕЗЙУФТЙТПЧБОБ Ч УМХЦВЕ РПЙУЛБ Ч РТПГЕУУЕ ПВЯЕДЙОЕОЙС, ЬФПФ РТПГЕУУ УФБОПЧЙФУС ДПУФХРОЩН ДМС ЙУРПМШЪПЧБОЙС ЛМЙЕОФБНЙ, ЛПФПТЩЕ ЙЭХФ ФБЛХА УМХЦВХ. дМС РПУФТПЕОЙС ТБУРТЕДЕМЕООПК УЙУФЕНЩ УМХЦВ, ЛПФПТЩЕ ТБВПФБАФ УПЧНЕУФОП ДМС ЧЩРПМОЕОЙС ОЕЛПФПТПК ЪБДБЮЙ, ЛМЙЕОФ ДПМЦЕО ОБКФЙ Й РТЙЧМЕЮШ Ч РПНПЫШ ПРТЕДЕМЕООЩЕ УМХЦВЩ. дМС ОБИПЦДЕОЙС УМХЦВ ЛМЙЕОФ ПРТБЫЙЧБЕФ УМХЦВХ РПЙУЛБ Ч РТПГЕУУЕ, ОБЪЩЧБЕННП РПЙУЛПН.
дМС ЧЩРПМОЕОЙС РПЙУЛБ, ЛМЙЕОФ ЪБДЕКУФЧХЕФ НЕФПД lookup( ) ПВЯЕЛФБ-ТЕЗЙУФТБФПТБ. (лМЙЕОФ, ФБЛПК ЛБЛ РПУФБЧЭЙЛ УМХЦВЩ, РПМХЮБЕФ ПВЯЕЛФ-ТЕЗЙУФТБФПТ Ч РТПГЕУУЕ ПВОБТХЦЕОЙС, ПРЙУБООПН ТБОЕЕ.) лМЙЕОФ РЕТЕДБЕФ Ч ЛБЮЕУФЧЕ БТЗХНЕОФБ НЕФПДБ lookup( ) ЫБВМПО УМХЦВЩ - ПВЯЕЛФ, СЧМСАЭЙКУС ЛТЙФЕТЙЕН РПЙУЛБ РТЙ ПРТПУЕ. ыБВМПО УМХЦВЩ НПЦЕФ ЧЛМАЮБФШ УУЩМЛЙ ОБ НБУУЙЧ ПВЯЕЛФПЧ ФЙРБ Class. ьФЙ ПВЯЕЛФЩ ФЙРБ Class ХЛБЪЩЧБАФ ЙЭХЭЕК УМХЦВЕ ФЙР (ЙМЙ ФЙРЩ) Java ПВЯЕЛФБ УМХЦВЩ, ФТЕВХЕНЩЕ ЛМЙЕОФХ. ыБВМПО УМХЦВЩ ФБЛЦЕ НПЦЕФ ЧЛМАЮБФШ ID УМХЦВЩ, ЛПФПТЩК ХОЙЛБМШОП ЙДЕОФЙЖЙГЙТХЕФ УМХЦВХ Й БФТЙВХФЩ, ЛПФПТЩЕ ФПЮОП ДПМЦОЩ УППФЧЕФУФЧПЧБФШ БФТЙВХФБН, ЪБЗТХЦБЕНЩН РПУФБЧЭЙЛПН УМХЦВЩ Ч ЬМЕНЕОФ УМХЦВЩ. ыБВМПО УМХЦВЩ ФБЛЦЕ НПЦЕФ УПДЕТЦБФШ РПДУФБОПЧЛЙ МС МАВПЗП ЙЪ ЬФЙИ РПМЕК. оБРТЙНЕТ, РПДУФБОПЧЛЙ Ч РПМЕ ID УМХЦВЩ ВХДЕФ УПЧРБДБФШ У МАВЩН ID УМХЦВЩ. НЕФПД lookup( ) РПУЩМБЕФ ЫБВМПО УМХЦВЩ УМХЦВЕ РПЙУЛБ, ЛПФПТБС ЧЩРПМОСЕФ ПРТПУ Й РПУЩМБЕФ ОБЪБД ОПМШ МАВПНХ УППФЧЕФУФЧХАЭЕНХ ПВЯЕЛФХ УМХЦВЩ. лМЙЕОФ РПМХЮБЕФ УУЩМЛХ ОБ УПЧРБЧЫЙК ПВЯЕЛФ ПВУМХЦЙЧБОЙС Ч ЛБЮЕУФЧЕ ЧПЪЧТБЭБЕНПЗП ЪОБЮЕОЙС НЕФПДБ lookup( ).
ч ПВЭЕН УМХЮБЕ ЛМЙЕОФ ЙЭЕФ УЕТЧЙУ РП ФЙРХ Java, ПВЩЮОП ЬФП ЙОФЕТЖЕКУ. оБРТЙНЕТ, ЕУМЙ ЛМЙЕОФХ ОЕПВИПДЙНП ЙУРПМШЪПЧБФШ РТЙОФЕТ, ПО ДПМЦЕО УТБЧОЙЧБФШ ЫБВМПО УЕТЧЙУБ, ЮФПВЩ ПО ЧЛМАЮБМ ПВЯЕЛФ Class У ИПТПЫП ЪОБЛПНЩН ЙОФЕТЖЕКУПН УМХЦВ РЕЮБФЙ. чУЕ УМХЦВЩ РЕЮБФЙ ДПМЦОЩ ТЕБМЙЪПЧЩЧБФШ ЬФПФ ИПТПЫП ЪОБЛПНЩК ЙОФЕТЖЕКУ. уМХЦВБ РПЙУЛБ ДПМЦОБ ЧПЪЧТБЭБФШ ПВЯЕЛФ УМХЦВЩ (ЙМЙ ПВЯЕЛФЩ), ЛПФПТЩЕ ТЕБМЙЪХАФ ЬФПФ ЙОФЕТЖЕКУ. бФТЙВХФЩ НПЗХФ ЧЛМАЮБФШУС Ч ЫБВМПО УМХЦВЩ, ЮФПВЩ УХЪЙФШ ЮЙУМП УПЧРБДЕОЙК ДМС РПЙУЛБ, ПУОПЧЩЧБАЭЕЗПУС ОБ ФЙРЕ. лМЙЕОФ ДПМЦЕО ЙУРПМШЪПЧБФШ УМХЦВХ РЕЮБФЙ, ЧЩЪЩЧБС НЕФПДЩ ИПТПЫП ЪОБЛПНПЗП ЙОФЕТЖЕКУБ УМХЦВЩ ПВУМХЦЙЧБАЭЕЗП ПВЯЕЛФБ.
бТИЙФЙЛФХТБ Jini РТЕЧОПУЙФ ПВЯЕЛФОП-ПТЙЕОФЙТПЧБООПЕ РТПЗТБННЙТПЧБОЙЕ Ч УЕФШ, РПЪЧПМСС РПМХЮБФШ ДПУФХР Л УЕФЕЧЩН УМХЦВБН ЙУРПМШЪХС ПДОП ЙЪ ЖХОДБНЕОФБМШОЩИ УЧПКУФЧ ПВЯЕЛФПЧ: ТБЪДЕМЕОЙЕ ЙОФЕТЖЕКУБ Й ТЕБМЙЪБГЙЙ. оБРТЙНЕТ, ПВУМХЦЙЧБАЭЙК ПВЯЕЛФ НПЦЕФ РТЕДПУФБЧЙФШ ЛМЙЕОФХ ДПУФХР Л УМХЦВЕ НОПЗЙНЙ УРПУПВБНЙ. пВЯЕЛФ НПЦЕФ ОБ УБНПН ДЕМЕ РТЕДУФБЧМСФШ ГЕМХА УМХЦВХ, ЛПФПТБС ЪБЗТХЦБЕФУС ЛМЙЕОФПН ЧП ЧТЕНС РПЙУЛБ, Б ЪБФЕН ЧЩРПМОСЕФУС МПЛБМШОП. у ДТХЗПК УФПТПОЩ, ПВУМХЦЙЧБАЭЙК ПВЯЕЛФ НПЦЕФ МЙЫШ ЪБНЕЭБФШ ХДБМЕООХА УМХЦВХ. ъБФЕН, ЛПЗДБ ЛМЙЕОФ ЧЩЪЩЧБЕФ НЕФПДЩ ПВУМХЦЙЧБАЭЕЗП ПВЯЕЛФБ, ПО РПУЩМБЕФ ЪБРТПУ РП УЕФЙ Л УЕТЧЕТХ, ЛПФПТЩК ЧЩРПМОСЕФ ТЕБМШОХА ТБВПФХ. фТЕФЙК ЧБТЙБОФ - ЬФП МПЛБМШОЩК ПВУМХЦЙЧБАЭЙК ПВЯЕЛФ Й ХДБМЕООЩК УЕТЧЕТ, ЛБЦДЩК ЙЪ ЛПФПТЩИ ЧЩРПМОСЕФ ЮБУФШ ТБВПФЩ.
пДЙО ЧБЦОЩК ЧЩЧПД БТИЙФЕЛФХТЩ Jini УПУФПЙФ Ч ФПН, ЮФП УЕФЕЧПК РТПФПЛПМ, ЙУРПМШЪХЕНЩК ДМС ПВЭЕОЙС НЕЦДХ РТЕДУФБЧЙФЕМЕН ПВУМХЦЙЧБАЭЕЗП ПВЯЕЛФБ Й ХДБМЕООПК УМХЦВПК ОЕ ДПМЦЕО ВЩФШ ЙЪЧЕУФЕО ЛМЙЕОФХ. лБЛ РПЛБЪБОП ОБ РТЙЧЕДЕООПН ОЙЦЕ ТЙУХОЛЕ, УЕФЕЧПК РТПФПЛПМ СЧМСЕФУС ЮБУФША ТЕБМЙЪБГЙЙ УМХЦВЩ. ьФПФ РТПФПЛПМ ЧЩТБВБФЩЧБЕФУС ЗМБЧОЩН ПВТБЪПН ТБЪТБВПФЮЙЛПН УМХЦВЩ. лМЙЕОФ НПЦЕФ ПВЭБФШУС УП УМХЦВПК РП ЬФПНХ РТПФПЛПМХ, РПУЛПМШЛХ УМХЦВБ ЧЧПДЙФ ОЕЛПФПТЩК УЧПК ЛПД (Ч ПВЯЕЛФЕ УМХЦВЩ) Ч ЛМЙЕОФУЛПЕ БДТЕУОПЕ РТПУФТБОУФЧП. чЧЕДЕООЩК ПВУМХЦЙЧБАЭЙК ПВЯЕЛФ ДПМЦЕО УЧСЪЩЧБФШУС УП УМХЦВПК ЮЕТЕЪ RMI, CORBA, DCOM, ОЕЛПФПТЩК УНЕЫБООЩК РТПФПЛПМ, РПУФТПЕООЩК ОБ УПЛЕФБИ Й РПФПЛБИ, ЙМЙ ЛБЛ-ФП ЕЭЕ. лМЙЕОФХ РТПУФП ОЕ ОХЦОП ЪБВПФЙФУС П УЕФЕЧПН РТПФПЛПМЕ, РПУЛПМШЛХ ПО НПЦЕФ ПВЭБФШУС У ИПТПЫП ЪОБЛПНЩН ЙОФЕТЖЕКУПН, ТЕБМЙЪПЧБООПН ПВУМХЦЙЧБАЭЙН ПВЯЕЛФПН. пВУМХЦЙЧБАЭЙК ПВЯЕЛФ ЪБВПФЙФУС П ЧУЕИ ОЕПВИПДЙНЩИ УЕФЕЧЩИ ЛПННХОЙЛБГЙСИ.
лМЙЕОФ ПВЭБЕФУС У УЕТЧЕТПН ЮЕТЕЪ ИПТПЫП ЪОБЛПНЩК ЙОФЕТЖЕКУ
Jini РТПВХЕФ РПДОСФШ ХТПЧЕОШ БВУФТБЛГЙЙ ДМС РТПЗТБННЙТПЧБОЙС ТБУРТЕДЕМЕООЩИ УЙУФЕН У ХТПЧОС УЕФЕЧПЗП РТПФПЛПМБ ДП ХТПЧОС ЙОФЕТЖЕКУПЧ ПВЯЕЛФПЧ. рТЙ ВЩУФТПН ТБУРТПУФТБОЕОЙЙ ЧУФТПЕООЩИ ХУФТПКУФЧ, РПДУПЕДЙОЕООЩИ Л УЕФЙ, НОПЗЙЕ ЮБУФЙ ТБУРТЕДЕМЕООПК УЙУФНЩ НПЗХФ РПУФБЧМСФШУС ТБЪМЙЮОЩНЙ РТПЙЪЧПДЙФЕМСНЙ. Jini ДЕМБЕФ ОЕПВСЪБФЕМШОЩН ДМС РПУФБЧЭЙЛПЧ РТЙИПДЙФШ Л УПЗМБЫЕОЙА ОБ ХТПЧОЕ УЕФЕЧПЗП РТПФПЛПМБ, ЛПФПТЩК РПЪЧПМСЕФ ХУФТПКУФЧБН ЧЪБЙНПДЕКУФЧПЧБФШ. чНЕУФП ЬФПЗП РТПЙЪЧПДЙФЕМЙ ДПМЦОЩ РТЙОСФШ ЙОФЕТЖЕКУЩ Java, ЮЕТЕЪ ЛПФПТЩЕ ЙИ ХУФТПКУФЧП УНПЕФ ЧЪБЙНПДЕКУФЧПЧБФШ. рТПГЕУУ ПВОБТХЦЕОЙС, РТЙУПЕДЙОЕОЙС Й РПЙУЛБ ПВЕУРЕЮЙЧБЕФУС ЙОЖТБУФТХЛФХТПК Jini ЧТЕНЕОЙ ЧЩРПМОЕОЙС, РПЪЧПМСАЭЕК ХУФТПКУФЧБН ОБИПДЙФШ ДТХЗ ДТХЗБ Ч УЕФЙ. лБЛ ФПМШЛП ПОЙ ОБКДХФ ДТХЗ ДТХЗБ, ХУФТПКУЧФБ НПЗХФ ПВЭБФШУС ДТХЗ У ДТХЗПН РПУТЕДУФЧБН Java ЙОФЕТЖЕКУПЧ.
оБТСДХ У Jini ДМС МПЛБМШОЩИ УЕФЕЧЩИ ХУФТПКУФЧ, ЬФБ ЗМБЧБ ЧЧЕМБ ОЕЛПФПТЩЕ, ОП ОЕ ЧУЕ, ЛПНРПОЕОФЩ, ЛПФПТЩЕ Sun ОБЪЩЧБЕФ J2EE: Java 2 Enterprise Edition. гЕМША J2EE СЧМСЕФУС РПУФТПЕОЙЕ НОПЦЕУФЧБ ЙОУФТХНЕОФПЧ, ЛПФПТЩЕ РПЪЧПМСФ Java ТБЪТБВПФЮЙЛБН УФТПЙФШ РТЙМПЦЕОЙС, ПУОПЧЩЧБАЭЙЕУС ОБ УЕТЧЕТЕ, НОПЗП ВЩУФТЕЕ Й ДЕМБФШ ЙИ РМБФЖПТНПОЕЪБЧЙУЙНЩНЙ. уФТПЙФШ ФБЛЙЕ РТЙМПЦЕОЙС ОЕ ФПМШЛП УМПЦОП Й ДПМЗП, ОП ПУПВЕООП УМПЦОП УФТПЙФШ ЙИ ФБЛ, ЮФПВЩ ПОЙ МЕЗЛП РЕТЕОПУЙМЙУШ ОБ ДТХЗЙЕ РМБФЖПТНЩ, Б ФБЛЦЕ УПИТБОЙФШ ВЙЪОЕУ-МПЗЙЛХ, ПФДЕМЙЧ ЕЕ ПФ МЕЦБЭЙИ Ч ПУОПЧЕ ДЕФБМЕК ТЕБМЙЪБГЙЙ. J2EE ПВЕУРЕЮЙЧБЕФ ТБВПЮЕЕ РТПУФТБОУФЧП, РПНПЗБАЭЕЕ Ч УПЪДБОЙЙ РТЙМПЦЕОЙК, ТБВПФБАЭЙИ У УЕТЧЕТПН, ФБЛЙЕ РТЙМПЦЕОЙС ФЕРЕТШ Ч НПДЕ, Й РПФТЕВОПУФШ Ч ОЙИ ВХДЕФ ЧПЪТБУФБФШ.
тЕЫЕОЙС ДМС ЧЩВТБООЩИ ХРТБЧЦОЕОЙК НПЗХФ ВЩФШ ОБКДЕОЩ Ч ЬМЕЛФТПООПК ДПЛХНЕОФБГЙЙ The Thinking in Java Annotated Solution Guide, ДПУФХРОПК ЪБ НБМХА РМБФХ ОБ www.BruceEckel.com.
[72] ьФП ПЪОБЮБЕФ ВПМЕЕ ЮЕФЩТЕИ НЙММЙБТДПЧ ЮЙУЕМ, ЛПФПТЩЕ РПСЧМСАФУС РПЧФПТОП. оПЧЩК УФБОДБТФ IP БДТЕУПЧ ВХДЕФ ЙУРПМШЪПЧБФШ 128-ВЙФПЧЩК ОПНЕТ, ЛПФПТЩК ДПМЦЕО РТПЙЪЧПДЙФШ ДПУФБФПЮОП ХОЙЛБМШОЩИ IP БДТЕУПЧ Ч ПВПЪТЙНПН ВХДХАЭЕН.
[73] уПЪДБОП Dave Bartlett.
[74] Dave Bartlett РПНПЗБМ Ч ТБЪТБВПФЛЕ ЬФПЗП НБФЕТЙБМБ, Б ФБЛЦЕ ТБЪДЕМБ JSP.
[75] зМБЧОБС ДПЗНБ ьЛУТЕНБМШОПЗП рТПЗТБННЙТПЧБОЙС (Extreme Programming (XP)). уНПФТЙФЕ www.xprogramming.com.
[76] нОПЗЙЕ ЛМЕФЛЙ НПЪЗБ ХНЙТБАФ Ч БЗПОЙЙ РТЙ ПВОБТХЦЕОЙЙ ЬФПК ЙОЖПТНБГЙЙ.
[77] ьФПФ ТБЪДЕМ ЧЩЫЕМ РТЙ УПДЕКУФЧЙЙ Robert Castaneda У РПНПЫША Dave Bartlett.
[78] ьФПФ ТБЪДЕМ ЧЩЫЕМ РТЙ УПДЕКУФЧЙЙ Bill Venners (www.artima.com).